 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor-free Small-scale Multispectral Pedestrian Detection
Paper and Code
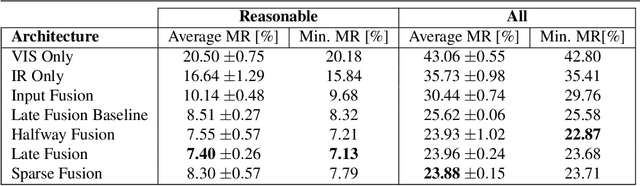

Multispectral images consisting of aligned visual-optical (VIS) and thermal infrared (IR) image pairs are well-suited for practical applications like autonomous driving or visual surveillance. Such data can be used to increase the performance of pedestrian detection especially for weakly illuminated, small-scaled, or partially occluded instances. The current state-of-the-art is based on variants of Faster R-CNN and thus passes through two stages: a proposal generator network with handcrafted anchor boxes for object localization and a classification network for verifying the object category. In this paper we propose a method for effective and efficient multispectral fusion of the two modalities in an adapted single-stage anchor-free base architecture. We aim at learning pedestrian representations based on object center and scale rather than direct bounding box predictions. In this way, we can both simplify the network architecture and achieve higher detection performance, especially for pedestrians under occlusion or at low object resolution. In addition, we provide a study on well-suited multispectral data augmentation techniques that improve the commonly used augmentations. The results show our method's effectiveness in detecting small-scaled pedestrians. We achieve 5.68% log-average miss rate in comparison to the best current state-of-the-art of 7.49% (25% improvement) on the challenging KAIST Multispectral Pedestrian Detection Benchmark. Code: https://github.com/HensoldtOptronicsCV/MultispectralPedestrianDetection