 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\mathbfΦ$-GAN: Physics-Inspired GAN for Generating SAR Images Under Limited Data
Mar 04, 2025Approaches for improving generative adversarial networks (GANs) training under a few samples have been explored for natural images. However, these methods have limited effectiveness for synthetic aperture radar (SAR) images, as they do not account for the unique electromagnetic scattering properties of SAR. To remedy this, we propose a physics-inspired regularization method dubbed $\Phi$-GAN, which incorporates the ideal point scattering center (PSC) model of SAR with two physical consistency losses. The PSC model approximates SAR targets using physical parameters, ensuring that $\Phi$-GAN generates SAR images consistent with real physical properties while preventing discriminator overfitting by focusing on PSC-based decision cues. To embed the PSC model into GANs for end-to-end training, we introduce a physics-inspired neural module capable of estimating the physical parameters of SAR targets efficiently. This module retains the interpretability of the physical model and can be trained with limited data. We propose two physical loss functions: one for the generator, guiding it to produce SAR images with physical parameters consistent with real ones, and one for the discriminator, enhancing its robustness by basing decisions on PSC attributes. We evaluate $\Phi$-GAN across several conditional GAN (cGAN) models, demonstrating state-of-the-art performance in data-scarce scenarios on three SAR image datasets.
ChatReID: Open-ended Interactive Person Retrieval via Hierarchical Progressive Tuning for Vision Language Models
Feb 27, 2025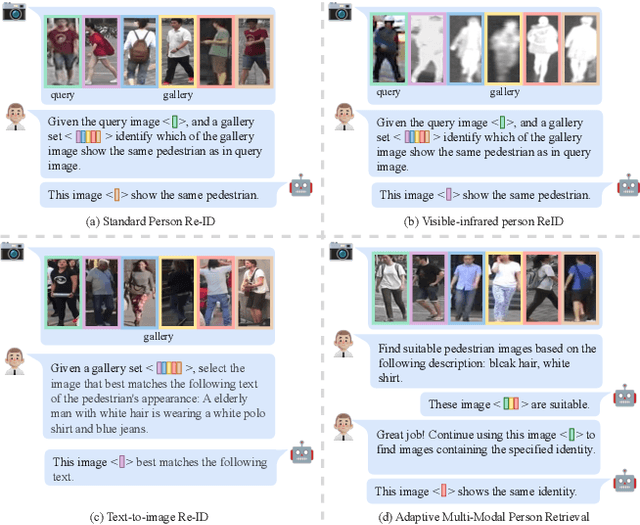
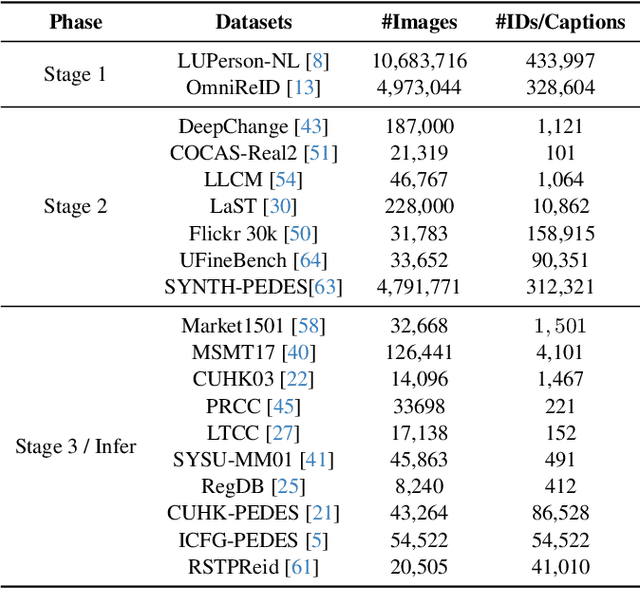
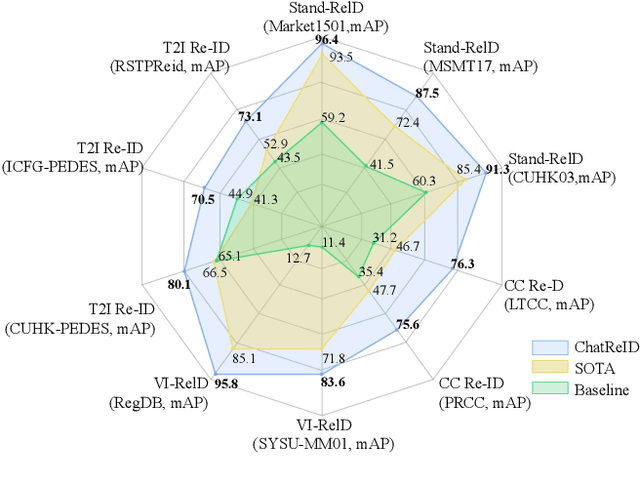
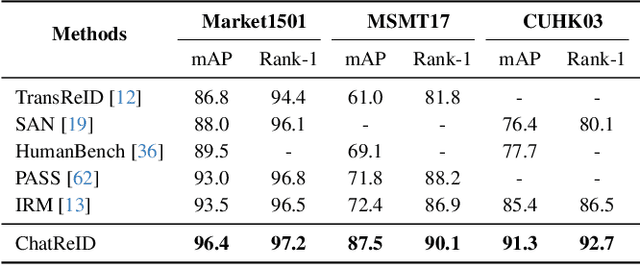
Person re-identification (Re-ID) is a critical task in human-centric intelligent systems, enabling consistent identification of individuals across different camera views using multi-modal query information. Recent studies have successfully integrated LVLMs with person Re-ID, yielding promising results. However, existing LVLM-based methods face several limitations. They rely on extracting textual embeddings from fixed templates, which are used either as intermediate features for image representation or for prompt tuning in domain-specific tasks. Furthermore, they are unable to adopt the VQA inference format, significantly restricting their broader applicability. In this paper, we propose a novel, versatile, one-for-all person Re-ID framework, ChatReID. Our approach introduces a Hierarchical Progressive Tuning (HPT) strategy, which ensures fine-grained identity-level retrieval by progressively refining the model's ability to distinguish pedestrian identities. Extensive experiments demonstrate that our approach outperforms SOTA methods across ten benchmarks in four different Re-ID settings, offering enhanced flexibility and user-friendliness. ChatReID provides a scalable, practical solution for real-world person Re-ID applications, enabling effective multi-modal interaction and fine-grained identity discrimination.
Sustainable Self-evolution Adversarial Training
Dec 03, 2024



With the wide application of deep neural network models in various computer vision tasks, there has been a proliferation of adversarial example generation strategies aimed at deeply exploring model security. However, existing adversarial training defense models, which rely on single or limited types of attacks under a one-time learning process, struggle to adapt to the dynamic and evolving nature of attack methods. Therefore, to achieve defense performance improvements for models in long-term applications, we propose a novel Sustainable Self-Evolution Adversarial Training (SSEAT) framework. Specifically, we introduce a continual adversarial defense pipeline to realize learning from various kinds of adversarial examples across multiple stages. Additionally, to address the issue of model catastrophic forgetting caused by continual learning from ongoing novel attacks, we propose an adversarial data replay module to better select more diverse and key relearning data. Furthermore, we design a consistency regularization strategy to encourage current defense models to learn more from previously trained ones, guiding them to retain more past knowledge and maintain accuracy on clean samples. Extensive experiments have been conducted to verify the efficacy of the proposed SSEAT defense method, which demonstrates superior defense performance and classification accuracy compared to competitors.
fMRI-3D: A Comprehensive Dataset for Enhancing fMRI-based 3D Reconstruction
Sep 17, 2024



Reconstructing 3D visuals from functional Magnetic Resonance Imaging (fMRI) data, introduced as Recon3DMind in our conference work, is of significant interest to both cognitive neuroscience and computer vision. To advance this task, we present the fMRI-3D dataset, which includes data from 15 participants and showcases a total of 4768 3D objects. The dataset comprises two components: fMRI-Shape, previously introduced and accessible at https://huggingface.co/datasets/Fudan-fMRI/fMRI-Shape, and fMRI-Objaverse, proposed in this paper and available at https://huggingface.co/datasets/Fudan-fMRI/fMRI-Objaverse. fMRI-Objaverse includes data from 5 subjects, 4 of whom are also part of the Core set in fMRI-Shape, with each subject viewing 3142 3D objects across 117 categories, all accompanied by text captions. This significantly enhances the diversity and potential applications of the dataset. Additionally, we propose MinD-3D, a novel framework designed to decode 3D visual information from fMRI signals. The framework first extracts and aggregates features from fMRI data using a neuro-fusion encoder, then employs a feature-bridge diffusion model to generate visual features, and finally reconstructs the 3D object using a generative transformer decoder. We establish new benchmarks by designing metrics at both semantic and structural levels to evaluate model performance. Furthermore, we assess our model's effectiveness in an Out-of-Distribution setting and analyze the attribution of the extracted features and the visual ROIs in fMRI signals. Our experiments demonstrate that MinD-3D not only reconstructs 3D objects with high semantic and spatial accuracy but also deepens our understanding of how human brain processes 3D visual information. Project page at: https://jianxgao.github.io/MinD-3D.
Synthesizing Efficient Data with Diffusion Models for Person Re-Identification Pre-Training
Jun 10, 2024
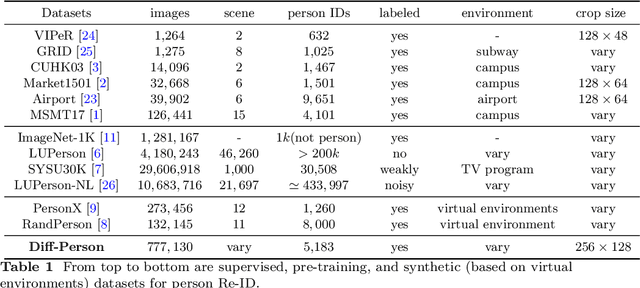
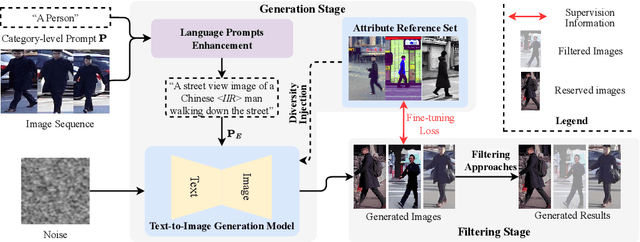
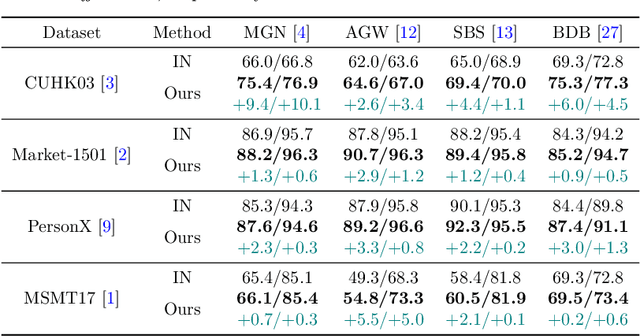
Existing person re-identification (Re-ID) methods principally deploy the ImageNet-1K dataset for model initialization, which inevitably results in sub-optimal situations due to the large domain gap. One of the key challenges is that building large-scale person Re-ID datasets is time-consuming. Some previous efforts address this problem by collecting person images from the internet e.g., LUPerson, but it struggles to learn from unlabeled, uncontrollable, and noisy data. In this paper, we present a novel paradigm Diffusion-ReID to efficiently augment and generate diverse images based on known identities without requiring any cost of data collection and annotation. Technically, this paradigm unfolds in two stages: generation and filtering. During the generation stage, we propose Language Prompts Enhancement (LPE) to ensure the ID consistency between the input image sequence and the generated images. In the diffusion process, we propose a Diversity Injection (DI) module to increase attribute diversity. In order to make the generated data have higher quality, we apply a Re-ID confidence threshold filter to further remove the low-quality images. Benefiting from our proposed paradigm, we first create a new large-scale person Re-ID dataset Diff-Person, which consists of over 777K images from 5,183 identities. Next, we build a stronger person Re-ID backbone pre-trained on our Diff-Person. Extensive experiments are conducted on four person Re-ID benchmarks in six widely used settings. Compared with other pre-training and self-supervised competitors, our approach shows significant superiority.
Distribution Aligned Semantics Adaption for Lifelong Person Re-Identification
May 30, 2024



In real-world scenarios, person Re-IDentification (Re-ID) systems need to be adaptable to changes in space and time. Therefore, the adaptation of Re-ID models to new domains while preserving previously acquired knowledge is crucial, known as Lifelong person Re-IDentification (LReID). Advanced LReID methods rely on replaying exemplars from old domains and applying knowledge distillation in logits with old models. However, due to privacy concerns, retaining previous data is inappropriate. Additionally, the fine-grained and open-set characteristics of Re-ID limit the effectiveness of the distillation paradigm for accumulating knowledge. We argue that a Re-ID model trained on diverse and challenging pedestrian images at a large scale can acquire robust and general human semantic knowledge. These semantics can be readily utilized as shared knowledge for lifelong applications. In this paper, we identify the challenges and discrepancies associated with adapting a pre-trained model to each application domain, and introduce the Distribution Aligned Semantics Adaption (DASA) framework. It efficiently adjusts Batch Normalization (BN) to mitigate interference from data distribution discrepancy and freezes the pre-trained convolutional layers to preserve shared knowledge. Additionally, we propose the lightweight Semantics Adaption (SA) module, which effectively adapts learned semantics to enhance pedestrian representations. Extensive experiments demonstrate the remarkable superiority of our proposed framework over advanced LReID methods, and it exhibits significantly reduced storage consumption. DASA presents a novel and cost-effective perspective on effectively adapting pre-trained models for LReID.
Auto-selected Knowledge Adapters for Lifelong Person Re-identification
May 30, 2024



Lifelong Person Re-Identification (LReID) extends traditional ReID by requiring systems to continually learn from non-overlapping datasets across different times and locations, adapting to new identities while preserving knowledge of previous ones. Existing approaches, either rehearsal-free or rehearsal-based, still suffer from the problem of catastrophic forgetting since they try to cram diverse knowledge into one fixed model. To overcome this limitation, we introduce a novel framework AdalReID, that adopts knowledge adapters and a parameter-free auto-selection mechanism for lifelong learning. Concretely, we incrementally build distinct adapters to learn domain-specific knowledge at each step, which can effectively learn and preserve knowledge across different datasets. Meanwhile, the proposed auto-selection strategy adaptively calculates the knowledge similarity between the input set and the adapters. On the one hand, the appropriate adapters are selected for the inputs to process ReID, and on the other hand, the knowledge interaction and fusion between adapters are enhanced to improve the generalization ability of the model. Extensive experiments are conducted to demonstrate the superiority of our AdalReID, which significantly outperforms SOTAs by about 10$\sim$20\% mAP on both seen and unseen domains.
Hyper-Transformer for Amodal Completion
May 30, 2024



Amodal object completion is a complex task that involves predicting the invisible parts of an object based on visible segments and background information. Learning shape priors is crucial for effective amodal completion, but traditional methods often rely on two-stage processes or additional information, leading to inefficiencies and potential error accumulation. To address these shortcomings, we introduce a novel framework named the Hyper-Transformer Amodal Network (H-TAN). This framework utilizes a hyper transformer equipped with a dynamic convolution head to directly learn shape priors and accurately predict amodal masks. Specifically, H-TAN uses a dual-branch structure to extract multi-scale features from both images and masks. The multi-scale features from the image branch guide the hyper transformer in learning shape priors and in generating the weights for dynamic convolution tailored to each instance. The dynamic convolution head then uses the features from the mask branch to predict precise amodal masks. We extensively evaluate our model on three benchmark datasets: KINS, COCOA-cls, and D2SA, where H-TAN demonstrated superior performance compared to existing methods. Additional experiments validate the effectiveness and stability of the novel hyper transformer in our framework.
Image-Text-Image Knowledge Transferring for Lifelong Person Re-Identification with Hybrid Clothing States
May 26, 2024



With the continuous expansion of intelligent surveillance networks, lifelong person re-identification (LReID) has received widespread attention, pursuing the need of self-evolution across different domains. However, existing LReID studies accumulate knowledge with the assumption that people would not change their clothes. In this paper, we propose a more practical task, namely lifelong person re-identification with hybrid clothing states (LReID-Hybrid), which takes a series of cloth-changing and cloth-consistent domains into account during lifelong learning. To tackle the challenges of knowledge granularity mismatch and knowledge presentation mismatch that occurred in LReID-Hybrid, we take advantage of the consistency and generalization of the text space, and propose a novel framework, dubbed $Teata$, to effectively align, transfer and accumulate knowledge in an "image-text-image" closed loop. Concretely, to achieve effective knowledge transfer, we design a Structured Semantic Prompt (SSP) learning to decompose the text prompt into several structured pairs to distill knowledge from the image space with a unified granularity of text description. Then, we introduce a Knowledge Adaptation and Projection strategy (KAP), which tunes text knowledge via a slow-paced learner to adapt to different tasks without catastrophic forgetting. Extensive experiments demonstrate the superiority of our proposed $Teata$ for LReID-Hybrid as well as on conventional LReID benchmarks over advanced methods.
Content and Salient Semantics Collaboration for Cloth-Changing Person Re-Identification
May 26, 2024

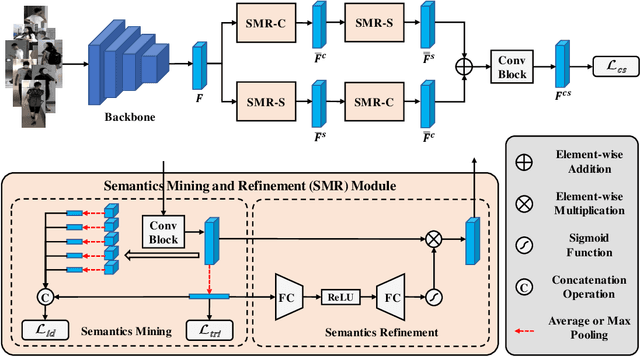

Cloth-changing person Re-IDentification (Re-ID) aims at recognizing the same person with clothing changes across non-overlapping cameras. Conventional person Re-ID methods usually bias the model's focus on cloth-related appearance features rather than identity-sensitive features associated with biological traits. Recently, advanced cloth-changing person Re-ID methods either resort to identity-related auxiliary modalities (e.g., sketches, silhouettes, keypoints and 3D shapes) or clothing labels to mitigate the impact of clothes. However, relying on unpractical and inflexible auxiliary modalities or annotations limits their real-world applicability. In this paper, we promote cloth-changing person Re-ID by effectively leveraging abundant semantics present within pedestrian images without the need for any auxiliaries. Specifically, we propose the Content and Salient Semantics Collaboration (CSSC) framework, facilitating cross-parallel semantics interaction and refinement. Our framework is simple yet effective, and the vital design is the Semantics Mining and Refinement (SMR) module. It extracts robust identity features about content and salient semantics, while mitigating interference from clothing appearances effectively. By capitalizing on the mined abundant semantic features, our proposed approach achieves state-of-the-art performance on three cloth-changing benchmarks as well as conventional benchmarks, demonstrating its superiority over advanced competitors.