 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloptiNets: Scalable Non-Convex Optimization with Certificates
Jun 26, 2023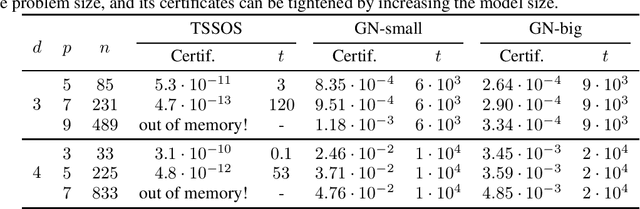
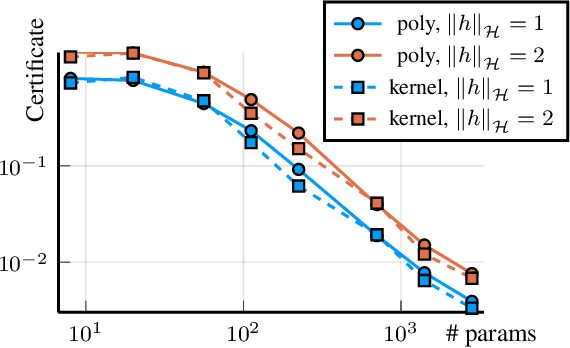
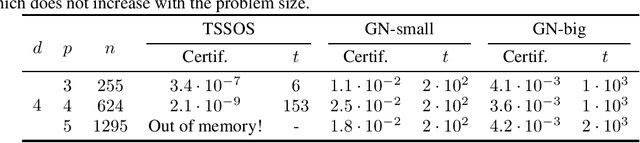
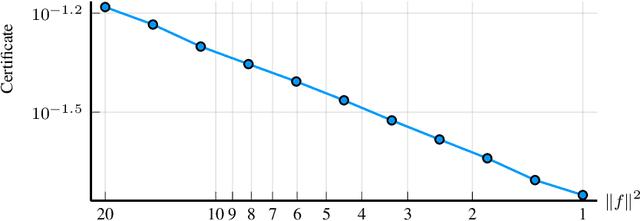
We present a novel approach to non-convex optimization with certificates, which handles smooth functions on the hypercube or on the torus. Unlike traditional methods that rely on algebraic properties, our algorithm exploits the regularity of the target function intrinsic in the decay of its Fourier spectrum. By defining a tractable family of models, we allow at the same time to obtain precise certificates and to leverage the advanced and powerful computational techniques developed to optimize neural networks. In this way the scalability of our approach is naturally enhanced by parallel computing with GPUs. Our approach, when applied to the case of polynomials of moderate dimensions but with thousands of coefficients, outperforms the state-of-the-art optimization methods with certificates, as the ones based on Lasserre's hierarchy, addressing problems intractable for the competitors.
On the Benefits of Large Learning Rates for Kernel Methods
Feb 28, 2022
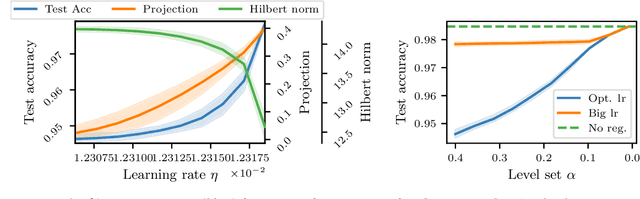

This paper studies an intriguing phenomenon related to the good generalization performance of estimators obtained by using large learning rates within gradient descent algorithms. First observed in the deep learning literature, we show that a phenomenon can be precisely characterized in the context of kernel methods, even though the resulting optimization problem is convex. Specifically, we consider the minimization of a quadratic objective in a separable Hilbert space, and show that with early stopping, the choice of learning rate influences the spectral decomposition of the obtained solution on the Hessian's eigenvectors. This extends an intuition described by Nakkiran (2020) on a two-dimensional toy problem to realistic learning scenarios such as kernel ridge regression. While large learning rates may be proven beneficial as soon as there is a mismatch between the train and test objectives, we further explain why it already occurs in classification tasks without assuming any particular mismatch between train and test data distributions.
Beyond Tikhonov: Faster Learning with Self-Concordant Losses via Iterative Regularization
Jun 16, 2021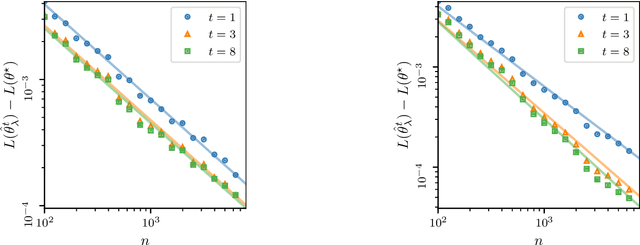
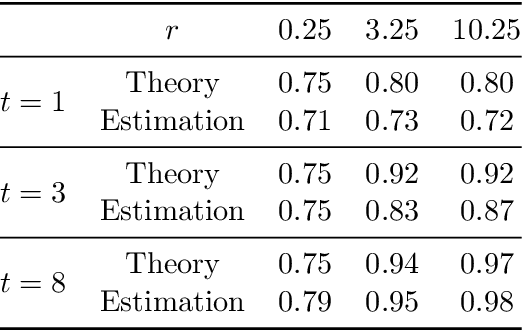

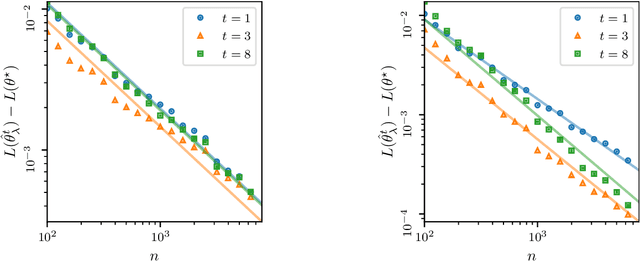
The theory of spectral filtering is a remarkable tool to understand the statistical properties of learning with kernels. For least squares, it allows to derive various regularization schemes that yield faster convergence rates of the excess risk than with Tikhonov regularization. This is typically achieved by leveraging classical assumptions called source and capacity conditions, which characterize the difficulty of the learning task. In order to understand estimators derived from other loss functions, Marteau-Ferey et al. have extended the theory of Tikhonov regularization to generalized self concordant loss functions (GSC), which contain, e.g., the logistic loss. In this paper, we go a step further and show that fast and optimal rates can be achieved for GSC by using the iterated Tikhonov regularization scheme, which is intrinsically related to the proximal point method in optimization, and overcomes the limitation of the classical Tikhonov regularization.
Improving Approximate Optimal Transport Distances using Quantization
Feb 25, 2021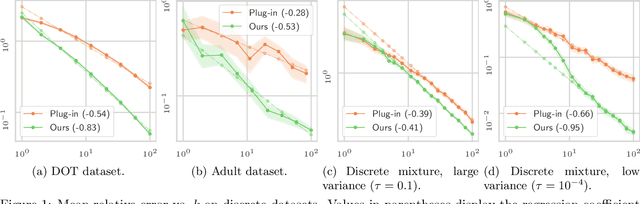
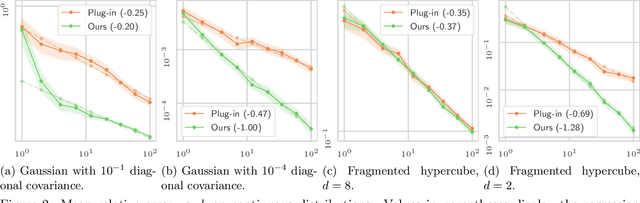
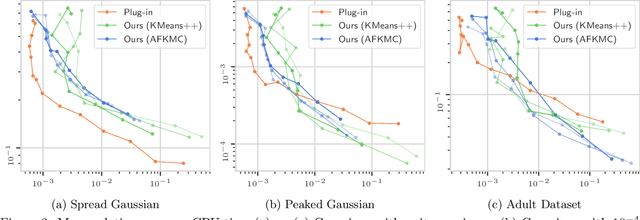
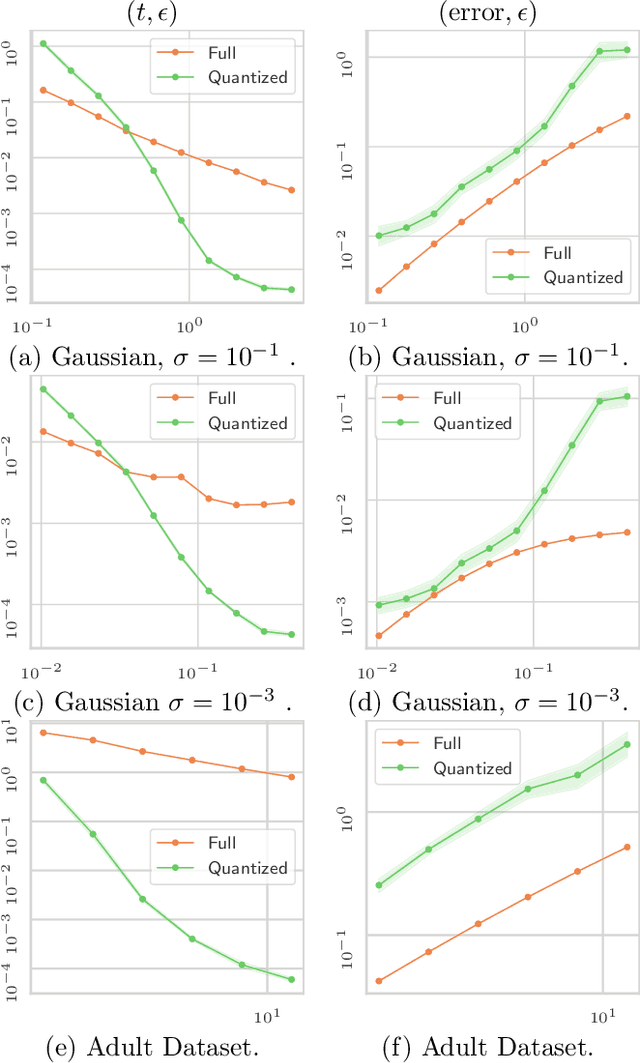
Optimal transport (OT) is a popular tool in machine learning to compare probability measures geometrically, but it comes with substantial computational burden. Linear programming algorithms for computing OT distances scale cubically in the size of the input, making OT impractical in the large-sample regime. We introduce a practical algorithm, which relies on a quantization step, to estimate OT distances between measures given cheap sample access. We also provide a variant of our algorithm to improve the performance of approximate solvers, focusing on those for entropy-regularized transport. We give theoretical guarantees on the benefits of this quantization step and display experiments showing that it behaves well in practice, providing a practical approximation algorithm that can be used as a drop-in replacement for existing OT estimators.