 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach
Paper and Code
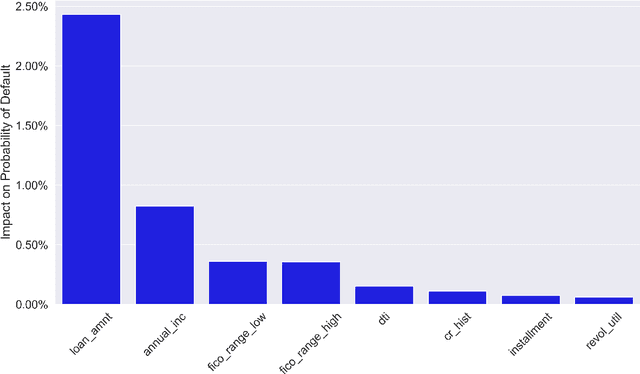


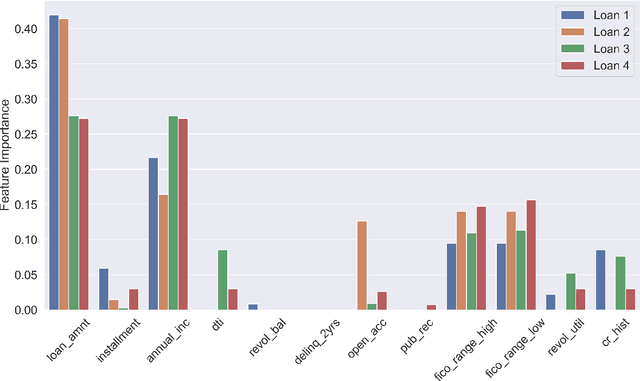
Lack of understanding of the decisions made by model-based AI systems is an important barrier for their adoption. We examine counterfactual explanations as an alternative for explaining AI decisions. The counterfactual approach defines an explanation as a set of the system's data inputs that causally drives the decision (meaning that removing them changes the decision) and is irreducible (meaning that removing any subset of the inputs in the explanation does not change the decision). We generalize previous work on counterfactual explanations, resulting in a framework that (a) is model-agnostic, (b) can address features with arbitrary data types, (c) can explain decisions made by complex AI systems that incorporate multiple models, and (d) is scalable to large numbers of features. We also propose a heuristic procedure to find the most useful explanations depending on the context. We contrast counterfactual explanations with another alternative: methods that explain model predictions by weighting features according to their importance (e.g., SHAP, LIME). This paper presents two fundamental reasons why explaining model predictions is not the same as explaining the decisions made using those predictions, suggesting we should carefully consider whether importance-weight explanations are well-suited to explain decisions made by AI systems. Specifically, we show that (1) features that have a large importance weight for a model prediction may not actually affect the corresponding decision, and (2) importance weights are insufficient to communicate whether and how features influence system decisions. We demonstrate this with several examples, including three detailed case studies that compare the counterfactual approach with SHAP to illustrate various conditions under which counterfactual explanations explain data-driven decisions better than feature importance weights.