 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Large Vision-Language Models Meet Person Re-Identification
Nov 27, 2024



Large Vision-Language Models (LVLMs) that incorporate visual models and Large Language Models (LLMs) have achieved impressive results across various cross-modal understanding and reasoning tasks. In recent years, person re-identification (ReID) has also started to explore cross-modal semantics to improve the accuracy of identity recognition. However, effectively utilizing LVLMs for ReID remains an open challenge. While LVLMs operate under a generative paradigm by predicting the next output word, ReID requires the extraction of discriminative identity features to match pedestrians across cameras. In this paper, we propose LVLM-ReID, a novel framework that harnesses the strengths of LVLMs to promote ReID. Specifically, we employ instructions to guide the LVLM in generating one pedestrian semantic token that encapsulates key appearance semantics from the person image. This token is further refined through our Semantic-Guided Interaction (SGI) module, establishing a reciprocal interaction between the semantic token and visual tokens. Ultimately, the reinforced semantic token serves as the pedestrian identity representation. Our framework integrates the semantic understanding and generation capabilities of LVLMs into end-to-end ReID training, allowing LVLMs to capture rich semantic cues from pedestrian images during both training and inference. Our method achieves competitive results on multiple benchmarks without additional image-text annotations, demonstrating the potential of LVLM-generated semantics to advance person ReID and offering a promising direction for future research.
Unleashing the Potential of Tracklets for Unsupervised Video Person Re-Identification
Jun 20, 2024



With rich temporal-spatial information, video-based person re-identification methods have shown broad prospects. Although tracklets can be easily obtained with ready-made tracking models, annotating identities is still expensive and impractical. Therefore, some video-based methods propose using only a few identity annotations or camera labels to facilitate feature learning. They also simply average the frame features of each tracklet, overlooking unexpected variations and inherent identity consistency within tracklets. In this paper, we propose the Self-Supervised Refined Clustering (SSR-C) framework without relying on any annotation or auxiliary information to promote unsupervised video person re-identification. Specifically, we first propose the Noise-Filtered Tracklet Partition (NFTP) module to reduce the feature bias of tracklets caused by noisy tracking results, and sequentially partition the noise-filtered tracklets into "sub-tracklets". Then, we cluster and further merge sub-tracklets using the self-supervised signal from tracklet partition, which is enhanced through a progressive strategy to generate reliable pseudo labels, facilitating intra-class cross-tracklet aggregation. Moreover, we propose the Class Smoothing Classification (CSC) loss to efficiently promote model learning. Extensive experiments on the MARS and DukeMTMC-VideoReID datasets demonstrate that our proposed SSR-C for unsupervised video person re-identification achieves state-of-the-art results and is comparable to advanced supervised methods.
Distribution Aligned Semantics Adaption for Lifelong Person Re-Identification
May 30, 2024



In real-world scenarios, person Re-IDentification (Re-ID) systems need to be adaptable to changes in space and time. Therefore, the adaptation of Re-ID models to new domains while preserving previously acquired knowledge is crucial, known as Lifelong person Re-IDentification (LReID). Advanced LReID methods rely on replaying exemplars from old domains and applying knowledge distillation in logits with old models. However, due to privacy concerns, retaining previous data is inappropriate. Additionally, the fine-grained and open-set characteristics of Re-ID limit the effectiveness of the distillation paradigm for accumulating knowledge. We argue that a Re-ID model trained on diverse and challenging pedestrian images at a large scale can acquire robust and general human semantic knowledge. These semantics can be readily utilized as shared knowledge for lifelong applications. In this paper, we identify the challenges and discrepancies associated with adapting a pre-trained model to each application domain, and introduce the Distribution Aligned Semantics Adaption (DASA) framework. It efficiently adjusts Batch Normalization (BN) to mitigate interference from data distribution discrepancy and freezes the pre-trained convolutional layers to preserve shared knowledge. Additionally, we propose the lightweight Semantics Adaption (SA) module, which effectively adapts learned semantics to enhance pedestrian representations. Extensive experiments demonstrate the remarkable superiority of our proposed framework over advanced LReID methods, and it exhibits significantly reduced storage consumption. DASA presents a novel and cost-effective perspective on effectively adapting pre-trained models for LReID.
Content and Salient Semantics Collaboration for Cloth-Changing Person Re-Identification
May 26, 2024

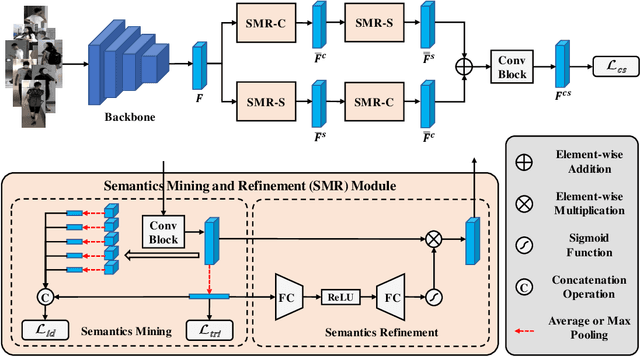

Cloth-changing person Re-IDentification (Re-ID) aims at recognizing the same person with clothing changes across non-overlapping cameras. Conventional person Re-ID methods usually bias the model's focus on cloth-related appearance features rather than identity-sensitive features associated with biological traits. Recently, advanced cloth-changing person Re-ID methods either resort to identity-related auxiliary modalities (e.g., sketches, silhouettes, keypoints and 3D shapes) or clothing labels to mitigate the impact of clothes. However, relying on unpractical and inflexible auxiliary modalities or annotations limits their real-world applicability. In this paper, we promote cloth-changing person Re-ID by effectively leveraging abundant semantics present within pedestrian images without the need for any auxiliaries. Specifically, we propose the Content and Salient Semantics Collaboration (CSSC) framework, facilitating cross-parallel semantics interaction and refinement. Our framework is simple yet effective, and the vital design is the Semantics Mining and Refinement (SMR) module. It extracts robust identity features about content and salient semantics, while mitigating interference from clothing appearances effectively. By capitalizing on the mined abundant semantic features, our proposed approach achieves state-of-the-art performance on three cloth-changing benchmarks as well as conventional benchmarks, demonstrating its superiority over advanced competitors.
Image-Text-Image Knowledge Transferring for Lifelong Person Re-Identification with Hybrid Clothing States
May 26, 2024



With the continuous expansion of intelligent surveillance networks, lifelong person re-identification (LReID) has received widespread attention, pursuing the need of self-evolution across different domains. However, existing LReID studies accumulate knowledge with the assumption that people would not change their clothes. In this paper, we propose a more practical task, namely lifelong person re-identification with hybrid clothing states (LReID-Hybrid), which takes a series of cloth-changing and cloth-consistent domains into account during lifelong learning. To tackle the challenges of knowledge granularity mismatch and knowledge presentation mismatch that occurred in LReID-Hybrid, we take advantage of the consistency and generalization of the text space, and propose a novel framework, dubbed $Teata$, to effectively align, transfer and accumulate knowledge in an "image-text-image" closed loop. Concretely, to achieve effective knowledge transfer, we design a Structured Semantic Prompt (SSP) learning to decompose the text prompt into several structured pairs to distill knowledge from the image space with a unified granularity of text description. Then, we introduce a Knowledge Adaptation and Projection strategy (KAP), which tunes text knowledge via a slow-paced learner to adapt to different tasks without catastrophic forgetting. Extensive experiments demonstrate the superiority of our proposed $Teata$ for LReID-Hybrid as well as on conventional LReID benchmarks over advanced methods.
Rethinking Person Re-identification from a Projection-on-Prototypes Perspective
Aug 21, 2023Person Re-IDentification (Re-ID) as a retrieval task, has achieved tremendous development over the past decade. Existing state-of-the-art methods follow an analogous framework to first extract features from the input images and then categorize them with a classifier. However, since there is no identity overlap between training and testing sets, the classifier is often discarded during inference. Only the extracted features are used for person retrieval via distance metrics. In this paper, we rethink the role of the classifier in person Re-ID, and advocate a new perspective to conceive the classifier as a projection from image features to class prototypes. These prototypes are exactly the learned parameters of the classifier. In this light, we describe the identity of input images as similarities to all prototypes, which are then utilized as more discriminative features to perform person Re-ID. We thereby propose a new baseline ProNet, which innovatively reserves the function of the classifier at the inference stage. To facilitate the learning of class prototypes, both triplet loss and identity classification loss are applied to features that undergo the projection by the classifier. An improved version of ProNet++ is presented by further incorporating multi-granularity designs. Experiments on four benchmarks demonstrate that our proposed ProNet is simple yet effective, and significantly beats previous baselines. ProNet++ also achieves competitive or even better results than transformer-based competitors.
Exploring Fine-Grained Representation and Recomposition for Cloth-Changing Person Re-Identification
Aug 21, 2023Cloth-changing person Re-IDentification (Re-ID) is a particularly challenging task, suffering from two limitations of inferior identity-relevant features and limited training samples. Existing methods mainly leverage auxiliary information to facilitate discriminative feature learning, including soft-biometrics features of shapes and gaits, and additional labels of clothing. However, these information may be unavailable in real-world applications. In this paper, we propose a novel FIne-grained Representation and Recomposition (FIRe$^{2}$) framework to tackle both limitations without any auxiliary information. Specifically, we first design a Fine-grained Feature Mining (FFM) module to separately cluster images of each person. Images with similar so-called fine-grained attributes (e.g., clothes and viewpoints) are encouraged to cluster together. An attribute-aware classification loss is introduced to perform fine-grained learning based on cluster labels, which are not shared among different people, promoting the model to learn identity-relevant features. Furthermore, by taking full advantage of the clustered fine-grained attributes, we present a Fine-grained Attribute Recomposition (FAR) module to recompose image features with different attributes in the latent space. It can significantly enhance representations for robust feature learning. Extensive experiments demonstrate that FIRe$^{2}$ can achieve state-of-the-art performance on five widely-used cloth-changing person Re-ID benchmarks.