 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Efficient Data with Diffusion Models for Person Re-Identification Pre-Training
Paper and Code

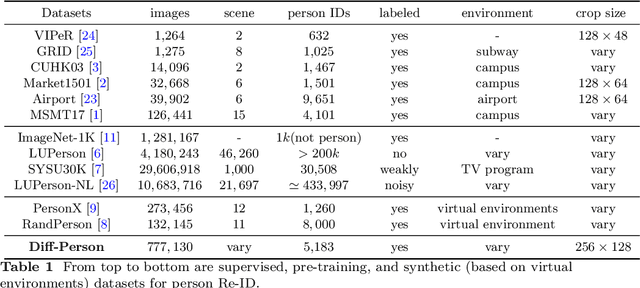
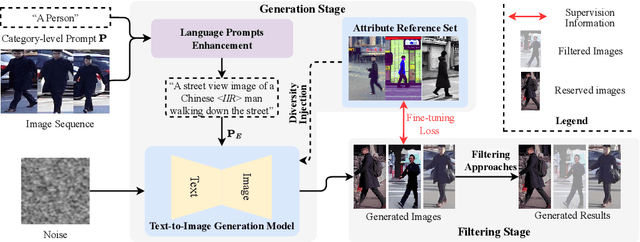
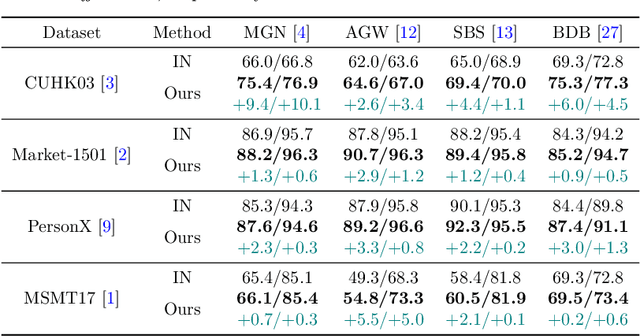
Existing person re-identification (Re-ID) methods principally deploy the ImageNet-1K dataset for model initialization, which inevitably results in sub-optimal situations due to the large domain gap. One of the key challenges is that building large-scale person Re-ID datasets is time-consuming. Some previous efforts address this problem by collecting person images from the internet e.g., LUPerson, but it struggles to learn from unlabeled, uncontrollable, and noisy data. In this paper, we present a novel paradigm Diffusion-ReID to efficiently augment and generate diverse images based on known identities without requiring any cost of data collection and annotation. Technically, this paradigm unfolds in two stages: generation and filtering. During the generation stage, we propose Language Prompts Enhancement (LPE) to ensure the ID consistency between the input image sequence and the generated images. In the diffusion process, we propose a Diversity Injection (DI) module to increase attribute diversity. In order to make the generated data have higher quality, we apply a Re-ID confidence threshold filter to further remove the low-quality images. Benefiting from our proposed paradigm, we first create a new large-scale person Re-ID dataset Diff-Person, which consists of over 777K images from 5,183 identities. Next, we build a stronger person Re-ID backbone pre-trained on our Diff-Person. Extensive experiments are conducted on four person Re-ID benchmarks in six widely used settings. Compared with other pre-training and self-supervised competitors, our approach shows significant superiority.