 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Neural Optimal Transport Solvers Work? A Continuous Wasserstein-2 Benchmark
Jun 03, 2021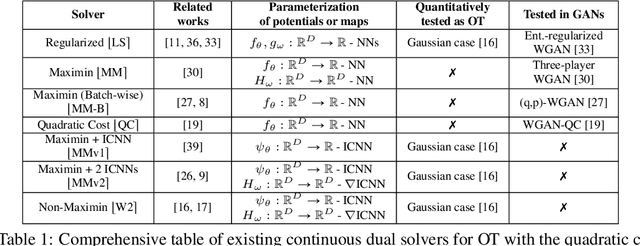
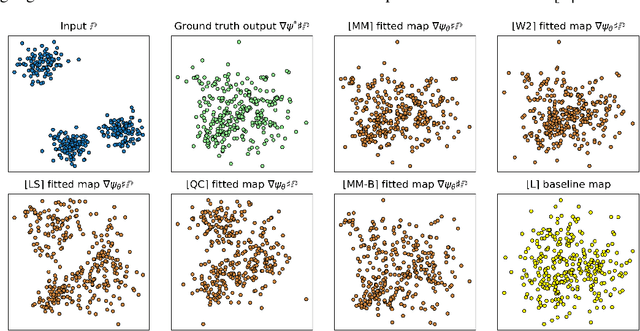
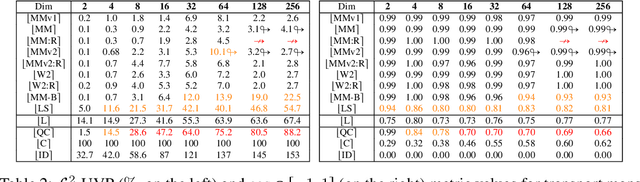

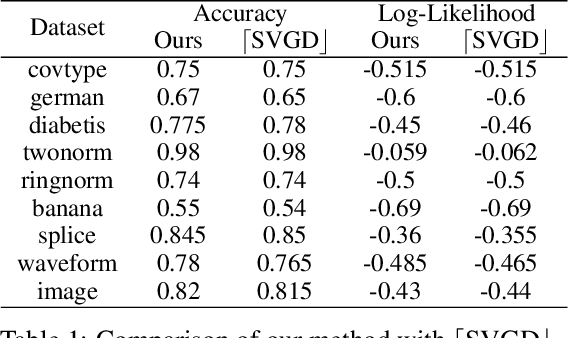
Despite the recent popularity of neural network-based solvers for optimal transport (OT), there is no standard quantitative way to evaluate their performance. In this paper, we address this issue for quadratic-cost transport -- specifically, computation of the Wasserstein-2 distance, a commonly-used formulation of optimal transport in machine learning. To overcome the challenge of computing ground truth transport maps between continuous measures needed to assess these solvers, we use input-convex neural networks (ICNN) to construct pairs of measures whose ground truth OT maps can be obtained analytically. This strategy yields pairs of continuous benchmark measures in high-dimensional spaces such as spaces of images. We thoroughly evaluate existing optimal transport solvers using these benchmark measures. Even though these solvers perform well in downstream tasks, many do not faithfully recover optimal transport maps. To investigate the cause of this discrepancy, we further test the solvers in a setting of image generation. Our study reveals crucial limitations of existing solvers and shows that increased OT accuracy does not necessarily correlate to better results downstream.
Large-Scale Wasserstein Gradient Flows
Jun 01, 2021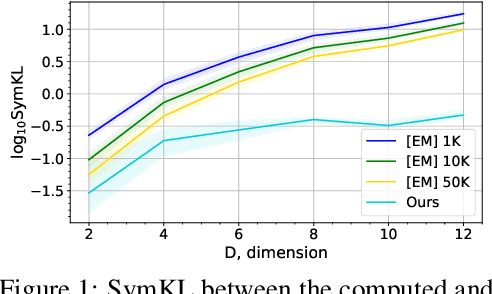
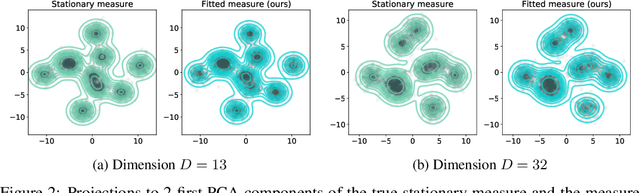
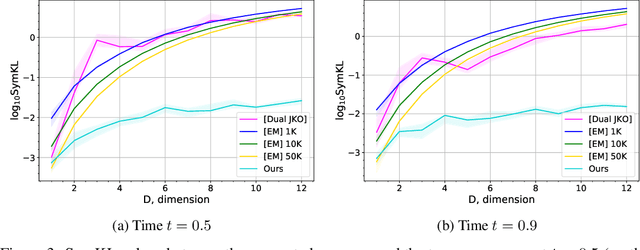
Wasserstein gradient flows provide a powerful means of understanding and solving many diffusion equations. Specifically, Fokker-Planck equations, which model the diffusion of probability measures, can be understood as gradient descent over entropy functionals in Wasserstein space. This equivalence, introduced by Jordan, Kinderlehrer and Otto, inspired the so-called JKO scheme to approximate these diffusion processes via an implicit discretization of the gradient flow in Wasserstein space. Solving the optimization problem associated to each JKO step, however, presents serious computational challenges. We introduce a scalable method to approximate Wasserstein gradient flows, targeted to machine learning applications. Our approach relies on input-convex neural networks (ICNNs) to discretize the JKO steps, which can be optimized by stochastic gradient descent. Unlike previous work, our method does not require domain discretization or particle simulation. As a result, we can sample from the measure at each time step of the diffusion and compute its probability density. We demonstrate our algorithm's performance by computing diffusions following the Fokker-Planck equation and apply it to unnormalized density sampling as well as nonlinear filtering.
Improving Approximate Optimal Transport Distances using Quantization
Feb 25, 2021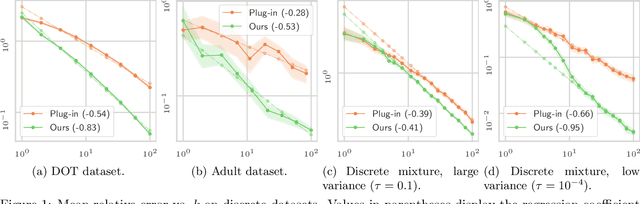
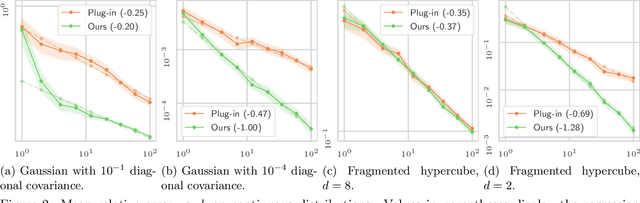
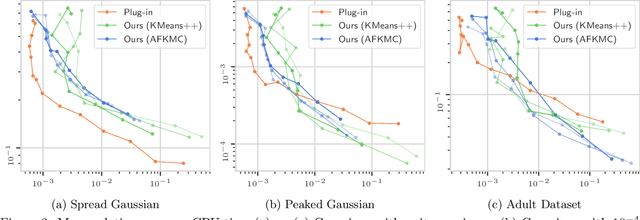
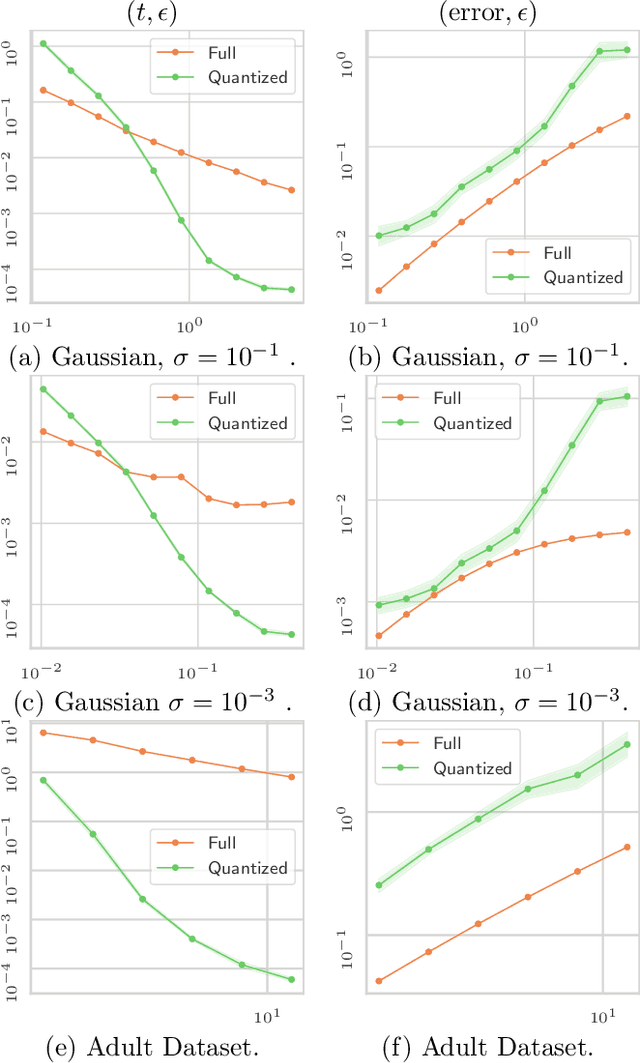
Optimal transport (OT) is a popular tool in machine learning to compare probability measures geometrically, but it comes with substantial computational burden. Linear programming algorithms for computing OT distances scale cubically in the size of the input, making OT impractical in the large-sample regime. We introduce a practical algorithm, which relies on a quantization step, to estimate OT distances between measures given cheap sample access. We also provide a variant of our algorithm to improve the performance of approximate solvers, focusing on those for entropy-regularized transport. We give theoretical guarantees on the benefits of this quantization step and display experiments showing that it behaves well in practice, providing a practical approximation algorithm that can be used as a drop-in replacement for existing OT estimators.
Continuous Regularized Wasserstein Barycenters
Aug 28, 2020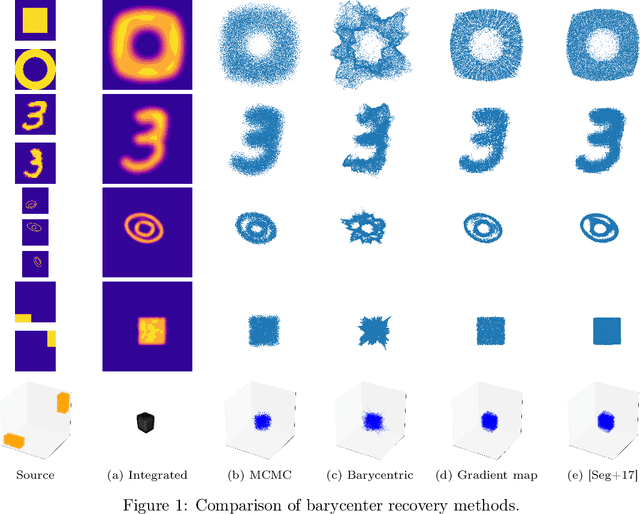

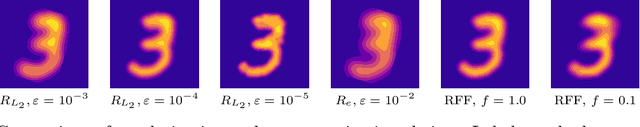

Wasserstein barycenters provide a geometrically meaningful way to aggregate probability distributions, built on the theory of optimal transport. They are difficult to compute in practice, however, leading previous work to restrict their supports to finite sets of points. Leveraging a new dual formulation for the regularized Wasserstein barycenter problem, we introduce a stochastic algorithm that constructs a continuous approximation of the barycenter. We establish strong duality and use the corresponding primal-dual relationship to parametrize the barycenter implicitly using the dual potentials of regularized transport problems. The resulting problem can be solved with stochastic gradient descent, which yields an efficient online algorithm to approximate the barycenter of continuous distributions given sample access. We demonstrate the effectiveness of our approach and compare against previous work on synthetic examples and real-world applications.
Differentiable Deep Clustering with Cluster Size Constraints
Oct 20, 2019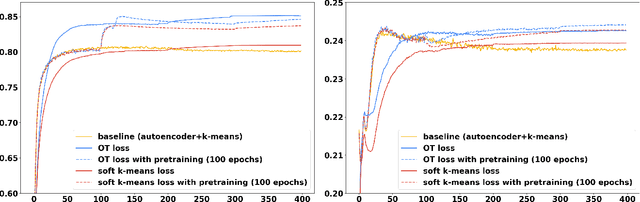
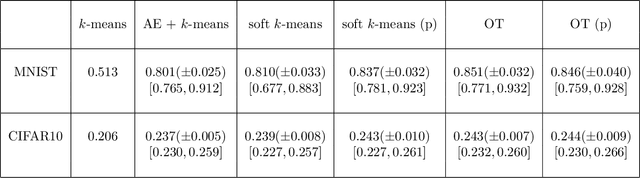
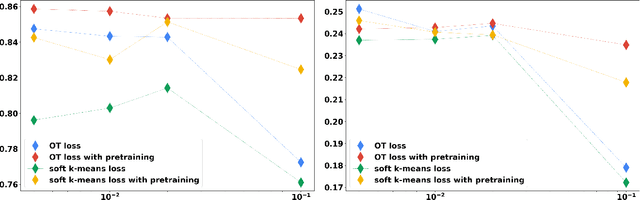
Clustering is a fundamental unsupervised learning approach. Many clustering algorithms -- such as $k$-means -- rely on the euclidean distance as a similarity measure, which is often not the most relevant metric for high dimensional data such as images. Learning a lower-dimensional embedding that can better reflect the geometry of the dataset is therefore instrumental for performance. We propose a new approach for this task where the embedding is performed by a differentiable model such as a deep neural network. By rewriting the $k$-means clustering algorithm as an optimal transport task, and adding an entropic regularization, we derive a fully differentiable loss function that can be minimized with respect to both the embedding parameters and the cluster parameters via stochastic gradient descent. We show that this new formulation generalizes a recently proposed state-of-the-art method based on soft-$k$-means by adding constraints on the cluster sizes. Empirical evaluations on image classification benchmarks suggest that compared to state-of-the-art methods, our optimal transport-based approach provide better unsupervised accuracy and does not require a pre-training phase.
Learning Generative Models with Sinkhorn Divergences
Oct 20, 2017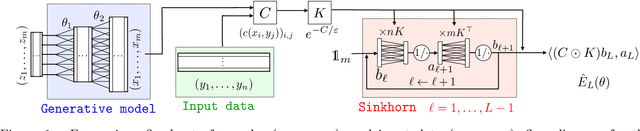
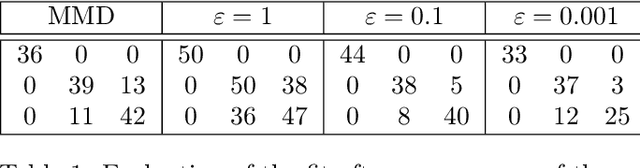
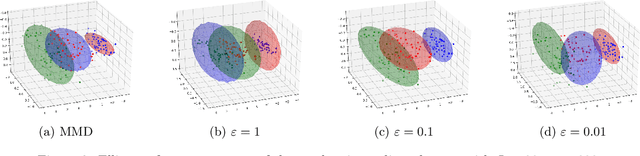

The ability to compare two degenerate probability distributions (i.e. two probability distributions supported on two distinct low-dimensional manifolds living in a much higher-dimensional space) is a crucial problem arising in the estimation of generative models for high-dimensional observations such as those arising in computer vision or natural language. It is known that optimal transport metrics can represent a cure for this problem, since they were specifically designed as an alternative to information divergences to handle such problematic scenarios. Unfortunately, training generative machines using OT raises formidable computational and statistical challenges, because of (i) the computational burden of evaluating OT losses, (ii) the instability and lack of smoothness of these losses, (iii) the difficulty to estimate robustly these losses and their gradients in high dimension. This paper presents the first tractable computational method to train large scale generative models using an optimal transport loss, and tackles these three issues by relying on two key ideas: (a) entropic smoothing, which turns the original OT loss into one that can be computed using Sinkhorn fixed point iterations; (b) algorithmic (automatic) differentiation of these iterations. These two approximations result in a robust and differentiable approximation of the OT loss with streamlined GPU execution. Entropic smoothing generates a family of losses interpolating between Wasserstein (OT) and Maximum Mean Discrepancy (MMD), thus allowing to find a sweet spot leveraging the geometry of OT and the favorable high-dimensional sample complexity of MMD which comes with unbiased gradient estimates. The resulting computational architecture complements nicely standard deep network generative models by a stack of extra layers implementing the loss function.
GAN and VAE from an Optimal Transport Point of View
Jun 06, 2017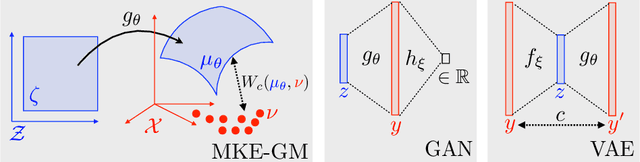
This short article revisits some of the ideas introduced in arXiv:1701.07875 and arXiv:1705.07642 in a simple setup. This sheds some lights on the connexions between Variational Autoencoders (VAE), Generative Adversarial Networks (GAN) and Minimum Kantorovitch Estimators (MKE).