 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoad Barlow Twins: Redundancy Reduction for Road Environment Descriptors and Motion Prediction
Jun 19, 2023



Anticipating the future motion of traffic agents is vital for self-driving vehicles to ensure their safe operation. We introduce a novel self-supervised pre-training method as well as a transformer model for motion prediction. Our method is based on Barlow Twins and applies the redundancy reduction principle to embeddings generated from HD maps. Additionally, we introduce a novel approach for redundancy reduction, where a potentially large and variable set of road environment tokens is transformed into a fixed-size set of road environment descriptors (RED). Our experiments reveal that the proposed pre-training method can improve minADE and minFDE by 12% and 15% and outperform contrastive learning with PreTraM and SimCLR in a semi-supervised setting. Our REDMotion model achieves results that are competitive with those of recent related methods such as MultiPath++ or Scene Transformer. Code is available at: https://github.com/kit-mrt/road-barlow-twins
MaskedFusion360: Reconstruct LiDAR Data by Querying Camera Features
Jun 12, 2023



In self-driving applications, LiDAR data provides accurate information about distances in 3D but lacks the semantic richness of camera data. Therefore, state-of-the-art methods for perception in urban scenes fuse data from both sensor types. In this work, we introduce a novel self-supervised method to fuse LiDAR and camera data for self-driving applications. We build upon masked autoencoders (MAEs) and train deep learning models to reconstruct masked LiDAR data from fused LiDAR and camera features. In contrast to related methods that use birds-eye-view representations, we fuse features from dense spherical LiDAR projections and features from fish-eye camera crops with a similar field of view. Therefore, we reduce the learned spatial transformations to moderate perspective transformations and do not require additional modules to generate dense LiDAR representations. Code is available at: https://github.com/KIT-MRT/masked-fusion-360
Self-supervised Pseudo-colorizing of Masked Cells
Feb 12, 2023Self-supervised learning, which is strikingly referred to as the dark matter of intelligence, is gaining more attention in biomedical applications of deep learning. In this work, we introduce a novel self-supervision objective for the analysis of cells in biomedical microscopy images. We propose training deep learning models to pseudo-colorize masked cells. We use a physics-informed pseudo-spectral colormap that is well suited for colorizing cell topology. Our experiments reveal that approximating semantic segmentation by pseudo-colorization is beneficial for subsequent fine-tuning on cell detection. Inspired by the recent success of masked image modeling, we additionally mask out cell parts and train to reconstruct these parts to further enrich the learned representations. We compare our pre-training method with self-supervised frameworks including contrastive learning (SimCLR), masked autoencoders (MAEs), and edge-based self-supervision. We build upon our previous work and train hybrid models for cell detection, which contain both convolutional and vision transformer modules. Our pre-training method can outperform SimCLR, MAE-like masked image modeling, and edge-based self-supervision when pre-training on a diverse set of six fluorescence microscopy datasets. Code is available at: https://github.com/roydenwa/cell-centroid-former
Risk-Aware High-level Decisions for Automated Driving at Occluded Intersections with Reinforcement Learning
Apr 09, 2020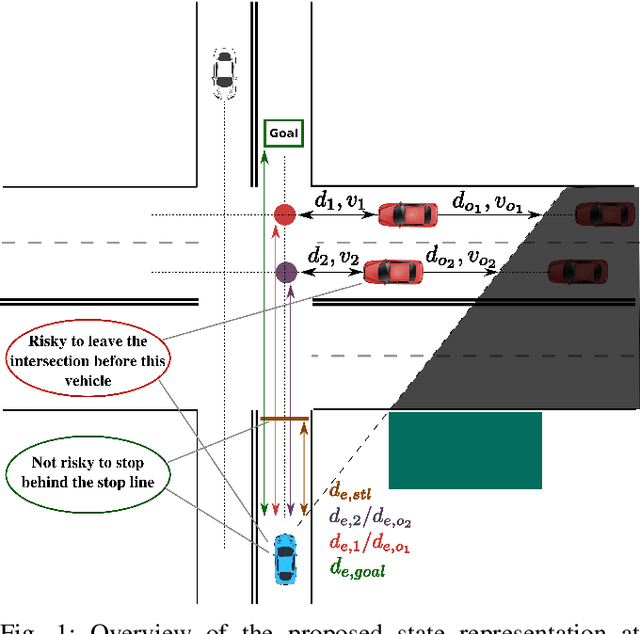
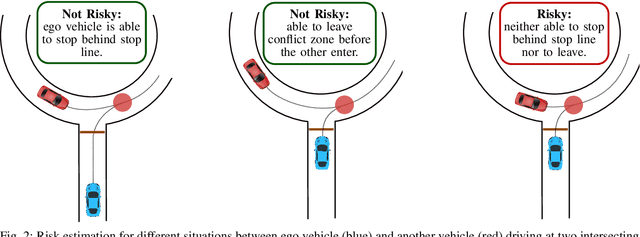
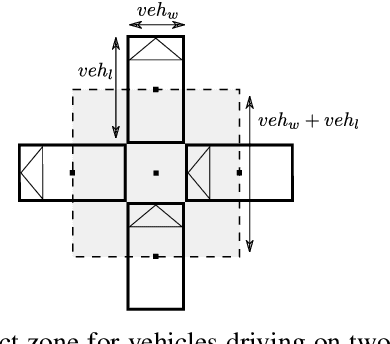
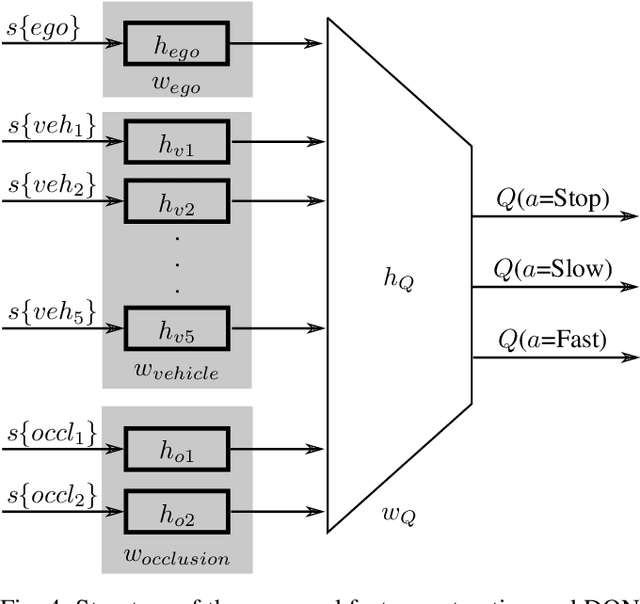
Reinforcement learning is nowadays a popular framework for solving different decision making problems in automated driving. However, there are still some remaining crucial challenges that need to be addressed for providing more reliable policies. In this paper, we propose a generic risk-aware DQN approach in order to learn high level actions for driving through unsignalized occluded intersections. The proposed state representation provides lane based information which allows to be used for multi-lane scenarios. Moreover, we propose a risk based reward function which punishes risky situations instead of only collision failures. Such rewarding approach helps to incorporate risk prediction into our deep Q network and learn more reliable policies which are safer in challenging situations. The efficiency of the proposed approach is compared with a DQN learned with conventional collision based rewarding scheme and also with a rule-based intersection navigation policy. Evaluation results show that the proposed approach outperforms both of these methods. It provides safer actions than collision-aware DQN approach and is less overcautious than the rule-based policy.