 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
Mar 24, 2026In real-world domains such as self-driving, generalization to rare scenarios remains a fundamental challenge. To address this, we introduce a new dataset designed for end-to-end driving that focuses on long-tail driving events. We provide multi-view video data, trajectories, high-level instructions, and detailed reasoning traces, facilitating in-context learning and few-shot generalization. The resulting benchmark for multimodal models, such as VLMs and VLAs, goes beyond safety and comfort metrics by evaluating instruction following and semantic coherence between model outputs. The multilingual reasoning traces in English, Spanish, and Chinese are from domain experts with diverse cultural backgrounds. Thus, our dataset is a unique resource for studying how different forms of reasoning affect driving competence. Our dataset is available at: https://hf.co/datasets/kit-mrt/kitscenes-longtail
RetroMotion: Retrocausal Motion Forecasting Models are Instructable
May 26, 2025Motion forecasts of road users (i.e., agents) vary in complexity as a function of scene constraints and interactive behavior. We address this with a multi-task learning method for motion forecasting that includes a retrocausal flow of information. The corresponding tasks are to forecast (1) marginal trajectory distributions for all modeled agents and (2) joint trajectory distributions for interacting agents. Using a transformer model, we generate the joint distributions by re-encoding marginal distributions followed by pairwise modeling. This incorporates a retrocausal flow of information from later points in marginal trajectories to earlier points in joint trajectories. Per trajectory point, we model positional uncertainty using compressed exponential power distributions. Notably, our method achieves state-of-the-art results in the Waymo Interaction Prediction dataset and generalizes well to the Argoverse 2 dataset. Additionally, our method provides an interface for issuing instructions through trajectory modifications. Our experiments show that regular training of motion forecasting leads to the ability to follow goal-based instructions and to adapt basic directional instructions to the scene context. Code: https://github.com/kit-mrt/future-motion
Divide and Merge: Motion and Semantic Learning in End-to-End Autonomous Driving
Feb 11, 2025



Perceiving the environment and its changes over time corresponds to two fundamental yet heterogeneous types of information: semantics and motion. Previous end-to-end autonomous driving works represent both types of information in a single feature vector. However, including motion tasks, such as prediction and planning, always impairs detection and tracking performance, a phenomenon known as negative transfer in multi-task learning. To address this issue, we propose Neural-Bayes motion decoding, a novel parallel detection, tracking, and prediction method separating semantic and motion learning, similar to the Bayes filter. Specifically, we employ a set of learned motion queries that operate in parallel with the detection and tracking queries, sharing a unified set of recursively updated reference points. Moreover, we employ interactive semantic decoding to enhance information exchange in semantic tasks, promoting positive transfer. Experiments on the nuScenes dataset show improvements of 5% in detection and 11% in tracking. Our method achieves state-of-the-art collision rates in open-loop planning evaluation without any modifications to the planning module.
SceneMotion: From Agent-Centric Embeddings to Scene-Wide Forecasts
Aug 02, 2024



Self-driving vehicles rely on multimodal motion forecasts to effectively interact with their environment and plan safe maneuvers. We introduce SceneMotion, an attention-based model for forecasting scene-wide motion modes of multiple traffic agents. Our model transforms local agent-centric embeddings into scene-wide forecasts using a novel latent context module. This module learns a scene-wide latent space from multiple agent-centric embeddings, enabling joint forecasting and interaction modeling. The competitive performance in the Waymo Open Interaction Prediction Challenge demonstrates the effectiveness of our approach. Moreover, we cluster future waypoints in time and space to quantify the interaction between agents. We merge all modes and analyze each mode independently to determine which clusters are resolved through interaction or result in conflict. Our implementation is available at: https://github.com/kit-mrt/future-motion
Words in Motion: Representation Engineering for Motion Forecasting
Jun 17, 2024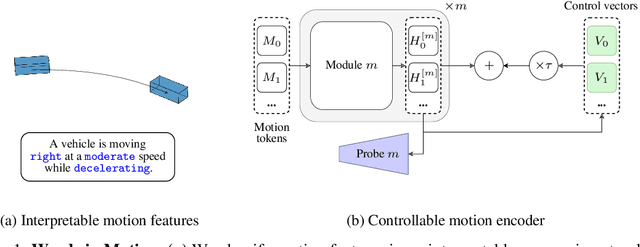
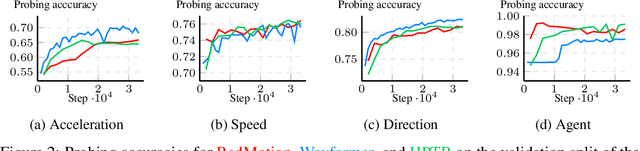
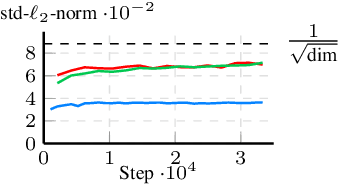
Motion forecasting transforms sequences of past movements and environment context into future motion. Recent methods rely on learned representations, resulting in hidden states that are difficult to interpret. In this work, we use natural language to quantize motion features in a human-interpretable way, and measure the degree to which they are embedded in hidden states. Our experiments reveal that hidden states of motion sequences are arranged with respect to our discrete sets of motion features. Following these insights, we fit control vectors to motion features, which allow for controlling motion forecasts at inference. Consequently, our method enables controlling transformer-based motion forecasting models with textual inputs, providing a unique interface to interact with and understand these models. Our implementation is available at https://github.com/kit-mrt/future-motion
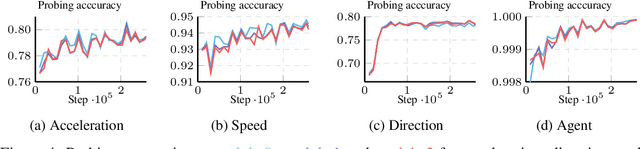
JointMotion: Joint Self-supervision for Joint Motion Prediction
Mar 08, 2024



We present JointMotion, a self-supervised learning method for joint motion prediction in autonomous driving. Our method includes a scene-level objective connecting motion and environments, and an instance-level objective to refine learned representations. Our evaluations show that these objectives are complementary and outperform recent contrastive and autoencoding methods as pre-training for joint motion prediction. Furthermore, JointMotion adapts to all common types of environment representations used for motion prediction (i.e., agent-centric, scene-centric, and pairwise relative), and enables effective transfer learning between the Waymo Open Motion and the Argoverse 2 Forecasting datasets. Notably, our method improves the joint final displacement error of Wayformer, Scene Transformer, and HPTR by 3%, 7%, and 11%, respectively.
Road Barlow Twins: Redundancy Reduction for Road Environment Descriptors and Motion Prediction
Jun 19, 2023



Anticipating the future motion of traffic agents is vital for self-driving vehicles to ensure their safe operation. We introduce a novel self-supervised pre-training method as well as a transformer model for motion prediction. Our method is based on Barlow Twins and applies the redundancy reduction principle to embeddings generated from HD maps. Additionally, we introduce a novel approach for redundancy reduction, where a potentially large and variable set of road environment tokens is transformed into a fixed-size set of road environment descriptors (RED). Our experiments reveal that the proposed pre-training method can improve minADE and minFDE by 12% and 15% and outperform contrastive learning with PreTraM and SimCLR in a semi-supervised setting. Our REDMotion model achieves results that are competitive with those of recent related methods such as MultiPath++ or Scene Transformer. Code is available at: https://github.com/kit-mrt/road-barlow-twins
MaskedFusion360: Reconstruct LiDAR Data by Querying Camera Features
Jun 12, 2023



In self-driving applications, LiDAR data provides accurate information about distances in 3D but lacks the semantic richness of camera data. Therefore, state-of-the-art methods for perception in urban scenes fuse data from both sensor types. In this work, we introduce a novel self-supervised method to fuse LiDAR and camera data for self-driving applications. We build upon masked autoencoders (MAEs) and train deep learning models to reconstruct masked LiDAR data from fused LiDAR and camera features. In contrast to related methods that use birds-eye-view representations, we fuse features from dense spherical LiDAR projections and features from fish-eye camera crops with a similar field of view. Therefore, we reduce the learned spatial transformations to moderate perspective transformations and do not require additional modules to generate dense LiDAR representations. Code is available at: https://github.com/KIT-MRT/masked-fusion-360
LDFA: Latent Diffusion Face Anonymization for Self-driving Applications
Feb 17, 2023



In order to protect vulnerable road users (VRUs), such as pedestrians or cyclists, it is essential that intelligent transportation systems (ITS) accurately identify them. Therefore, datasets used to train perception models of ITS must contain a significant number of vulnerable road users. However, data protection regulations require that individuals are anonymized in such datasets. In this work, we introduce a novel deep learning-based pipeline for face anonymization in the context of ITS. In contrast to related methods, we do not use generative adversarial networks (GANs) but build upon recent advances in diffusion models. We propose a two-stage method, which contains a face detection model followed by a latent diffusion model to generate realistic face in-paintings. To demonstrate the versatility of anonymized images, we train segmentation methods on anonymized data and evaluate them on non-anonymized data. Our experiment reveal that our pipeline is better suited to anonymize data for segmentation than naive methods and performes comparably with recent GAN-based methods. Moreover, face detectors achieve higher mAP scores for faces anonymized by our method compared to naive or recent GAN-based methods.
Self-supervised Pseudo-colorizing of Masked Cells
Feb 12, 2023



Self-supervised learning, which is strikingly referred to as the dark matter of intelligence, is gaining more attention in biomedical applications of deep learning. In this work, we introduce a novel self-supervision objective for the analysis of cells in biomedical microscopy images. We propose training deep learning models to pseudo-colorize masked cells. We use a physics-informed pseudo-spectral colormap that is well suited for colorizing cell topology. Our experiments reveal that approximating semantic segmentation by pseudo-colorization is beneficial for subsequent fine-tuning on cell detection. Inspired by the recent success of masked image modeling, we additionally mask out cell parts and train to reconstruct these parts to further enrich the learned representations. We compare our pre-training method with self-supervised frameworks including contrastive learning (SimCLR), masked autoencoders (MAEs), and edge-based self-supervision. We build upon our previous work and train hybrid models for cell detection, which contain both convolutional and vision transformer modules. Our pre-training method can outperform SimCLR, MAE-like masked image modeling, and edge-based self-supervision when pre-training on a diverse set of six fluorescence microscopy datasets. Code is available at: https://github.com/roydenwa/cell-centroid-former