 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Road Ahead in Autonomous Driving: The KITScenes Multimodal Dataset
Jun 01, 2026Existing autonomous driving datasets have enabled major progress, but fall short in sensor fidelity, map completeness, or geographic diversity. We present KITScenes Multimodal, a European dataset built around high-fidelity sensors and maps. Our fully synchronized sensor suite combines high-resolution global-shutter cameras, long-range lidar beyond 400m, 4D imaging radar, and redundant GNSS/INS localization. Our HD maps are, to our knowledge, the most complete of any sensor dataset, validated through autonomous driving trials on open-source software. For the first time in a public dataset, all driving-relevant traffic elements, such as traffic lights, are mapped in 3D to a reprojection-accurate level with full topological connectivity. Recorded in cities with irregular street layouts and mixed traffic modes, our dataset complements existing datasets by broadening the available geographic diversity. We also introduce four benchmarks, each advancing spatial learning for embodied AI: online HD map construction, long-range depth estimation, novel view synthesis, and end-to-end driving. Project page: https://kitscenes.com/
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
Mar 24, 2026In real-world domains such as self-driving, generalization to rare scenarios remains a fundamental challenge. To address this, we introduce a new dataset designed for end-to-end driving that focuses on long-tail driving events. We provide multi-view video data, trajectories, high-level instructions, and detailed reasoning traces, facilitating in-context learning and few-shot generalization. The resulting benchmark for multimodal models, such as VLMs and VLAs, goes beyond safety and comfort metrics by evaluating instruction following and semantic coherence between model outputs. The multilingual reasoning traces in English, Spanish, and Chinese are from domain experts with diverse cultural backgrounds. Thus, our dataset is a unique resource for studying how different forms of reasoning affect driving competence. Our dataset is available at: https://hf.co/datasets/kit-mrt/kitscenes-longtail
RetroMotion: Retrocausal Motion Forecasting Models are Instructable
May 26, 2025Motion forecasts of road users (i.e., agents) vary in complexity as a function of scene constraints and interactive behavior. We address this with a multi-task learning method for motion forecasting that includes a retrocausal flow of information. The corresponding tasks are to forecast (1) marginal trajectory distributions for all modeled agents and (2) joint trajectory distributions for interacting agents. Using a transformer model, we generate the joint distributions by re-encoding marginal distributions followed by pairwise modeling. This incorporates a retrocausal flow of information from later points in marginal trajectories to earlier points in joint trajectories. Per trajectory point, we model positional uncertainty using compressed exponential power distributions. Notably, our method achieves state-of-the-art results in the Waymo Interaction Prediction dataset and generalizes well to the Argoverse 2 dataset. Additionally, our method provides an interface for issuing instructions through trajectory modifications. Our experiments show that regular training of motion forecasting leads to the ability to follow goal-based instructions and to adapt basic directional instructions to the scene context. Code: https://github.com/kit-mrt/future-motion
SceneMotion: From Agent-Centric Embeddings to Scene-Wide Forecasts
Aug 02, 2024



Self-driving vehicles rely on multimodal motion forecasts to effectively interact with their environment and plan safe maneuvers. We introduce SceneMotion, an attention-based model for forecasting scene-wide motion modes of multiple traffic agents. Our model transforms local agent-centric embeddings into scene-wide forecasts using a novel latent context module. This module learns a scene-wide latent space from multiple agent-centric embeddings, enabling joint forecasting and interaction modeling. The competitive performance in the Waymo Open Interaction Prediction Challenge demonstrates the effectiveness of our approach. Moreover, we cluster future waypoints in time and space to quantify the interaction between agents. We merge all modes and analyze each mode independently to determine which clusters are resolved through interaction or result in conflict. Our implementation is available at: https://github.com/kit-mrt/future-motion
JointMotion: Joint Self-supervision for Joint Motion Prediction
Mar 08, 2024



We present JointMotion, a self-supervised learning method for joint motion prediction in autonomous driving. Our method includes a scene-level objective connecting motion and environments, and an instance-level objective to refine learned representations. Our evaluations show that these objectives are complementary and outperform recent contrastive and autoencoding methods as pre-training for joint motion prediction. Furthermore, JointMotion adapts to all common types of environment representations used for motion prediction (i.e., agent-centric, scene-centric, and pairwise relative), and enables effective transfer learning between the Waymo Open Motion and the Argoverse 2 Forecasting datasets. Notably, our method improves the joint final displacement error of Wayformer, Scene Transformer, and HPTR by 3%, 7%, and 11%, respectively.
Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach
Feb 05, 2020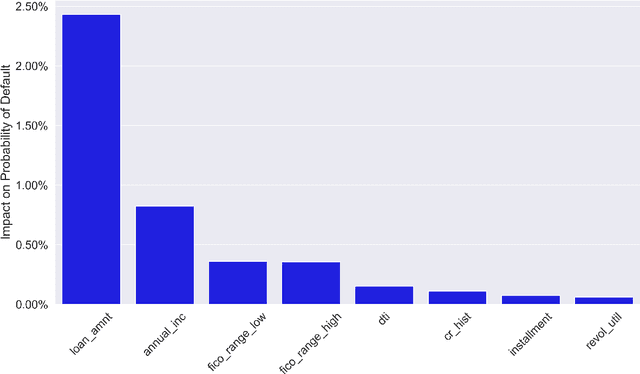


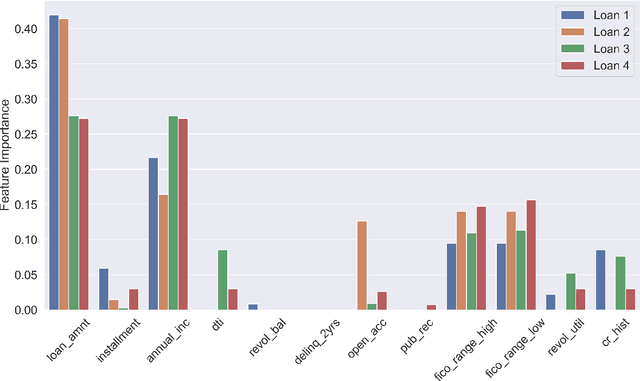
Lack of understanding of the decisions made by model-based AI systems is an important barrier for their adoption. We examine counterfactual explanations as an alternative for explaining AI decisions. The counterfactual approach defines an explanation as a set of the system's data inputs that causally drives the decision (meaning that removing them changes the decision) and is irreducible (meaning that removing any subset of the inputs in the explanation does not change the decision). We generalize previous work on counterfactual explanations, resulting in a framework that (a) is model-agnostic, (b) can address features with arbitrary data types, (c) can explain decisions made by complex AI systems that incorporate multiple models, and (d) is scalable to large numbers of features. We also propose a heuristic procedure to find the most useful explanations depending on the context. We contrast counterfactual explanations with another alternative: methods that explain model predictions by weighting features according to their importance (e.g., SHAP, LIME). This paper presents two fundamental reasons why explaining model predictions is not the same as explaining the decisions made using those predictions, suggesting we should carefully consider whether importance-weight explanations are well-suited to explain decisions made by AI systems. Specifically, we show that (1) features that have a large importance weight for a model prediction may not actually affect the corresponding decision, and (2) importance weights are insufficient to communicate whether and how features influence system decisions. We demonstrate this with several examples, including three detailed case studies that compare the counterfactual approach with SHAP to illustrate various conditions under which counterfactual explanations explain data-driven decisions better than feature importance weights.