 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrinciples of Forgetting in Domain-Incremental Semantic Segmentation in Adverse Weather Conditions
Mar 24, 2023Deep neural networks for scene perception in automated vehicles achieve excellent results for the domains they were trained on. However, in real-world conditions, the domain of operation and its underlying data distribution are subject to change. Adverse weather conditions, in particular, can significantly decrease model performance when such data are not available during training.Additionally, when a model is incrementally adapted to a new domain, it suffers from catastrophic forgetting, causing a significant drop in performance on previously observed domains. Despite recent progress in reducing catastrophic forgetting, its causes and effects remain obscure. Therefore, we study how the representations of semantic segmentation models are affected during domain-incremental learning in adverse weather conditions. Our experiments and representational analyses indicate that catastrophic forgetting is primarily caused by changes to low-level features in domain-incremental learning and that learning more general features on the source domain using pre-training and image augmentations leads to efficient feature reuse in subsequent tasks, which drastically reduces catastrophic forgetting. These findings highlight the importance of methods that facilitate generalized features for effective continual learning algorithms.
Effects of Architectures on Continual Semantic Segmentation
Feb 21, 2023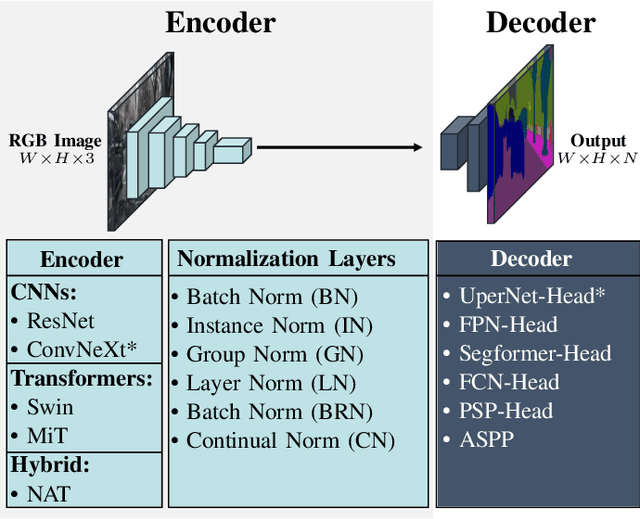
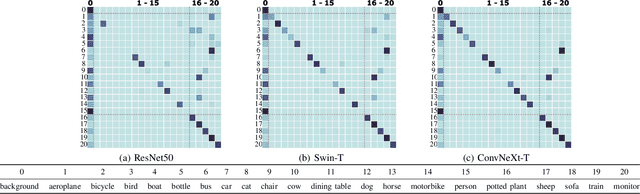
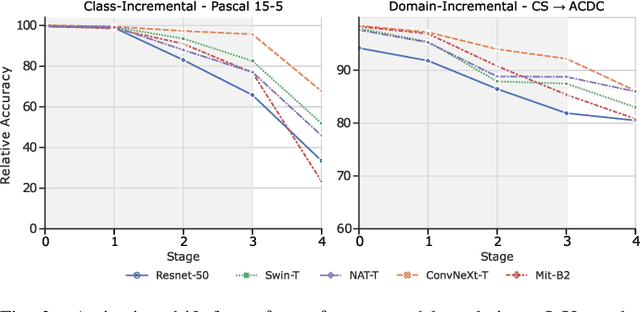
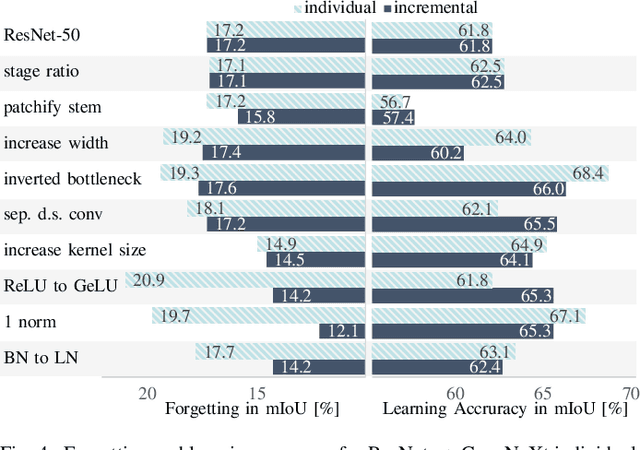
Research in the field of Continual Semantic Segmentation is mainly investigating novel learning algorithms to overcome catastrophic forgetting of neural networks. Most recent publications have focused on improving learning algorithms without distinguishing effects caused by the choice of neural architecture.Therefore, we study how the choice of neural network architecture affects catastrophic forgetting in class- and domain-incremental semantic segmentation. Specifically, we compare the well-researched CNNs to recently proposed Transformers and Hybrid architectures, as well as the impact of the choice of novel normalization layers and different decoder heads. We find that traditional CNNs like ResNet have high plasticity but low stability, while transformer architectures are much more stable. When the inductive biases of CNN architectures are combined with transformers in hybrid architectures, it leads to higher plasticity and stability. The stability of these models can be explained by their ability to learn general features that are robust against distribution shifts. Experiments with different normalization layers show that Continual Normalization achieves the best trade-off in terms of adaptability and stability of the model. In the class-incremental setting, the choice of the normalization layer has much less impact. Our experiments suggest that the right choice of architecture can significantly reduce forgetting even with naive fine-tuning and confirm that for real-world applications, the architecture is an important factor in designing a continual learning model.
Improving Replay-Based Continual Semantic Segmentation with Smart Data Selection
Sep 20, 2022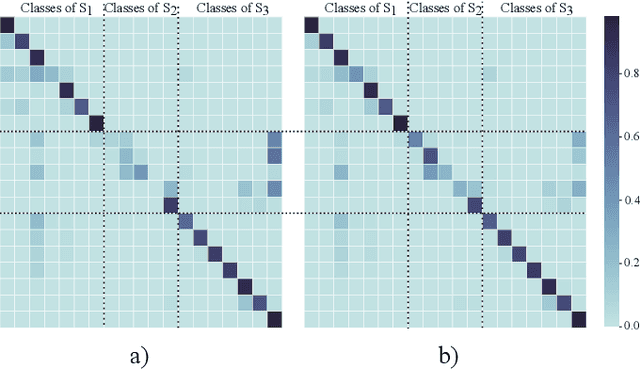
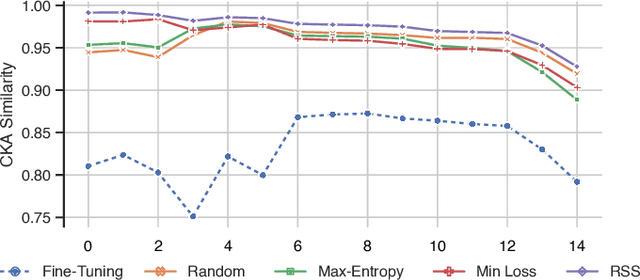
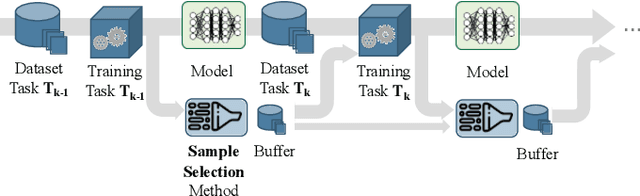
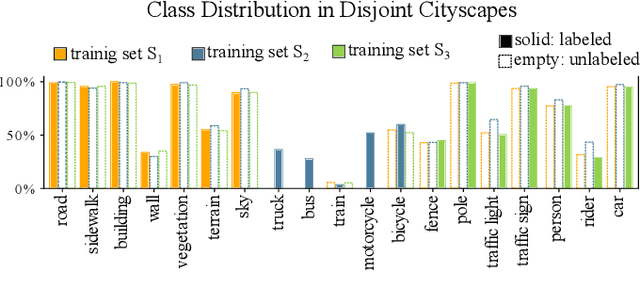
Continual learning for Semantic Segmentation (CSS) is a rapidly emerging field, in which the capabilities of the segmentation model are incrementally improved by learning new classes or new domains. A central challenge in Continual Learning is overcoming the effects of catastrophic forgetting, which refers to the sudden drop in accuracy on previously learned tasks after the model is trained on new classes or domains. In continual classification this challenge is often overcome by replaying a small selection of samples from previous tasks, however replay is rarely considered in CSS. Therefore, we investigate the influences of various replay strategies for semantic segmentation and evaluate them in class- and domain-incremental settings. Our findings suggest that in a class-incremental setting, it is critical to achieve a uniform distribution for the different classes in the buffer to avoid a bias towards newly learned classes. In the domain-incremental setting, it is most effective to select buffer samples by uniformly sampling from the distribution of learned feature representations or by choosing samples with median entropy. Finally, we observe that the effective sampling methods help to decrease the representation shift significantly in early layers, which is a major cause of forgetting in domain-incremental learning.
Continual Learning for Class- and Domain-Incremental Semantic Segmentation
Sep 16, 2022
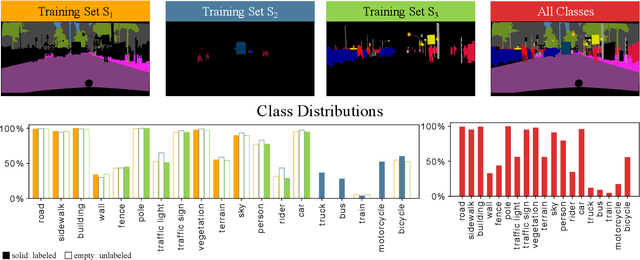
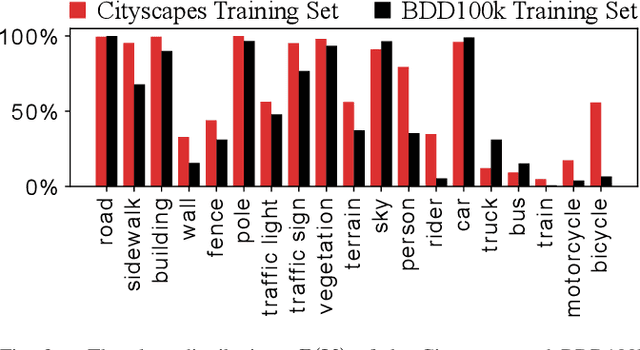
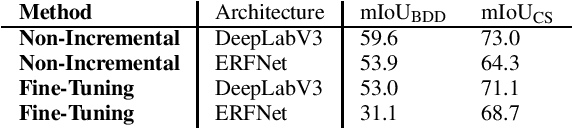
The field of continual deep learning is an emerging field and a lot of progress has been made. However, concurrently most of the approaches are only tested on the task of image classification, which is not relevant in the field of intelligent vehicles. Only recently approaches for class-incremental semantic segmentation were proposed. However, all of those approaches are based on some form of knowledge distillation. At the moment there are no investigations on replay-based approaches that are commonly used for object recognition in a continual setting. At the same time while unsupervised domain adaption for semantic segmentation gained a lot of traction, investigations regarding domain-incremental learning in an continual setting is not well-studied. Therefore, the goal of our work is to evaluate and adapt established solutions for continual object recognition to the task of semantic segmentation and to provide baseline methods and evaluation protocols for the task of continual semantic segmentation. We firstly introduce evaluation protocols for the class- and domain-incremental segmentation and analyze selected approaches. We show that the nature of the task of semantic segmentation changes which methods are most effective in mitigating forgetting compared to image classification. Especially, in class-incremental learning knowledge distillation proves to be a vital tool, whereas in domain-incremental learning replay methods are the most effective method.
Causes of Catastrophic Forgetting in Class-Incremental Semantic Segmentation
Sep 16, 2022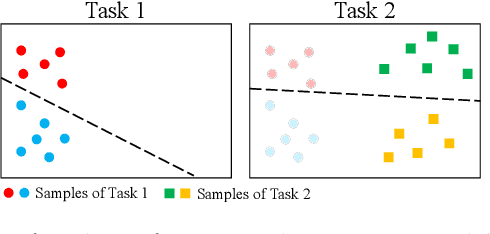
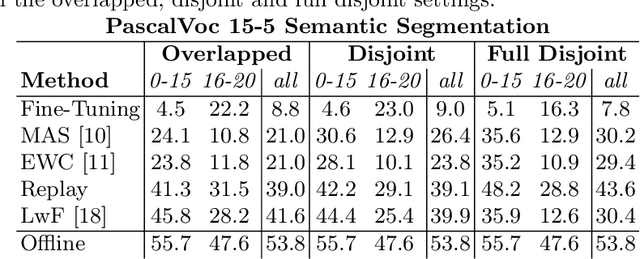
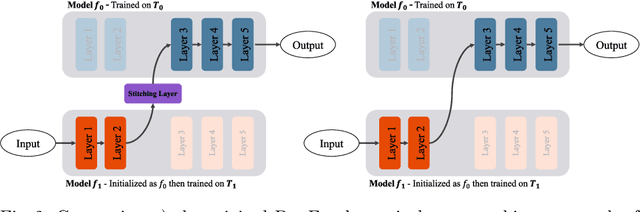
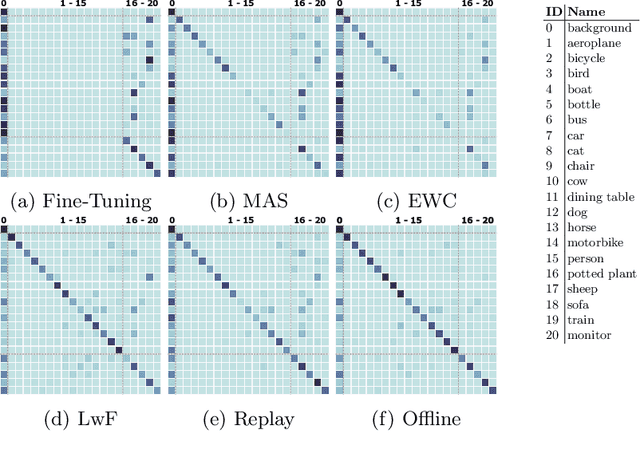
Class-incremental learning for semantic segmentation (CiSS) is presently a highly researched field which aims at updating a semantic segmentation model by sequentially learning new semantic classes. A major challenge in CiSS is overcoming the effects of catastrophic forgetting, which describes the sudden drop of accuracy on previously learned classes after the model is trained on a new set of classes. Despite latest advances in mitigating catastrophic forgetting, the underlying causes of forgetting specifically in CiSS are not well understood. Therefore, in a set of experiments and representational analyses, we demonstrate that the semantic shift of the background class and a bias towards new classes are the major causes of forgetting in CiSS. Furthermore, we show that both causes mostly manifest themselves in deeper classification layers of the network, while the early layers of the model are not affected. Finally, we demonstrate how both causes are effectively mitigated utilizing the information contained in the background, with the help of knowledge distillation and an unbiased cross-entropy loss.
Human Pose Estimation for Real-World Crowded Scenarios
Jul 16, 2019
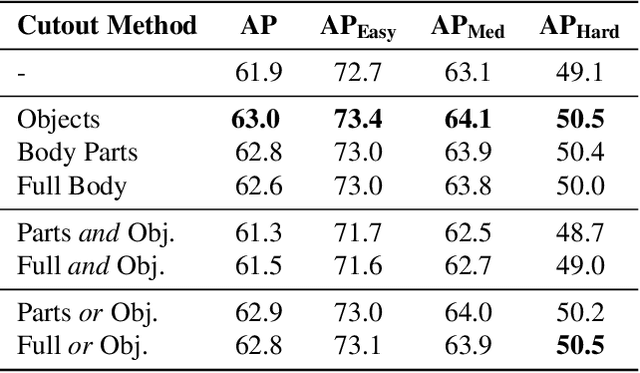

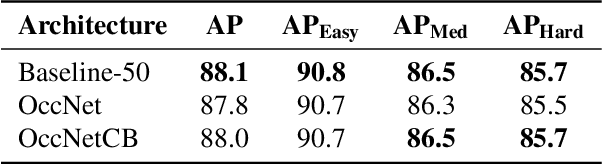
Human pose estimation has recently made significant progress with the adoption of deep convolutional neural networks. Its many applications have attracted tremendous interest in recent years. However, many practical applications require pose estimation for human crowds, which still is a rarely addressed problem. In this work, we explore methods to optimize pose estimation for human crowds, focusing on challenges introduced with dense crowds, such as occlusions, people in close proximity to each other, and partial visibility of people. In order to address these challenges, we evaluate three aspects of a pose detection approach: i) a data augmentation method to introduce robustness to occlusions, ii) the explicit detection of occluded body parts, and iii) the use of the synthetic generated datasets. The first approach to improve the accuracy in crowded scenarios is to generate occlusions at training time using person and object cutouts from the object recognition dataset COCO (Common Objects in Context). Furthermore, the synthetically generated dataset JTA (Joint Track Auto) is evaluated for the use in real-world crowd applications. In order to overcome the transfer gap of JTA originating from a low pose variety and less dense crowds, an extension dataset is created to ease the use for real-world applications. Additionally, the occlusion flags provided with JTA are utilized to train a model, which explicitly distinguishes between occluded and visible body parts in two distinct branches. The combination of the proposed additions to the baseline method help to improve the overall accuracy by 4.7% AP and thereby provide comparable results to current state-of-the-art approaches on the respective dataset.