 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentanglement Learning via Topology
Aug 24, 2023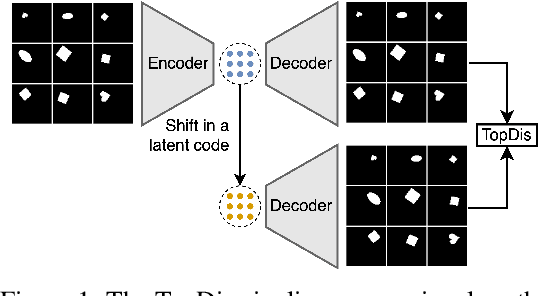
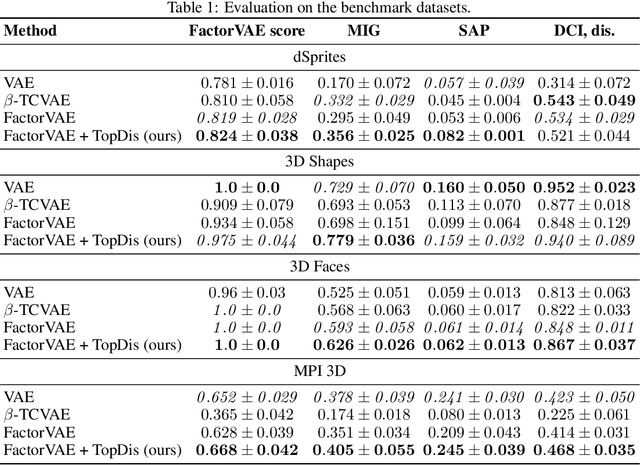
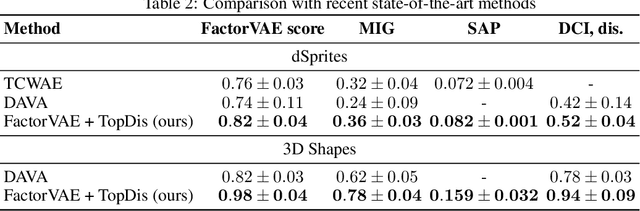
We propose TopDis (Topological Disentanglement), a method for learning disentangled representations via adding multi-scale topological loss term. Disentanglement is a crucial property of data representations substantial for the explainability and robustness of deep learning models and a step towards high-level cognition. The state-of-the-art method based on VAE minimizes the total correlation of the joint distribution of latent variables. We take a different perspective on disentanglement by analyzing topological properties of data manifolds. In particular, we optimize the topological similarity for data manifolds traversals. To the best of our knowledge, our paper is the first one to propose a differentiable topological loss for disentanglement. Our experiments have shown that the proposed topological loss improves disentanglement scores such as MIG, FactorVAE score, SAP score and DCI disentanglement score with respect to state-of-the-art results. Our method works in an unsupervised manner, permitting to apply it for problems without labeled factors of variation. Additionally, we show how to use the proposed topological loss to find disentangled directions in a trained GAN.
Learning Topology-Preserving Data Representations
Feb 15, 2023We propose a method for learning topology-preserving data representations (dimensionality reduction). The method aims to provide topological similarity between the data manifold and its latent representation via enforcing the similarity in topological features (clusters, loops, 2D voids, etc.) and their localization. The core of the method is the minimization of the Representation Topology Divergence (RTD) between original high-dimensional data and low-dimensional representation in latent space. RTD minimization provides closeness in topological features with strong theoretical guarantees. We develop a scheme for RTD differentiation and apply it as a loss term for the autoencoder. The proposed method "RTD-AE" better preserves the global structure and topology of the data manifold than state-of-the-art competitors as measured by linear correlation, triplet distance ranking accuracy, and Wasserstein distance between persistence barcodes.
Data-Driven Short-Term Daily Operational Sea Ice Regional Forecasting
Oct 17, 2022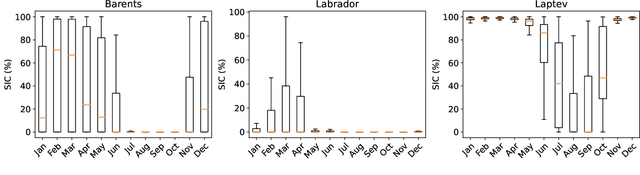
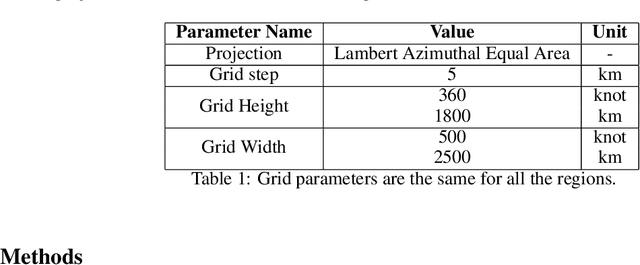
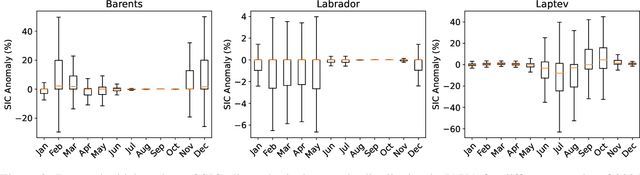

Global warming made the Arctic available for marine operations and created demand for reliable operational sea ice forecasts to make them safe. While ocean-ice numerical models are highly computationally intensive, relatively lightweight ML-based methods may be more efficient in this task. Many works have exploited different deep learning models alongside classical approaches for predicting sea ice concentration in the Arctic. However, only a few focus on daily operational forecasts and consider the real-time availability of data they need for operation. In this work, we aim to close this gap and investigate the performance of the U-Net model trained in two regimes for predicting sea ice for up to the next 10 days. We show that this deep learning model can outperform simple baselines by a significant margin and improve its quality by using additional weather data and training on multiple regions, ensuring its generalization abilities. As a practical outcome, we build a fast and flexible tool that produces operational sea ice forecasts in the Barents Sea, the Labrador Sea, and the Laptev Sea regions.
Transfer learning for ensembles: reducing computation time and keeping the diversity
Jun 27, 2022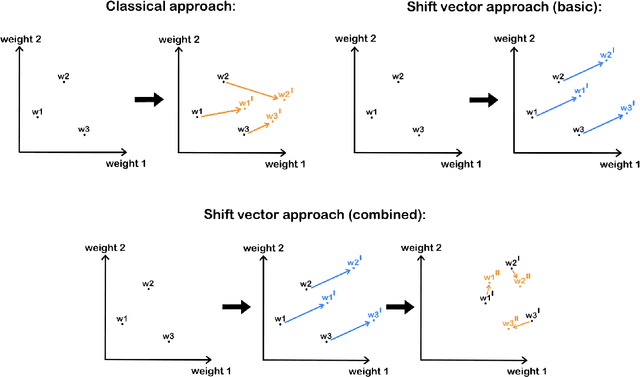


Transferring a deep neural network trained on one problem to another requires only a small amount of data and little additional computation time. The same behaviour holds for ensembles of deep learning models typically superior to a single model. However, a transfer of deep neural networks ensemble demands relatively high computational expenses. The probability of overfitting also increases. Our approach for the transfer learning of ensembles consists of two steps: (a) shifting weights of encoders of all models in the ensemble by a single shift vector and (b) doing a tiny fine-tuning for each individual model afterwards. This strategy leads to a speed-up of the training process and gives an opportunity to add models to an ensemble with significantly reduced training time using the shift vector. We compare different strategies by computation time, the accuracy of an ensemble, uncertainty estimation and disagreement and conclude that our approach gives competitive results using the same computation complexity in comparison with the traditional approach. Also, our method keeps the ensemble's models' diversity higher.
Representation Topology Divergence: A Method for Comparing Neural Network Representations
Dec 31, 2021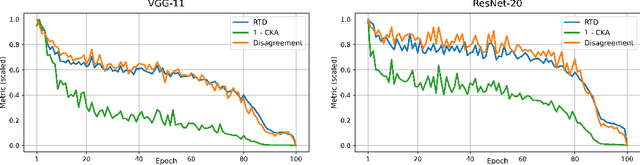
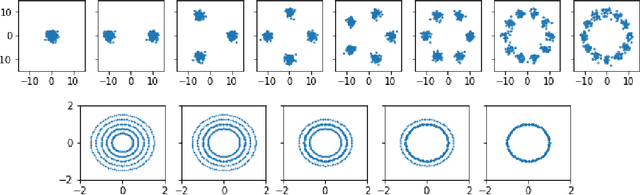


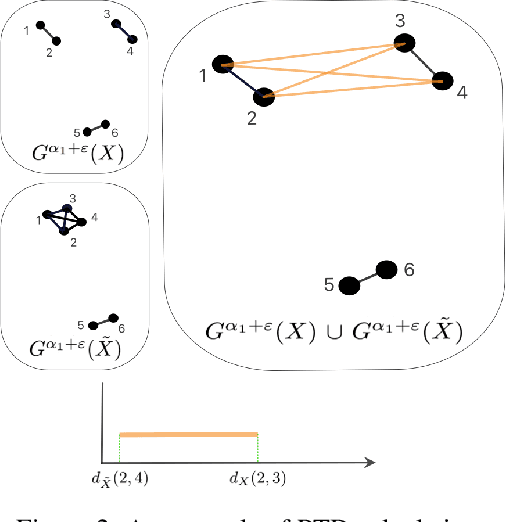
Comparison of data representations is a complex multi-aspect problem that has not enjoyed a complete solution yet. We propose a method for comparing two data representations. We introduce the Representation Topology Divergence (RTD), measuring the dissimilarity in multi-scale topology between two point clouds of equal size with a one-to-one correspondence between points. The data point clouds are allowed to lie in different ambient spaces. The RTD is one of the few TDA-based practical methods applicable to real machine learning datasets. Experiments show that the proposed RTD agrees with the intuitive assessment of data representation similarity and is sensitive to its topological structure. We apply RTD to gain insights on neural networks representations in computer vision and NLP domains for various problems: training dynamics analysis, data distribution shift, transfer learning, ensemble learning, disentanglement assessment.