 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Structure-Function Relationship: A Kernel-PCA Approach for Reaction Coordinate Identification
Mar 24, 2025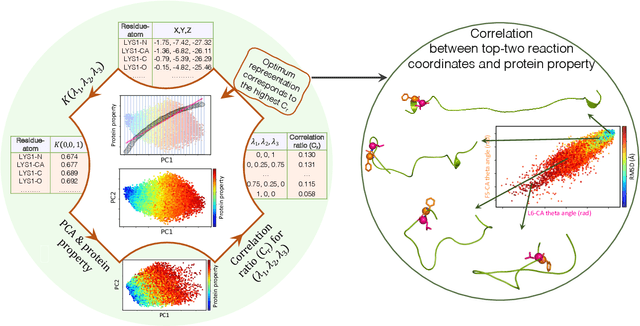



In this study, we propose a Kernel-PCA model designed to capture structure-function relationships in a protein. This model also enables ranking of reaction coordinates according to their impact on protein properties. By leveraging machine learning techniques, including Kernel and principal component analysis (PCA), our model uncovers meaningful patterns in high-dimensional protein data obtained from molecular dynamics (MD) simulations. The effectiveness of our model in accurately identifying reaction coordinates has been demonstrated through its application to a G protein-coupled receptor. Furthermore, this model utilizes a network-based approach to uncover correlations in the dynamic behavior of residues associated with a specific protein property. These findings underscore the potential of our model as a powerful tool for protein structure-function analysis and visualization.
Multi-Peptide: Multimodality Leveraged Language-Graph Learning of Peptide Properties
Jul 02, 2024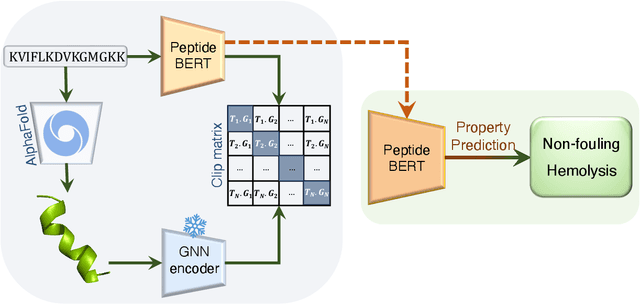

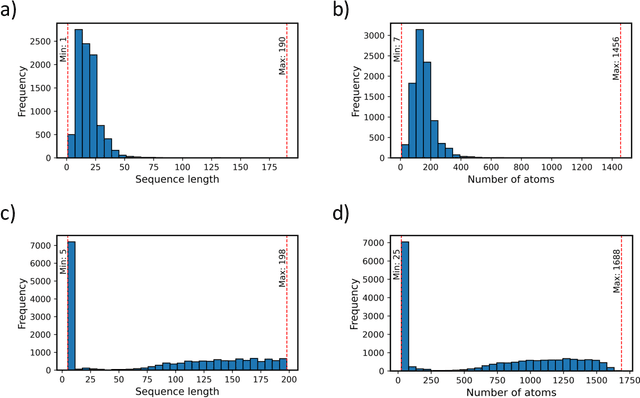
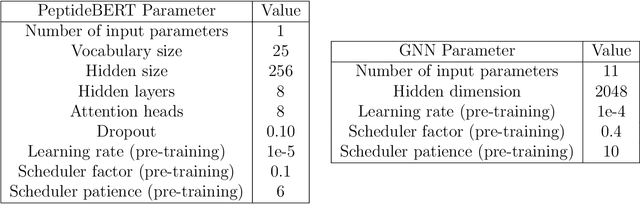
Peptides are essential in biological processes and therapeutics. In this study, we introduce Multi-Peptide, an innovative approach that combines transformer-based language models with Graph Neural Networks (GNNs) to predict peptide properties. We combine PeptideBERT, a transformer model tailored for peptide property prediction, with a GNN encoder to capture both sequence-based and structural features. By employing Contrastive Language-Image Pre-training (CLIP), Multi-Peptide aligns embeddings from both modalities into a shared latent space, thereby enhancing the model's predictive accuracy. Evaluations on hemolysis and nonfouling datasets demonstrate Multi-Peptide's robustness, achieving state-of-the-art 86.185% accuracy in hemolysis prediction. This study highlights the potential of multimodal learning in bioinformatics, paving the way for accurate and reliable predictions in peptide-based research and applications.
GPCR-BERT: Interpreting Sequential Design of G Protein Coupled Receptors Using Protein Language Models
Oct 30, 2023With the rise of Transformers and Large Language Models (LLMs) in Chemistry and Biology, new avenues for the design and understanding of therapeutics have opened up to the scientific community. Protein sequences can be modeled as language and can take advantage of recent advances in LLMs, specifically with the abundance of our access to the protein sequence datasets. In this paper, we developed the GPCR-BERT model for understanding the sequential design of G Protein-Coupled Receptors (GPCRs). GPCRs are the target of over one-third of FDA-approved pharmaceuticals. However, there is a lack of comprehensive understanding regarding the relationship between amino acid sequence, ligand selectivity, and conformational motifs (such as NPxxY, CWxP, E/DRY). By utilizing the pre-trained protein model (Prot-Bert) and fine-tuning with prediction tasks of variations in the motifs, we were able to shed light on several relationships between residues in the binding pocket and some of the conserved motifs. To achieve this, we took advantage of attention weights, and hidden states of the model that are interpreted to extract the extent of contributions of amino acids in dictating the type of masked ones. The fine-tuned models demonstrated high accuracy in predicting hidden residues within the motifs. In addition, the analysis of embedding was performed over 3D structures to elucidate the higher-order interactions within the conformations of the receptors.
PeptideBERT: A Language Model based on Transformers for Peptide Property Prediction
Aug 28, 2023Recent advances in Language Models have enabled the protein modeling community with a powerful tool since protein sequences can be represented as text. Specifically, by taking advantage of Transformers, sequence-to-property prediction will be amenable without the need for explicit structural data. In this work, inspired by recent progress in Large Language Models (LLMs), we introduce PeptideBERT, a protein language model for predicting three key properties of peptides (hemolysis, solubility, and non-fouling). The PeptideBert utilizes the ProtBERT pretrained transformer model with 12 attention heads and 12 hidden layers. We then finetuned the pretrained model for the three downstream tasks. Our model has achieved state of the art (SOTA) for predicting Hemolysis, which is a task for determining peptide's potential to induce red blood cell lysis. Our PeptideBert non-fouling model also achieved remarkable accuracy in predicting peptide's capacity to resist non-specific interactions. This model, trained predominantly on shorter sequences, benefits from the dataset where negative examples are largely associated with insoluble peptides. Codes, models, and data used in this study are freely available at: https://github.com/ChakradharG/PeptideBERT