 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Full Body Anonymization using Text-to-Image Diffusion Models
Oct 11, 2024
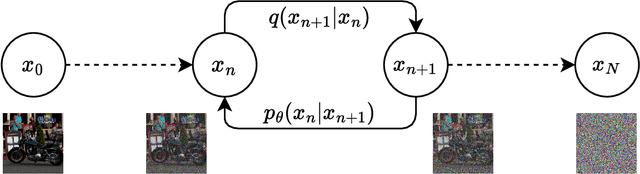
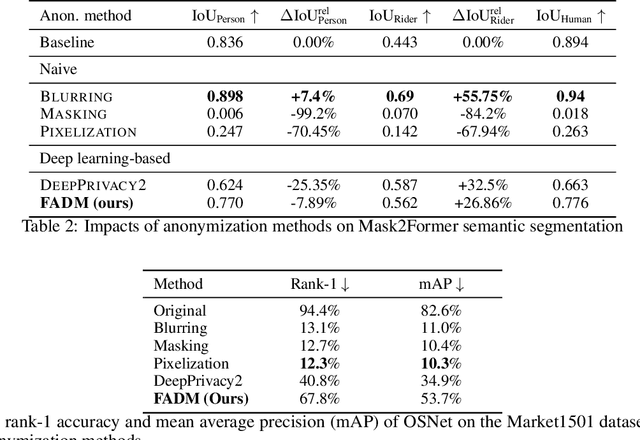
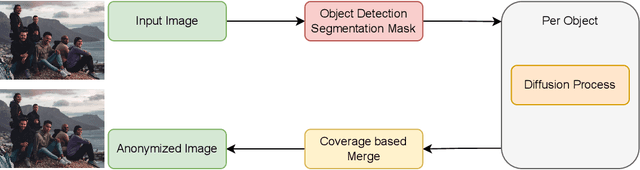
Anonymization plays a key role in protecting sensible information of individuals in real world datasets. Self-driving cars for example need high resolution facial features to track people and their viewing direction to predict future behaviour and react accordingly. In order to protect people's privacy whilst keeping important features in the dataset, it is important to replace the full body of a person with a highly detailed anonymized one. In contrast to doing face anonymization, full body replacement decreases the ability of recognizing people by their hairstyle or clothes. In this paper, we propose a workflow for full body person anonymization utilizing Stable Diffusion as a generative backend. Text-to-image diffusion models, like Stable Diffusion, OpenAI's DALL-E or Midjourney, have become very popular in recent time, being able to create photorealistic images from a single text prompt. We show that our method outperforms state-of-the art anonymization pipelines with respect to image quality, resolution, Inception Score (IS) and Frechet Inception Distance (FID). Additionally, our method is invariant with respect to the image generator and thus able to be used with the latest models available.
SceneMotion: From Agent-Centric Embeddings to Scene-Wide Forecasts
Aug 02, 2024



Self-driving vehicles rely on multimodal motion forecasts to effectively interact with their environment and plan safe maneuvers. We introduce SceneMotion, an attention-based model for forecasting scene-wide motion modes of multiple traffic agents. Our model transforms local agent-centric embeddings into scene-wide forecasts using a novel latent context module. This module learns a scene-wide latent space from multiple agent-centric embeddings, enabling joint forecasting and interaction modeling. The competitive performance in the Waymo Open Interaction Prediction Challenge demonstrates the effectiveness of our approach. Moreover, we cluster future waypoints in time and space to quantify the interaction between agents. We merge all modes and analyze each mode independently to determine which clusters are resolved through interaction or result in conflict. Our implementation is available at: https://github.com/kit-mrt/future-motion
A Joint Approach Towards Data-Driven Virtual Testing for Automated Driving: The AVEAS Project
May 10, 2024



With growing complexity and responsibility of automated driving functions in road traffic and growing scope of their operational design domains, there is increasing demand for covering significant parts of development, validation, and verification via virtual environments and simulation models. If, however, simulations are meant not only to augment real-world experiments, but to replace them, quantitative approaches are required that measure to what degree and under which preconditions simulation models adequately represent reality, and thus allow their usage for virtual testing of driving functions. Especially in research and development areas related to the safety impacts of the "open world", there is a significant shortage of real-world data to parametrize and/or validate simulations - especially with respect to the behavior of human traffic participants, whom automated vehicles will meet in mixed traffic. This paper presents the intermediate results of the German AVEAS research project (www.aveas.org) which aims at developing methods and metrics for the harmonized, systematic, and scalable acquisition of real-world data for virtual verification and validation of advanced driver assistance systems and automated driving, and establishing an online database following the FAIR principles.
* 6 pages, 5 figures, 2 tables
An Approach to Systematic Data Acquisition and Data-Driven Simulation for the Safety Testing of Automated Driving Functions
May 02, 2024
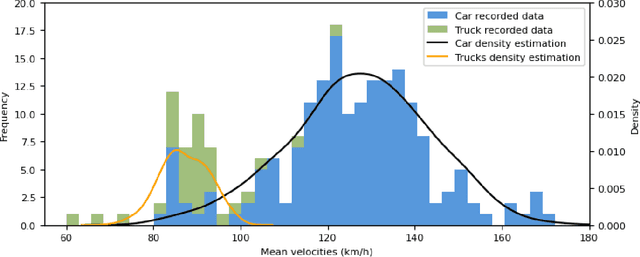
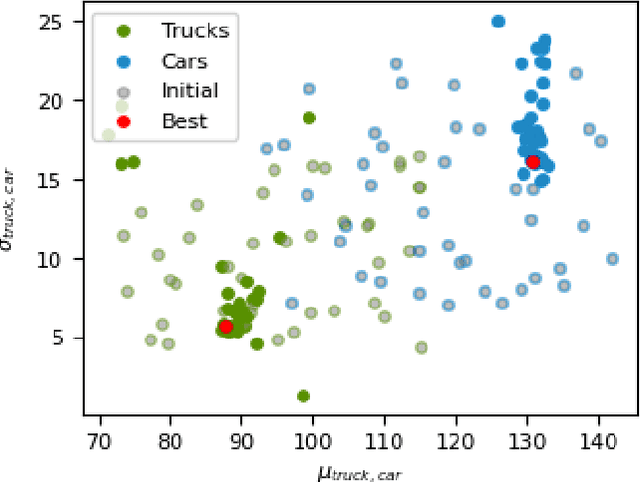
With growing complexity and criticality of automated driving functions in road traffic and their operational design domains (ODD), there is increasing demand for covering significant proportions of development, validation, and verification in virtual environments and through simulation models. If, however, simulations are meant not only to augment real-world experiments, but to replace them, quantitative approaches are required that measure to what degree and under which preconditions simulation models adequately represent reality, and thus, using their results accordingly. Especially in R&D areas related to the safety impact of the "open world", there is a significant shortage of real-world data to parameterize and/or validate simulations - especially with respect to the behavior of human traffic participants, whom automated driving functions will meet in mixed traffic. We present an approach to systematically acquire data in public traffic by heterogeneous means, transform it into a unified representation, and use it to automatically parameterize traffic behavior models for use in data-driven virtual validation of automated driving functions.
MAP-Former: Multi-Agent-Pair Gaussian Joint Prediction
Apr 30, 2024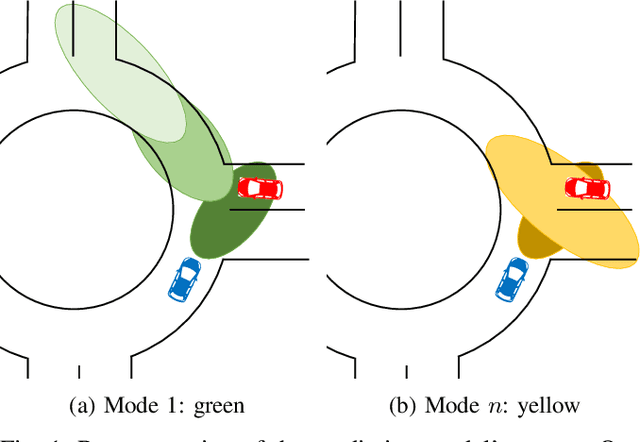
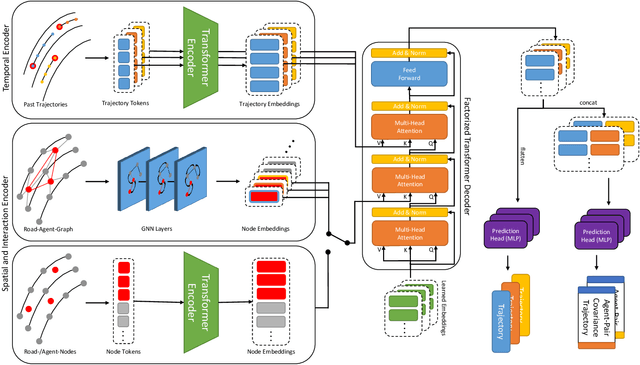
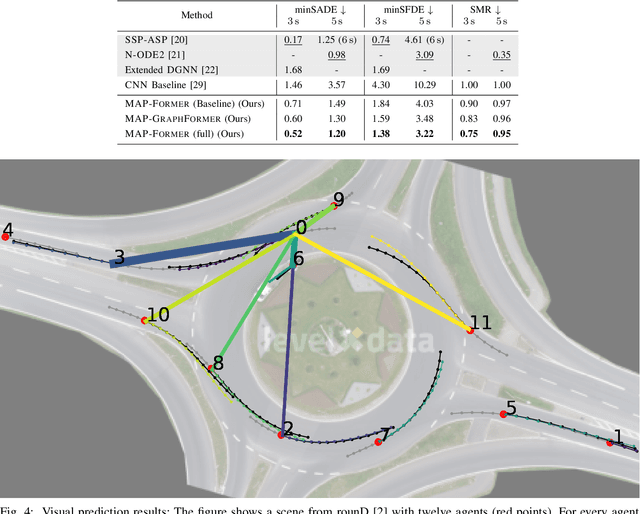
There is a gap in risk assessment of trajectories between the trajectory information coming from a traffic motion prediction module and what is actually needed. Closing this gap necessitates advancements in prediction beyond current practices. Existing prediction models yield joint predictions of agents' future trajectories with uncertainty weights or marginal Gaussian probability density functions (PDFs) for single agents. Although, these methods achieve high accurate trajectory predictions, they only provide little or no information about the dependencies of interacting agents. Since traffic is a process of highly interdependent agents, whose actions directly influence their mutual behavior, the existing methods are not sufficient to reliably assess the risk of future trajectories. This paper addresses that gap by introducing a novel approach to motion prediction, focusing on predicting agent-pair covariance matrices in a ``scene-centric'' manner, which can then be used to model Gaussian joint PDFs for all agent-pairs in a scene. We propose a model capable of predicting those agent-pair covariance matrices, leveraging an enhanced awareness of interactions. Utilizing the prediction results of our model, this work forms the foundation for comprehensive risk assessment with statistically based methods for analyzing agents' relations by their joint PDFs.
JointMotion: Joint Self-supervision for Joint Motion Prediction
Mar 08, 2024



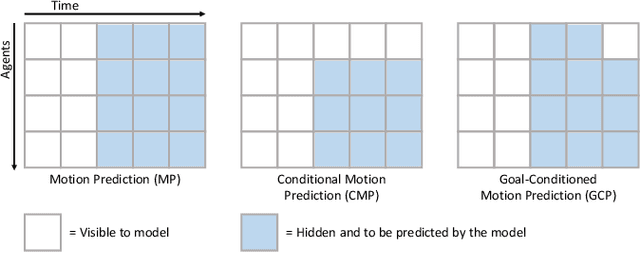
We present JointMotion, a self-supervised learning method for joint motion prediction in autonomous driving. Our method includes a scene-level objective connecting motion and environments, and an instance-level objective to refine learned representations. Our evaluations show that these objectives are complementary and outperform recent contrastive and autoencoding methods as pre-training for joint motion prediction. Furthermore, JointMotion adapts to all common types of environment representations used for motion prediction (i.e., agent-centric, scene-centric, and pairwise relative), and enables effective transfer learning between the Waymo Open Motion and the Argoverse 2 Forecasting datasets. Notably, our method improves the joint final displacement error of Wayformer, Scene Transformer, and HPTR by 3%, 7%, and 11%, respectively.
Road Barlow Twins: Redundancy Reduction for Road Environment Descriptors and Motion Prediction
Jun 19, 2023



Anticipating the future motion of traffic agents is vital for self-driving vehicles to ensure their safe operation. We introduce a novel self-supervised pre-training method as well as a transformer model for motion prediction. Our method is based on Barlow Twins and applies the redundancy reduction principle to embeddings generated from HD maps. Additionally, we introduce a novel approach for redundancy reduction, where a potentially large and variable set of road environment tokens is transformed into a fixed-size set of road environment descriptors (RED). Our experiments reveal that the proposed pre-training method can improve minADE and minFDE by 12% and 15% and outperform contrastive learning with PreTraM and SimCLR in a semi-supervised setting. Our REDMotion model achieves results that are competitive with those of recent related methods such as MultiPath++ or Scene Transformer. Code is available at: https://github.com/kit-mrt/road-barlow-twins
MaskedFusion360: Reconstruct LiDAR Data by Querying Camera Features
Jun 12, 2023



In self-driving applications, LiDAR data provides accurate information about distances in 3D but lacks the semantic richness of camera data. Therefore, state-of-the-art methods for perception in urban scenes fuse data from both sensor types. In this work, we introduce a novel self-supervised method to fuse LiDAR and camera data for self-driving applications. We build upon masked autoencoders (MAEs) and train deep learning models to reconstruct masked LiDAR data from fused LiDAR and camera features. In contrast to related methods that use birds-eye-view representations, we fuse features from dense spherical LiDAR projections and features from fish-eye camera crops with a similar field of view. Therefore, we reduce the learned spatial transformations to moderate perspective transformations and do not require additional modules to generate dense LiDAR representations. Code is available at: https://github.com/KIT-MRT/masked-fusion-360
LDFA: Latent Diffusion Face Anonymization for Self-driving Applications
Feb 17, 2023



In order to protect vulnerable road users (VRUs), such as pedestrians or cyclists, it is essential that intelligent transportation systems (ITS) accurately identify them. Therefore, datasets used to train perception models of ITS must contain a significant number of vulnerable road users. However, data protection regulations require that individuals are anonymized in such datasets. In this work, we introduce a novel deep learning-based pipeline for face anonymization in the context of ITS. In contrast to related methods, we do not use generative adversarial networks (GANs) but build upon recent advances in diffusion models. We propose a two-stage method, which contains a face detection model followed by a latent diffusion model to generate realistic face in-paintings. To demonstrate the versatility of anonymized images, we train segmentation methods on anonymized data and evaluate them on non-anonymized data. Our experiment reveal that our pipeline is better suited to anonymize data for segmentation than naive methods and performes comparably with recent GAN-based methods. Moreover, face detectors achieve higher mAP scores for faces anonymized by our method compared to naive or recent GAN-based methods.