 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Estimation of Transformers' Predictions via Topological Analysis of the Attention Matrices
Aug 22, 2023Determining the degree of confidence of deep learning model in its prediction is an open problem in the field of natural language processing. Most of the classical methods for uncertainty estimation are quite weak for text classification models. We set the task of obtaining an uncertainty estimate for neural networks based on the Transformer architecture. A key feature of such mo-dels is the attention mechanism, which supports the information flow between the hidden representations of tokens in the neural network. We explore the formed relationships between internal representations using Topological Data Analysis methods and utilize them to predict model's confidence. In this paper, we propose a method for uncertainty estimation based on the topological properties of the attention mechanism and compare it with classical methods. As a result, the proposed algorithm surpasses the existing methods in quality and opens up a new area of application of the attention mechanism, but requires the selection of topological features.
Intrinsic Dimension Estimation for Robust Detection of AI-Generated Texts
Jun 07, 2023



Rapidly increasing quality of AI-generated content makes it difficult to distinguish between human and AI-generated texts, which may lead to undesirable consequences for society. Therefore, it becomes increasingly important to study the properties of human texts that are invariant over text domains and various proficiency of human writers, can be easily calculated for any language, and can robustly separate natural and AI-generated texts regardless of the generation model and sampling method. In this work, we propose such an invariant of human texts, namely the intrinsic dimensionality of the manifold underlying the set of embeddings of a given text sample. We show that the average intrinsic dimensionality of fluent texts in natural language is hovering around the value $9$ for several alphabet-based languages and around $7$ for Chinese, while the average intrinsic dimensionality of AI-generated texts for each language is $\approx 1.5$ lower, with a clear statistical separation between human-generated and AI-generated distributions. This property allows us to build a score-based artificial text detector. The proposed detector's accuracy is stable over text domains, generator models, and human writer proficiency levels, outperforming SOTA detectors in model-agnostic and cross-domain scenarios by a significant margin.
Learning Topology-Preserving Data Representations
Feb 15, 2023



We propose a method for learning topology-preserving data representations (dimensionality reduction). The method aims to provide topological similarity between the data manifold and its latent representation via enforcing the similarity in topological features (clusters, loops, 2D voids, etc.) and their localization. The core of the method is the minimization of the Representation Topology Divergence (RTD) between original high-dimensional data and low-dimensional representation in latent space. RTD minimization provides closeness in topological features with strong theoretical guarantees. We develop a scheme for RTD differentiation and apply it as a loss term for the autoencoder. The proposed method "RTD-AE" better preserves the global structure and topology of the data manifold than state-of-the-art competitors as measured by linear correlation, triplet distance ranking accuracy, and Wasserstein distance between persistence barcodes.
Topological Data Analysis for Speech Processing
Dec 02, 2022



We apply topological data analysis (TDA) to speech classification problems and to the introspection of a pretrained speech model, HuBERT. To this end, we introduce a number of topological and algebraic features derived from Transformer attention maps and embeddings. We show that a simple linear classifier built on top of such features outperforms a fine-tuned classification head. In particular, we achieve an improvement of about $9\%$ accuracy and $5\%$ ERR on four common datasets; on CREMA-D, the proposed feature set reaches a new state of the art performance with accuracy $80.155$. We also show that topological features are able to reveal functional roles of speech Transformer heads; e.g., we find the heads capable to distinguish between pairs of sample sources (natural/synthetic) or voices without any downstream fine-tuning. Our results demonstrate that TDA is a promising new approach for speech analysis, especially for tasks that require structural prediction. Appendices, an introduction to TDA, and other additional materials are available here - https://topohubert.github.io/speech-topology-webpages/
Acceptability Judgements via Examining the Topology of Attention Maps
May 19, 2022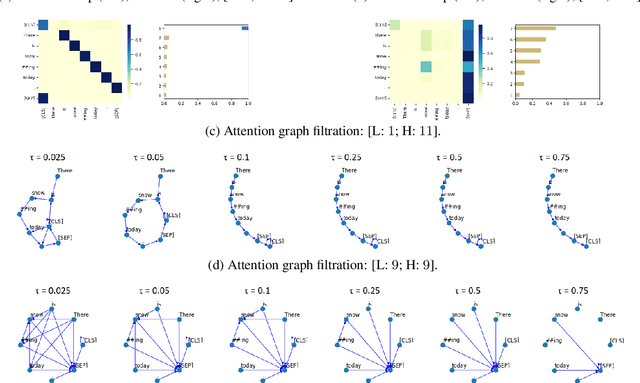
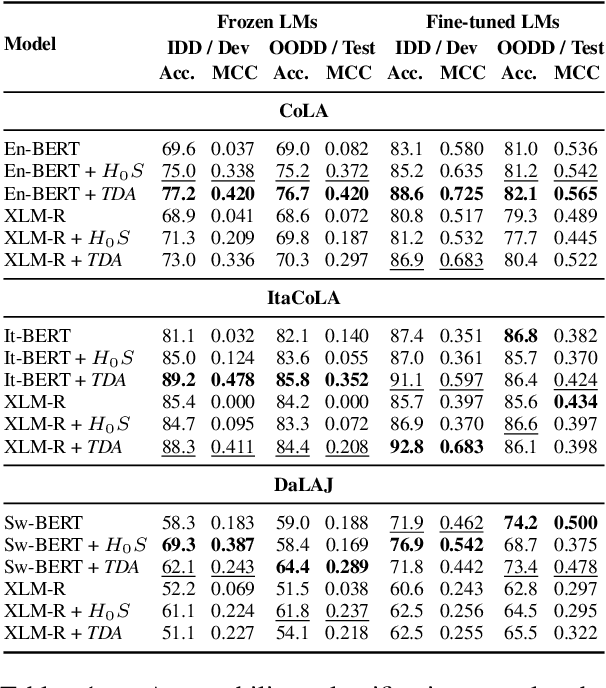
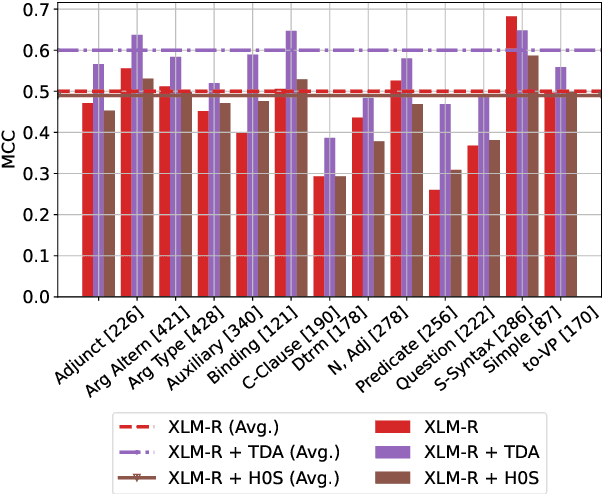
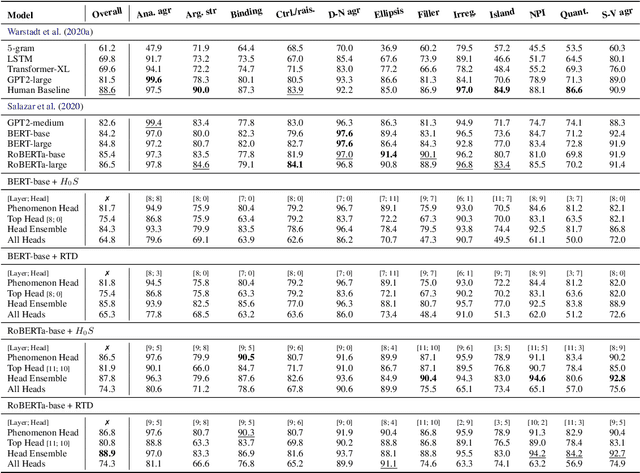
The role of the attention mechanism in encoding linguistic knowledge has received special interest in NLP. However, the ability of the attention heads to judge the grammatical acceptability of a sentence has been underexplored. This paper approaches the paradigm of acceptability judgments with topological data analysis (TDA), showing that the geometric properties of the attention graph can be efficiently exploited for two standard practices in linguistics: binary judgments and linguistic minimal pairs. Topological features enhance the BERT-based acceptability classifier scores by $8$%-$24$% on CoLA in three languages (English, Italian, and Swedish). By revealing the topological discrepancy between attention maps of minimal pairs, we achieve the human-level performance on the BLiMP benchmark, outperforming nine statistical and Transformer LM baselines. At the same time, TDA provides the foundation for analyzing the linguistic functions of attention heads and interpreting the correspondence between the graph features and grammatical phenomena.
Artificial Text Detection via Examining the Topology of Attention Maps
Sep 10, 2021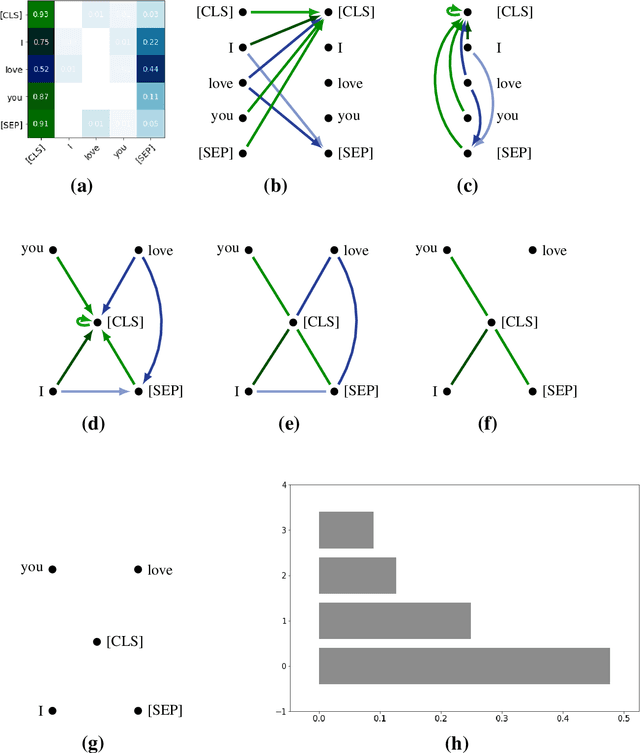
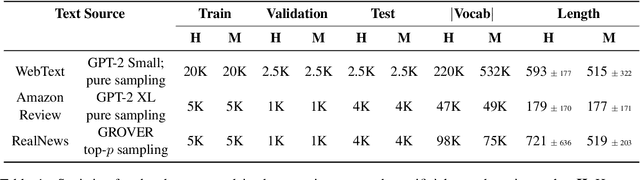
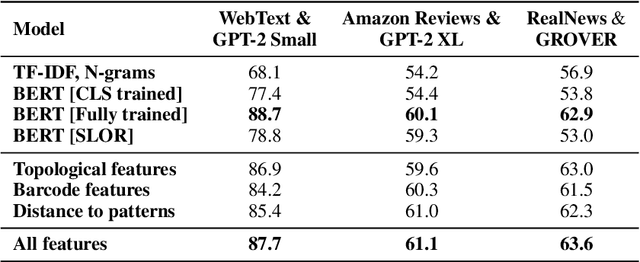
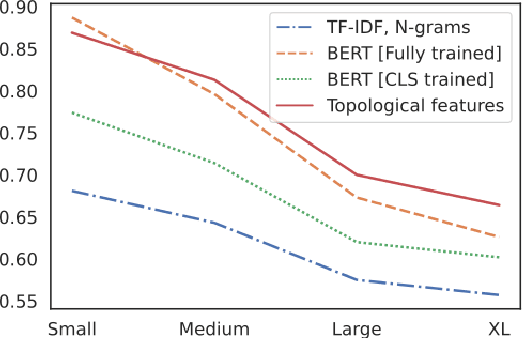
The impressive capabilities of recent generative models to create texts that are challenging to distinguish from the human-written ones can be misused for generating fake news, product reviews, and even abusive content. Despite the prominent performance of existing methods for artificial text detection, they still lack interpretability and robustness towards unseen models. To this end, we propose three novel types of interpretable topological features for this task based on Topological Data Analysis (TDA) which is currently understudied in the field of NLP. We empirically show that the features derived from the BERT model outperform count- and neural-based baselines up to 10\% on three common datasets, and tend to be the most robust towards unseen GPT-style generation models as opposed to existing methods. The probing analysis of the features reveals their sensitivity to the surface and syntactic properties. The results demonstrate that TDA is a promising line with respect to NLP tasks, specifically the ones that incorporate surface and structural information.