 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance-to-Distance Ratio: A Similarity Measure for Sentences Based on Rate of Change in LLM Embeddings
Jan 25, 2026A measure of similarity between text embeddings can be considered adequate only if it adheres to the human perception of similarity between texts. In this paper, we introduce the distance-to-distance ratio (DDR), a novel measure of similarity between LLM sentence embeddings. Inspired by Lipschitz continuity, DDR measures the rate of change in similarity between the pre-context word embeddings and the similarity between post-context LLM embeddings, thus measuring the semantic influence of context. We evaluate the performance of DDR in experiments designed as a series of perturbations applied to sentences drawn from a sentence dataset. For each sentence, we generate variants by replacing one, two, or three words with either synonyms, which constitute semantically similar text, or randomly chosen words, which constitute semantically dissimilar text. We compare the performance of DDR with other prevailing similarity metrics and demonstrate that DDR consistently provides finer discrimination between semantically similar and dissimilar texts, even under minimal, controlled edits.
Extensional Properties of Recurrent Neural Networks
Oct 30, 2024A property of a recurrent neural network (RNN) is called \emph{extensional} if, loosely speaking, it is a property of the function computed by the RNN rather than a property of the RNN algorithm. Many properties of interest in RNNs are extensional, for example, robustness against small changes of input or good clustering of inputs. Given an RNN, it is natural to ask whether it has such a property. We give a negative answer to the general question about testing extensional properties of RNNs. Namely, we prove a version of Rice's theorem for RNNs: any nontrivial extensional property of RNNs is undecidable.
OSSA: Unsupervised One-Shot Style Adaptation
Oct 01, 2024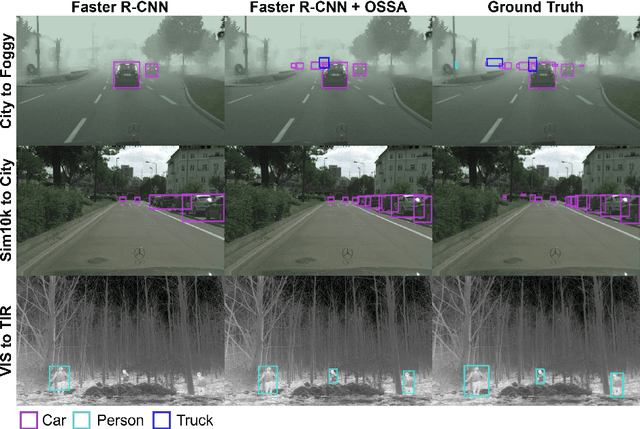
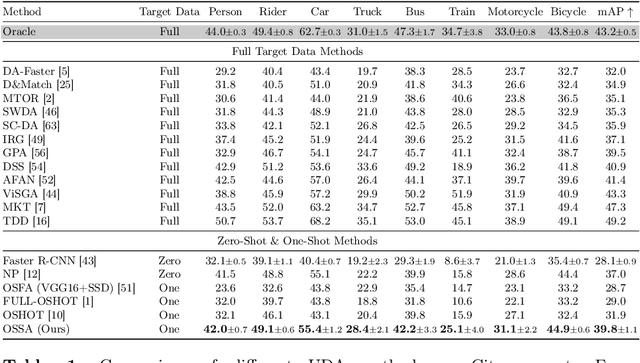
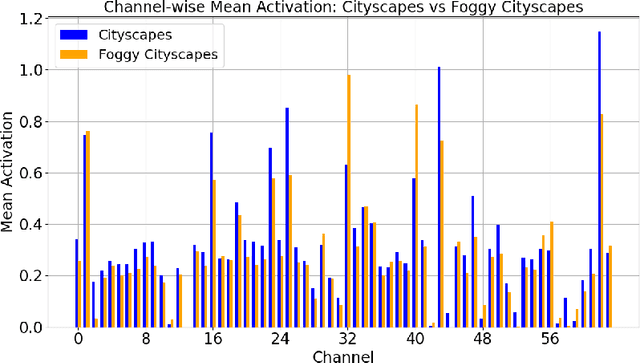
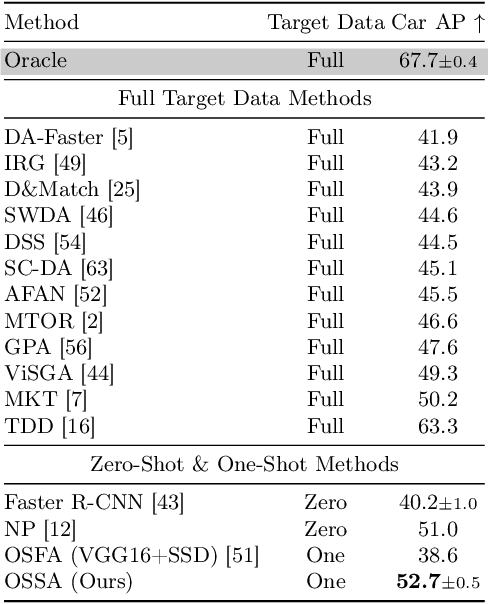
Despite their success in various vision tasks, deep neural network architectures often underperform in out-of-distribution scenarios due to the difference between training and target domain style. To address this limitation, we introduce One-Shot Style Adaptation (OSSA), a novel unsupervised domain adaptation method for object detection that utilizes a single, unlabeled target image to approximate the target domain style. Specifically, OSSA generates diverse target styles by perturbing the style statistics derived from a single target image and then applies these styles to a labeled source dataset at the feature level using Adaptive Instance Normalization (AdaIN). Extensive experiments show that OSSA establishes a new state-of-the-art among one-shot domain adaptation methods by a significant margin, and in some cases, even outperforms strong baselines that use thousands of unlabeled target images. By applying OSSA in various scenarios, including weather, simulated-to-real (sim2real), and visual-to-thermal adaptations, our study explores the overarching significance of the style gap in these contexts. OSSA's simplicity and efficiency allow easy integration into existing frameworks, providing a potentially viable solution for practical applications with limited data availability. Code is available at https://github.com/RobinGerster7/OSSA
Utilizing Grounded SAM for self-supervised frugal camouflaged human detection
Jun 09, 2024Visually detecting camouflaged objects is a hard problem for both humans and computer vision algorithms. Strong similarities between object and background appearance make the task significantly more challenging than traditional object detection or segmentation tasks. Current state-of-the-art models use either convolutional neural networks or vision transformers as feature extractors. They are trained in a fully supervised manner and thus need a large amount of labeled training data. In this paper, both self-supervised and frugal learning methods are introduced to the task of Camouflaged Object Detection (COD). The overall goal is to fine-tune two COD reference methods, namely SINet-V2 and HitNet, pre-trained for camouflaged animal detection to the task of camouflaged human detection. Therefore, we use the public dataset CPD1K that contains camouflaged humans in a forest environment. We create a strong baseline using supervised frugal transfer learning for the fine-tuning task. Then, we analyze three pseudo-labeling approaches to perform the fine-tuning task in a self-supervised manner. Our experiments show that we achieve similar performance by pure self-supervision compared to fully supervised frugal learning.
An AlphaZero-Inspired Approach to Solving Search Problems
Jul 02, 2022AlphaZero and its extension MuZero are computer programs that use machine-learning techniques to play at a superhuman level in chess, go, and a few other games. They achieved this level of play solely with reinforcement learning from self-play, without any domain knowledge except the game rules. It is a natural idea to adapt the methods and techniques used in AlphaZero for solving search problems such as the Boolean satisfiability problem (in its search version). Given a search problem, how to represent it for an AlphaZero-inspired solver? What are the "rules of solving" for this search problem? We describe possible representations in terms of easy-instance solvers and self-reductions, and we give examples of such representations for the satisfiability problem. We also describe a version of Monte Carlo tree search adapted for search problems.
Anchor-free Small-scale Multispectral Pedestrian Detection
Aug 20, 2020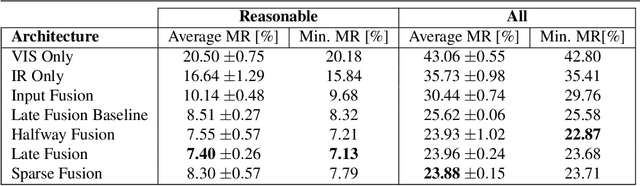

Multispectral images consisting of aligned visual-optical (VIS) and thermal infrared (IR) image pairs are well-suited for practical applications like autonomous driving or visual surveillance. Such data can be used to increase the performance of pedestrian detection especially for weakly illuminated, small-scaled, or partially occluded instances. The current state-of-the-art is based on variants of Faster R-CNN and thus passes through two stages: a proposal generator network with handcrafted anchor boxes for object localization and a classification network for verifying the object category. In this paper we propose a method for effective and efficient multispectral fusion of the two modalities in an adapted single-stage anchor-free base architecture. We aim at learning pedestrian representations based on object center and scale rather than direct bounding box predictions. In this way, we can both simplify the network architecture and achieve higher detection performance, especially for pedestrians under occlusion or at low object resolution. In addition, we provide a study on well-suited multispectral data augmentation techniques that improve the commonly used augmentations. The results show our method's effectiveness in detecting small-scaled pedestrians. We achieve 5.68% log-average miss rate in comparison to the best current state-of-the-art of 7.49% (25% improvement) on the challenging KAIST Multispectral Pedestrian Detection Benchmark. Code: https://github.com/HensoldtOptronicsCV/MultispectralPedestrianDetection