 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Systematic Data Acquisition and Data-Driven Simulation for the Safety Testing of Automated Driving Functions
May 02, 2024
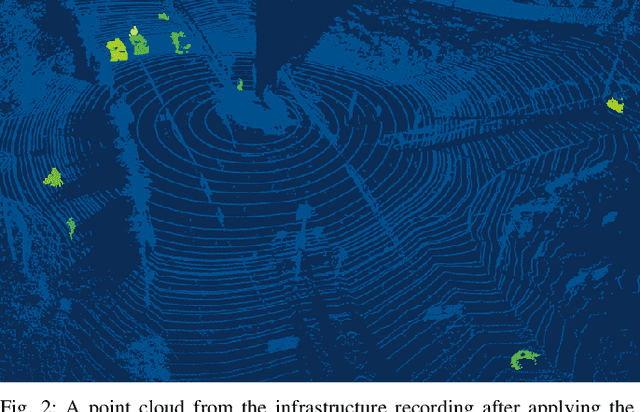
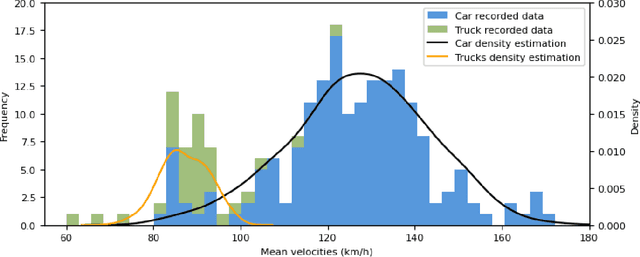
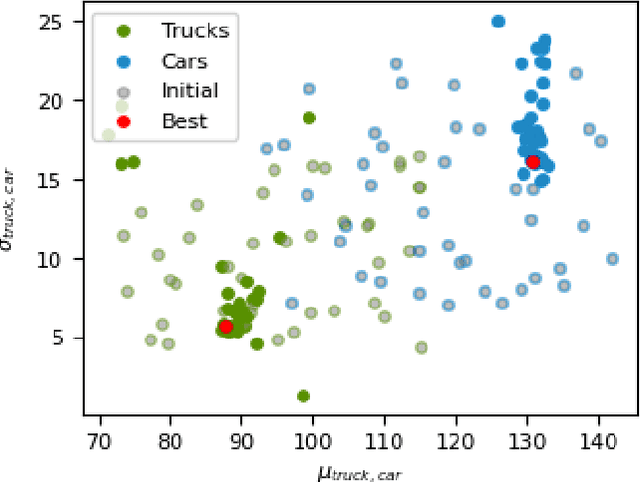
With growing complexity and criticality of automated driving functions in road traffic and their operational design domains (ODD), there is increasing demand for covering significant proportions of development, validation, and verification in virtual environments and through simulation models. If, however, simulations are meant not only to augment real-world experiments, but to replace them, quantitative approaches are required that measure to what degree and under which preconditions simulation models adequately represent reality, and thus, using their results accordingly. Especially in R&D areas related to the safety impact of the "open world", there is a significant shortage of real-world data to parameterize and/or validate simulations - especially with respect to the behavior of human traffic participants, whom automated driving functions will meet in mixed traffic. We present an approach to systematically acquire data in public traffic by heterogeneous means, transform it into a unified representation, and use it to automatically parameterize traffic behavior models for use in data-driven virtual validation of automated driving functions.
Effects of Architectures on Continual Semantic Segmentation
Feb 21, 2023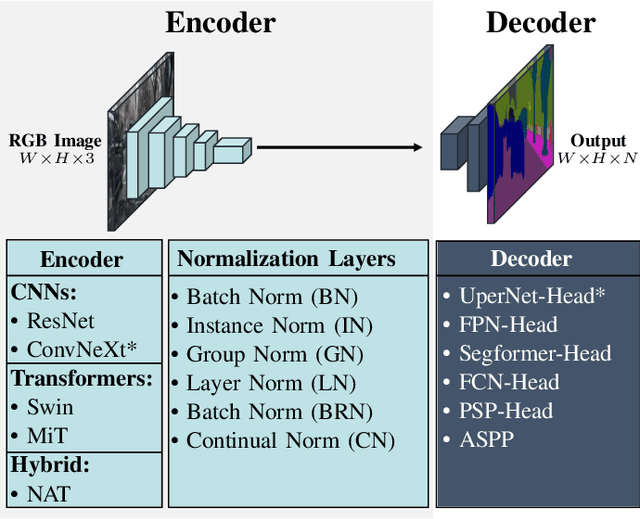
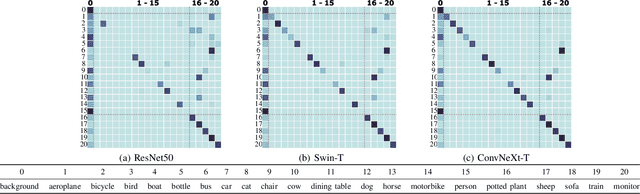
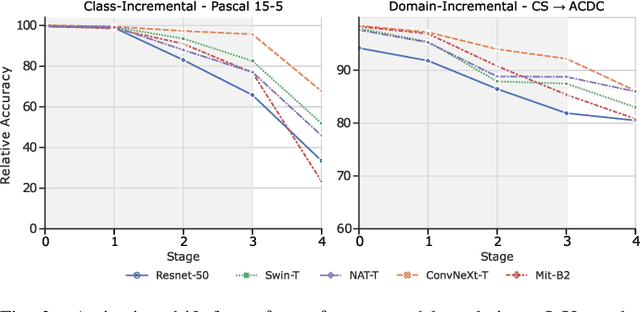
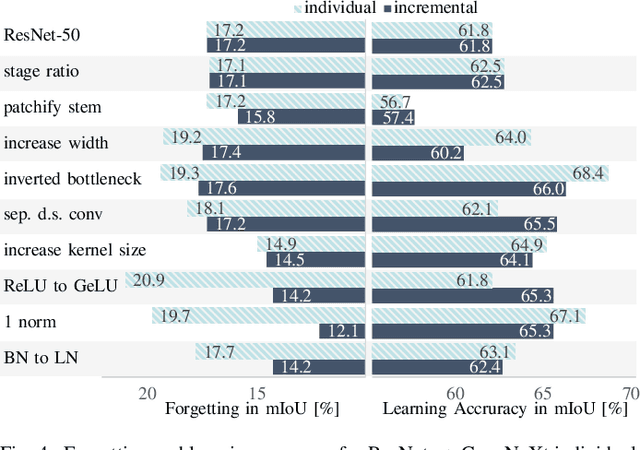
Research in the field of Continual Semantic Segmentation is mainly investigating novel learning algorithms to overcome catastrophic forgetting of neural networks. Most recent publications have focused on improving learning algorithms without distinguishing effects caused by the choice of neural architecture.Therefore, we study how the choice of neural network architecture affects catastrophic forgetting in class- and domain-incremental semantic segmentation. Specifically, we compare the well-researched CNNs to recently proposed Transformers and Hybrid architectures, as well as the impact of the choice of novel normalization layers and different decoder heads. We find that traditional CNNs like ResNet have high plasticity but low stability, while transformer architectures are much more stable. When the inductive biases of CNN architectures are combined with transformers in hybrid architectures, it leads to higher plasticity and stability. The stability of these models can be explained by their ability to learn general features that are robust against distribution shifts. Experiments with different normalization layers show that Continual Normalization achieves the best trade-off in terms of adaptability and stability of the model. In the class-incremental setting, the choice of the normalization layer has much less impact. Our experiments suggest that the right choice of architecture can significantly reduce forgetting even with naive fine-tuning and confirm that for real-world applications, the architecture is an important factor in designing a continual learning model.