 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Sensor Simulation for Autonomous Driving
Feb 05, 2026In this work, we introduce \textbf{XSIM}, a sensor simulation framework for autonomous driving. XSIM extends 3DGUT splatting with a generalized rolling-shutter modeling tailored for autonomous driving applications. Our framework provides a unified and flexible formulation for appearance and geometric sensor modeling, enabling rendering of complex sensor distortions in dynamic environments. We identify spherical cameras, such as LiDARs, as a critical edge case for existing 3DGUT splatting due to cyclic projection and time discontinuities at azimuth boundaries leading to incorrect particle projection. To address this issue, we propose a phase modeling mechanism that explicitly accounts temporal and shape discontinuities of Gaussians projected by the Unscented Transform at azimuth borders. In addition, we introduce an extended 3D Gaussian representation that incorporates two distinct opacity parameters to resolve mismatches between geometry and color distributions. As a result, our framework provides enhanced scene representations with improved geometric consistency and photorealistic appearance. We evaluate our framework extensively on multiple autonomous driving datasets, including Waymo Open Dataset, Argoverse 2, and PandaSet. Our framework consistently outperforms strong recent baselines and achieves state-of-the-art performance across all datasets. The source code is publicly available at \href{https://github.com/whesense/XSIM}{https://github.com/whesense/XSIM}.
Visual Implicit Geometry Transformer for Autonomous Driving
Feb 05, 2026We introduce the Visual Implicit Geometry Transformer (ViGT), an autonomous driving geometric model that estimates continuous 3D occupancy fields from surround-view camera rigs. ViGT represents a step towards foundational geometric models for autonomous driving, prioritizing scalability, architectural simplicity, and generalization across diverse sensor configurations. Our approach achieves this through a calibration-free architecture, enabling a single model to adapt to different sensor setups. Unlike general-purpose geometric foundational models that focus on pixel-aligned predictions, ViGT estimates a continuous 3D occupancy field in a birds-eye-view (BEV) addressing domain-specific requirements. ViGT naturally infers geometry from multiple camera views into a single metric coordinate frame, providing a common representation for multiple geometric tasks. Unlike most existing occupancy models, we adopt a self-supervised training procedure that leverages synchronized image-LiDAR pairs, eliminating the need for costly manual annotations. We validate the scalability and generalizability of our approach by training our model on a mixture of five large-scale autonomous driving datasets (NuScenes, Waymo, NuPlan, ONCE, and Argoverse) and achieving state-of-the-art performance on the pointmap estimation task, with the best average rank across all evaluated baselines. We further evaluate ViGT on the Occ3D-nuScenes benchmark, where ViGT achieves comparable performance with supervised methods. The source code is publicly available at \href{https://github.com/whesense/ViGT}{https://github.com/whesense/ViGT}.
A3D: Does Diffusion Dream about 3D Alignment?
Jun 21, 2024



We tackle the problem of text-driven 3D generation from a geometry alignment perspective. We aim at the generation of multiple objects which are consistent in terms of semantics and geometry. Recent methods based on Score Distillation have succeeded in distilling the knowledge from 2D diffusion models to high-quality objects represented by 3D neural radiance fields. These methods handle multiple text queries separately, and therefore, the resulting objects have a high variability in object pose and structure. However, in some applications such as geometry editing, it is desirable to obtain aligned objects. In order to achieve alignment, we propose to optimize the continuous trajectories between the aligned objects, by modeling a space of linear pairwise interpolations of the textual embeddings with a single NeRF representation. We demonstrate that similar objects, consisting of semantically corresponding parts, can be well aligned in 3D space without costly modifications to the generation process. We provide several practical scenarios including mesh editing and object hybridization that benefit from geometry alignment and experimentally demonstrate the efficiency of our method. https://voyleg.github.io/a3d/
Independent Component Alignment for Multi-Task Learning
May 30, 2023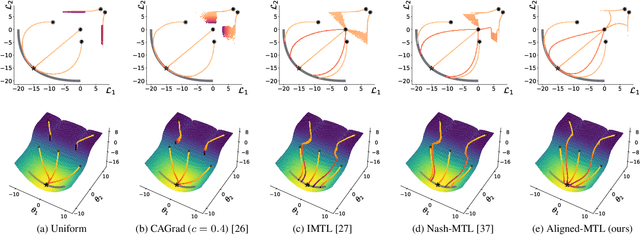
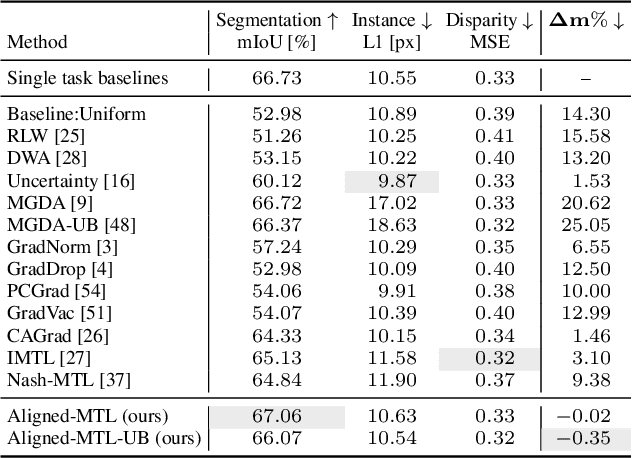
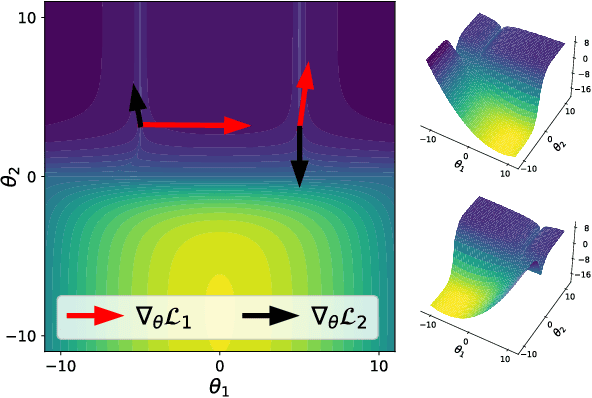
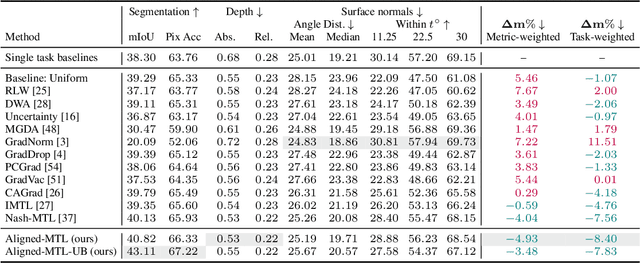
In a multi-task learning (MTL) setting, a single model is trained to tackle a diverse set of tasks jointly. Despite rapid progress in the field, MTL remains challenging due to optimization issues such as conflicting and dominating gradients. In this work, we propose using a condition number of a linear system of gradients as a stability criterion of an MTL optimization. We theoretically demonstrate that a condition number reflects the aforementioned optimization issues. Accordingly, we present Aligned-MTL, a novel MTL optimization approach based on the proposed criterion, that eliminates instability in the training process by aligning the orthogonal components of the linear system of gradients. While many recent MTL approaches guarantee convergence to a minimum, task trade-offs cannot be specified in advance. In contrast, Aligned-MTL provably converges to an optimal point with pre-defined task-specific weights, which provides more control over the optimization result. Through experiments, we show that the proposed approach consistently improves performance on a diverse set of MTL benchmarks, including semantic and instance segmentation, depth estimation, surface normal estimation, and reinforcement learning. The source code is publicly available at https://github.com/SamsungLabs/MTL .
Decoder Modulation for Indoor Depth Completion
May 18, 2020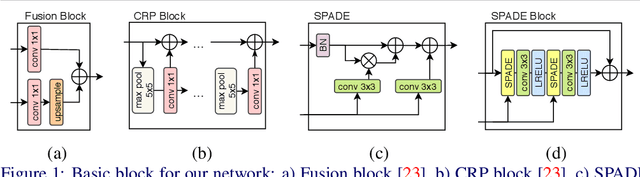
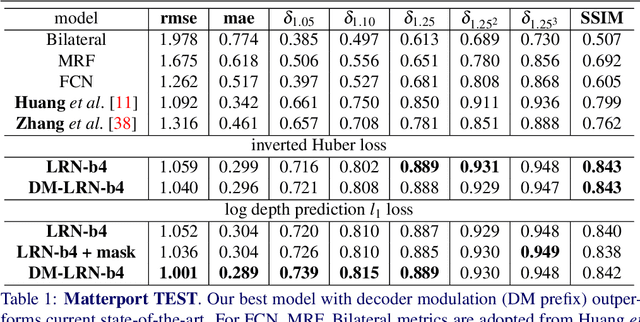


Accurate depth map estimation is an essential step in scene spatial mapping for AR applications and 3D modeling. Current depth sensors provide time-synchronized depth and color images in real-time, but have limited range and suffer from missing and erroneous depth values on transparent or glossy surfaces. We investigate the task of depth completion that aims at improving the accuracy of depth measurements and recovering the missing depth values using additional information from corresponding color images. Surprisingly, we find that a simple baseline model based on modern encoder-decoder architecture for semantic segmentation achieves state-of-the-art accuracy on standard depth completion benchmarks. Then, we show that the accuracy can be further improved by taking into account a mask of missing depth values. The main contributions of our work are two-fold. First, we propose a modified decoder architecture, where features from raw depth and color are modulated by features from the mask via Spatially-Adaptive Denormalization (SPADE). Second, we introduce a new loss function for depth estimation based on a direct comparison of log depth prediction with ground truth values. The resulting model outperforms current state-of-the-art by a large margin on the challenging Matterport3D dataset.