 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeptide-GPT: Generative Design of Peptides using Generative Pre-trained Transformers and Bio-informatic Supervision
Oct 25, 2024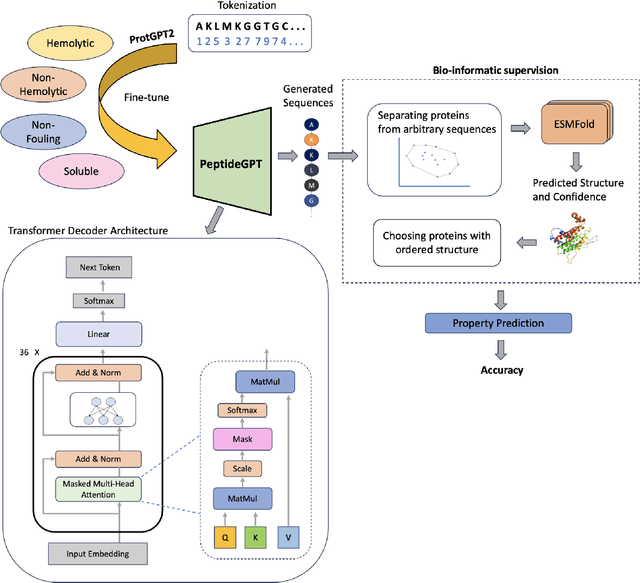

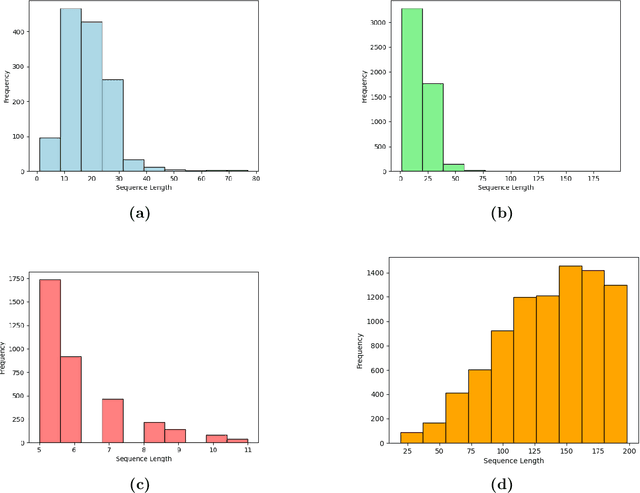

In recent years, natural language processing (NLP) models have demonstrated remarkable capabilities in various domains beyond traditional text generation. In this work, we introduce PeptideGPT, a protein language model tailored to generate protein sequences with distinct properties: hemolytic activity, solubility, and non-fouling characteristics. To facilitate a rigorous evaluation of these generated sequences, we established a comprehensive evaluation pipeline consisting of ideas from bioinformatics to retain valid proteins with ordered structures. First, we rank the generated sequences based on their perplexity scores, then we filter out those lying outside the permissible convex hull of proteins. Finally, we predict the structure using ESMFold and select the proteins with pLDDT values greater than 70 to ensure ordered structure. The properties of generated sequences are evaluated using task-specific classifiers - PeptideBERT and HAPPENN. We achieved an accuracy of 76.26% in hemolytic, 72.46% in non-hemolytic, 78.84% in non-fouling, and 68.06% in solubility protein generation. Our experimental results demonstrate the effectiveness of PeptideGPT in de novo protein design and underscore the potential of leveraging NLP-based approaches for paving the way for future innovations and breakthroughs in synthetic biology and bioinformatics. Codes, models, and data used in this study are freely available at: https://github.com/aayush-shah14/PeptideGPT.
Multi-Peptide: Multimodality Leveraged Language-Graph Learning of Peptide Properties
Jul 02, 2024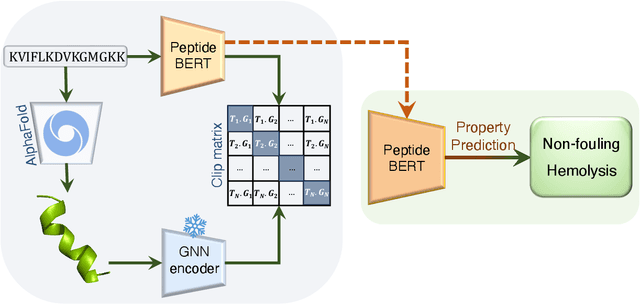

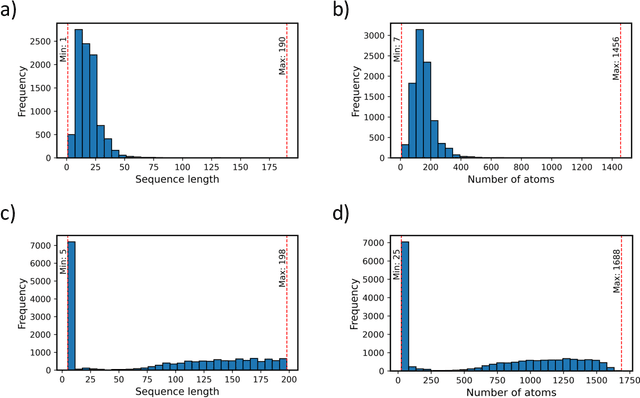
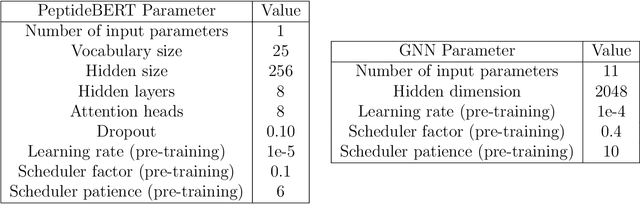
Peptides are essential in biological processes and therapeutics. In this study, we introduce Multi-Peptide, an innovative approach that combines transformer-based language models with Graph Neural Networks (GNNs) to predict peptide properties. We combine PeptideBERT, a transformer model tailored for peptide property prediction, with a GNN encoder to capture both sequence-based and structural features. By employing Contrastive Language-Image Pre-training (CLIP), Multi-Peptide aligns embeddings from both modalities into a shared latent space, thereby enhancing the model's predictive accuracy. Evaluations on hemolysis and nonfouling datasets demonstrate Multi-Peptide's robustness, achieving state-of-the-art 86.185% accuracy in hemolysis prediction. This study highlights the potential of multimodal learning in bioinformatics, paving the way for accurate and reliable predictions in peptide-based research and applications.
AlloyBERT: Alloy Property Prediction with Large Language Models
Mar 28, 2024The pursuit of novel alloys tailored to specific requirements poses significant challenges for researchers in the field. This underscores the importance of developing predictive techniques for essential physical properties of alloys based on their chemical composition and processing parameters. This study introduces AlloyBERT, a transformer encoder-based model designed to predict properties such as elastic modulus and yield strength of alloys using textual inputs. Leveraging the pre-trained RoBERTa encoder model as its foundation, AlloyBERT employs self-attention mechanisms to establish meaningful relationships between words, enabling it to interpret human-readable input and predict target alloy properties. By combining a tokenizer trained on our textual data and a RoBERTa encoder pre-trained and fine-tuned for this specific task, we achieved a mean squared error (MSE) of 0.00015 on the Multi Principal Elemental Alloys (MPEA) data set and 0.00611 on the Refractory Alloy Yield Strength (RAYS) dataset. This surpasses the performance of shallow models, which achieved a best-case MSE of 0.00025 and 0.0076 on the MPEA and RAYS datasets respectively. Our results highlight the potential of language models in material science and establish a foundational framework for text-based prediction of alloy properties that does not rely on complex underlying representations, calculations, or simulations.
PeptideBERT: A Language Model based on Transformers for Peptide Property Prediction
Aug 28, 2023Recent advances in Language Models have enabled the protein modeling community with a powerful tool since protein sequences can be represented as text. Specifically, by taking advantage of Transformers, sequence-to-property prediction will be amenable without the need for explicit structural data. In this work, inspired by recent progress in Large Language Models (LLMs), we introduce PeptideBERT, a protein language model for predicting three key properties of peptides (hemolysis, solubility, and non-fouling). The PeptideBert utilizes the ProtBERT pretrained transformer model with 12 attention heads and 12 hidden layers. We then finetuned the pretrained model for the three downstream tasks. Our model has achieved state of the art (SOTA) for predicting Hemolysis, which is a task for determining peptide's potential to induce red blood cell lysis. Our PeptideBert non-fouling model also achieved remarkable accuracy in predicting peptide's capacity to resist non-specific interactions. This model, trained predominantly on shorter sequences, benefits from the dataset where negative examples are largely associated with insoluble peptides. Codes, models, and data used in this study are freely available at: https://github.com/ChakradharG/PeptideBERT