 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Cache-Based Few-Shot Classification via Patch-Driven Relational Gated Graph Attention
Dec 13, 2025Few-shot image classification remains difficult under limited supervision and visual domain shift. Recent cache-based adaptation approaches (e.g., Tip-Adapter) address this challenge to some extent by learning lightweight residual adapters over frozen features, yet they still inherit CLIP's tendency to encode global, general-purpose representations that are not optimally discriminative to adapt the generalist to the specialist's domain in low-data regimes. We address this limitation with a novel patch-driven relational refinement that learns cache adapter weights from intra-image patch dependencies rather than treating an image embedding as a monolithic vector. Specifically, we introduce a relational gated graph attention network that constructs a patch graph and performs edge-aware attention to emphasize informative inter-patch interactions, producing context-enriched patch embeddings. A learnable multi-aggregation pooling then composes these into compact, task-discriminative representations that better align cache keys with the target few-shot classes. Crucially, the proposed graph refinement is used only during training to distil relational structure into the cache, incurring no additional inference cost beyond standard cache lookup. Final predictions are obtained by a residual fusion of cache similarity scores with CLIP zero-shot logits. Extensive evaluations on 11 benchmarks show consistent gains over state-of-the-art CLIP adapter and cache-based baselines while preserving zero-shot efficiency. We further validate battlefield relevance by introducing an Injured vs. Uninjured Soldier dataset for casualty recognition. It is motivated by the operational need to support triage decisions within the "platinum minutes" and the broader "golden hour" window in time-critical UAV-driven search-and-rescue and combat casualty care.
High-Order Evolving Graphs for Enhanced Representation of Traffic Dynamics
Sep 18, 2024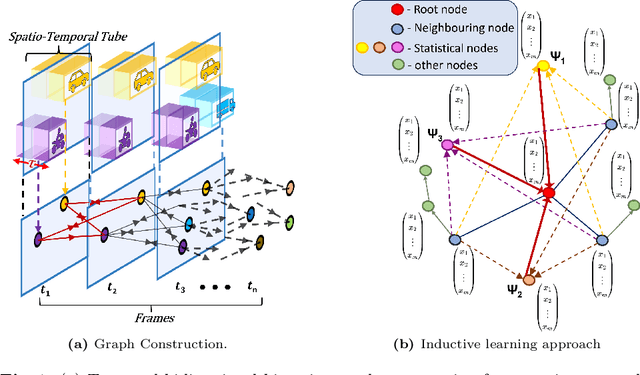

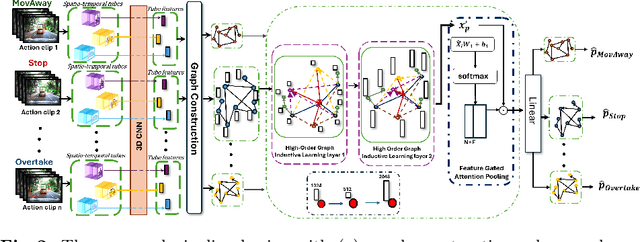
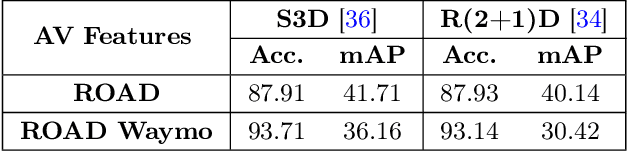
We present an innovative framework for traffic dynamics analysis using High-Order Evolving Graphs, designed to improve spatio-temporal representations in autonomous driving contexts. Our approach constructs temporal bidirectional bipartite graphs that effectively model the complex interactions within traffic scenes in real-time. By integrating Graph Neural Networks (GNNs) with high-order multi-aggregation strategies, we significantly enhance the modeling of traffic scene dynamics, providing a more accurate and detailed analysis of these interactions. Additionally, we incorporate inductive learning techniques inspired by the GraphSAGE framework, enabling our model to adapt to new and unseen traffic scenarios without the need for retraining, thus ensuring robust generalization. Through extensive experiments on the ROAD and ROAD Waymo datasets, we establish a comprehensive baseline for further developments, demonstrating the potential of our method in accurately capturing traffic behavior. Our results emphasize the value of high-order statistical moments and feature-gated attention mechanisms in improving traffic behavior analysis, laying the groundwork for advancing autonomous driving technologies. Our source code is available at: https://github.com/Addy-1998/High_Order_Graphs
SR-GNN: Spatial Relation-aware Graph Neural Network for Fine-Grained Image Categorization
Sep 05, 2022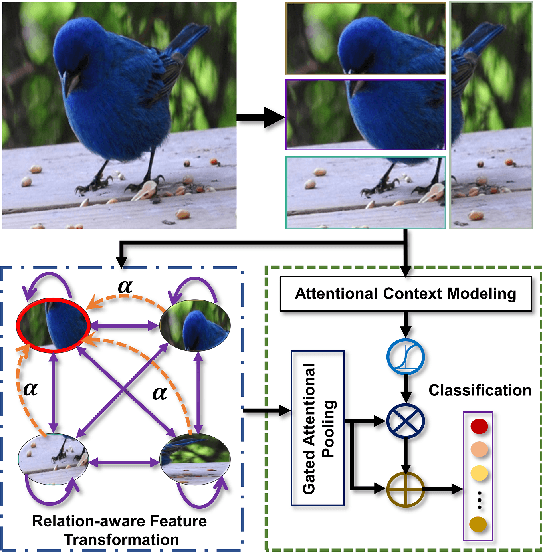
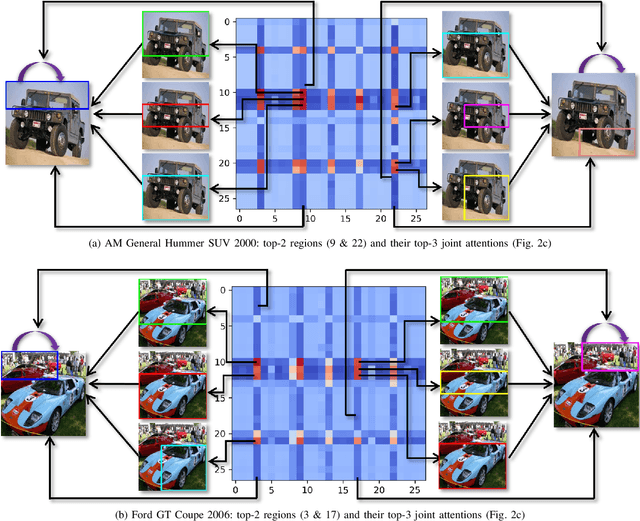
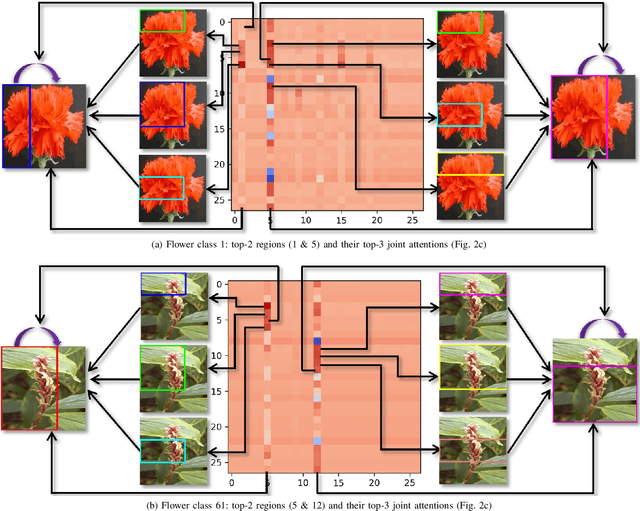
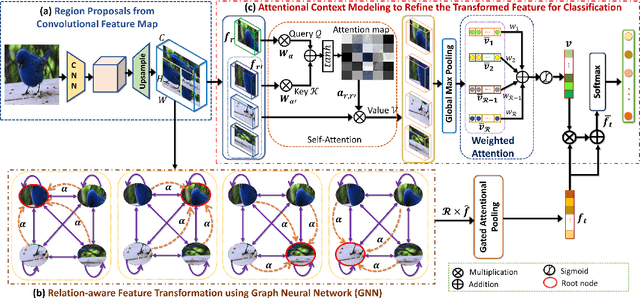
Over the past few years, a significant progress has been made in deep convolutional neural networks (CNNs)-based image recognition. This is mainly due to the strong ability of such networks in mining discriminative object pose and parts information from texture and shape. This is often inappropriate for fine-grained visual classification (FGVC) since it exhibits high intra-class and low inter-class variances due to occlusions, deformation, illuminations, etc. Thus, an expressive feature representation describing global structural information is a key to characterize an object/ scene. To this end, we propose a method that effectively captures subtle changes by aggregating context-aware features from most relevant image-regions and their importance in discriminating fine-grained categories avoiding the bounding-box and/or distinguishable part annotations. Our approach is inspired by the recent advancement in self-attention and graph neural networks (GNNs) approaches to include a simple yet effective relation-aware feature transformation and its refinement using a context-aware attention mechanism to boost the discriminability of the transformed feature in an end-to-end learning process. Our model is evaluated on eight benchmark datasets consisting of fine-grained objects and human-object interactions. It outperforms the state-of-the-art approaches by a significant margin in recognition accuracy.
Retinal Structure Detection in OCTA Image via Voting-based Multi-task Learning
Aug 23, 2022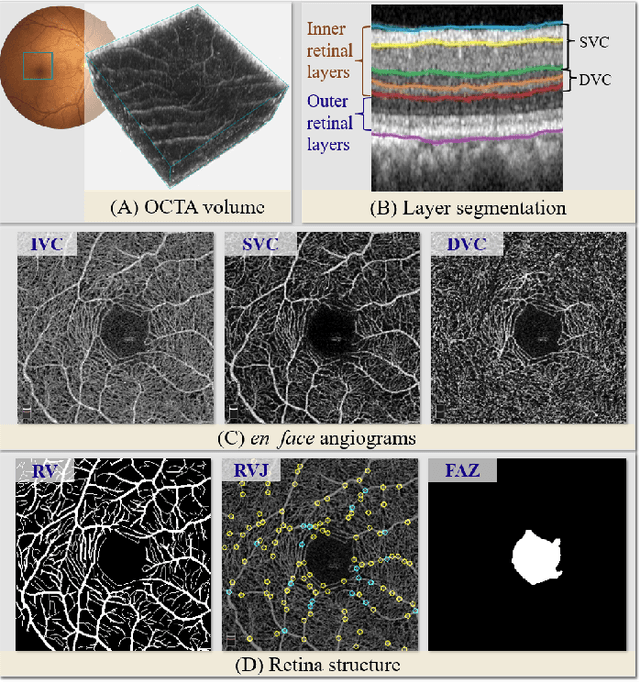
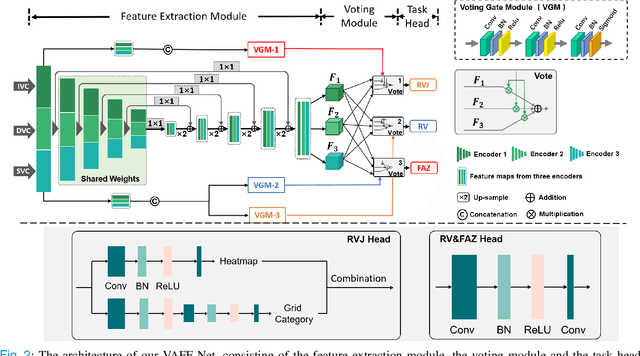
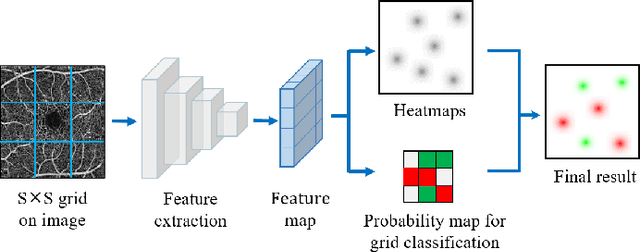
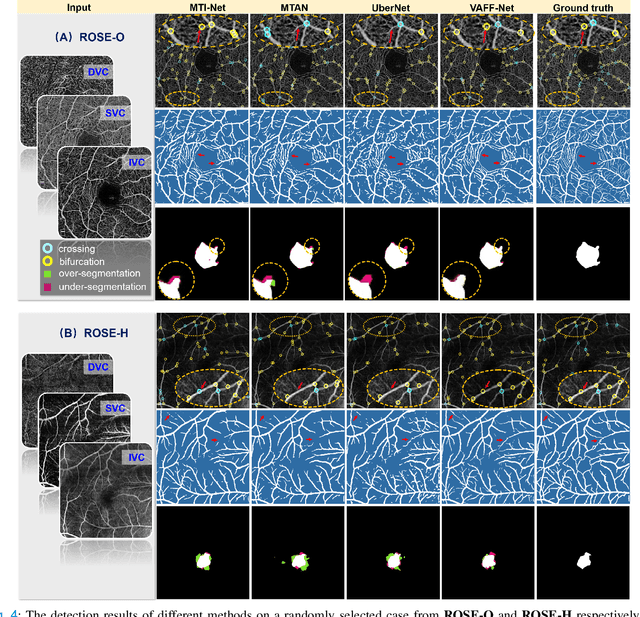
Automated detection of retinal structures, such as retinal vessels (RV), the foveal avascular zone (FAZ), and retinal vascular junctions (RVJ), are of great importance for understanding diseases of the eye and clinical decision-making. In this paper, we propose a novel Voting-based Adaptive Feature Fusion multi-task network (VAFF-Net) for joint segmentation, detection, and classification of RV, FAZ, and RVJ in optical coherence tomography angiography (OCTA). A task-specific voting gate module is proposed to adaptively extract and fuse different features for specific tasks at two levels: features at different spatial positions from a single encoder, and features from multiple encoders. In particular, since the complexity of the microvasculature in OCTA images makes simultaneous precise localization and classification of retinal vascular junctions into bifurcation/crossing a challenging task, we specifically design a task head by combining the heatmap regression and grid classification. We take advantage of three different \textit{en face} angiograms from various retinal layers, rather than following existing methods that use only a single \textit{en face}. To facilitate further research, part of these datasets with the source code and evaluation benchmark have been released for public access:https://github.com/iMED-Lab/VAFF-Net.
Benchmarking Deep Reinforcement Learning Algorithms for Vision-based Robotics
Jan 11, 2022
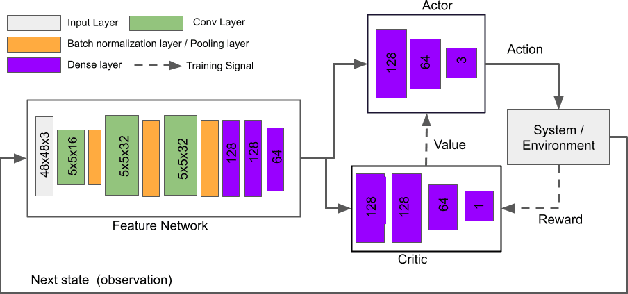
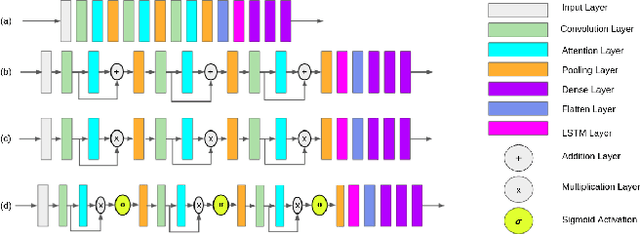
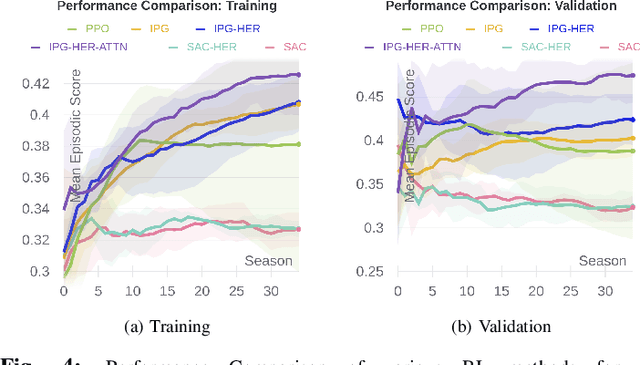
This paper presents a benchmarking study of some of the state-of-the-art reinforcement learning algorithms used for solving two simulated vision-based robotics problems. The algorithms considered in this study include soft actor-critic (SAC), proximal policy optimization (PPO), interpolated policy gradients (IPG), and their variants with Hindsight Experience replay (HER). The performances of these algorithms are compared against PyBullet's two simulation environments known as KukaDiverseObjectEnv and RacecarZEDGymEnv respectively. The state observations in these environments are available in the form of RGB images and the action space is continuous, making them difficult to solve. A number of strategies are suggested to provide intermediate hindsight goals required for implementing HER algorithm on these problems which are essentially single-goal environments. In addition, a number of feature extraction architectures are proposed to incorporate spatial and temporal attention in the learning process. Through rigorous simulation experiments, the improvement achieved with these components are established. To the best of our knowledge, such a benchmarking study is not available for the above two vision-based robotics problems making it a novel contribution in the field.
Attend and Guide : A Keypoints-driven Attention-based Deep Network for Image Recognition
Oct 23, 2021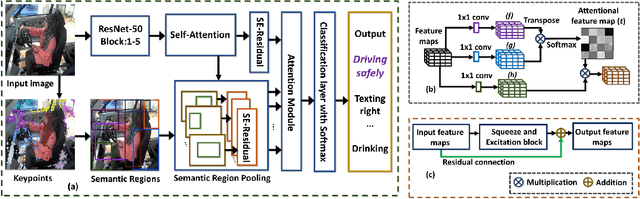
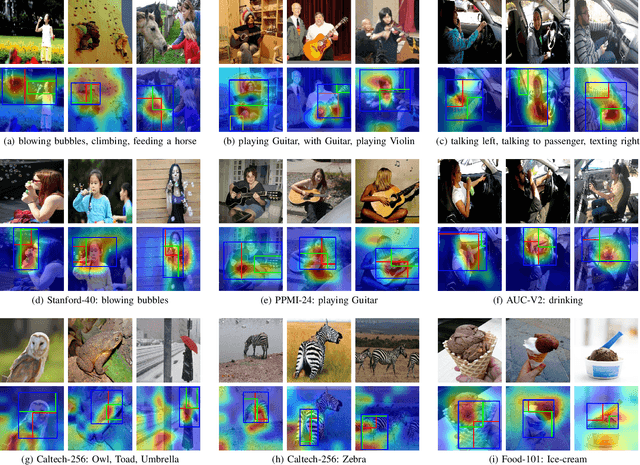


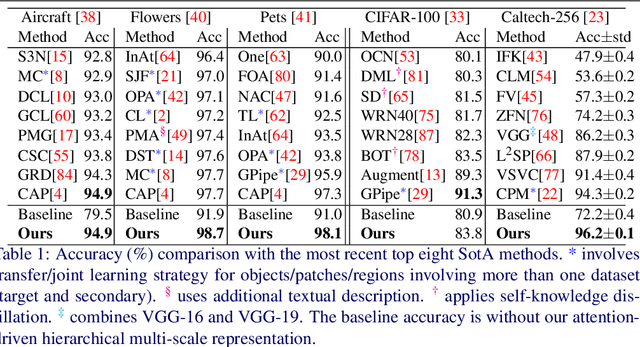
This paper presents a novel keypoints-based attention mechanism for visual recognition in still images. Deep Convolutional Neural Networks (CNNs) for recognizing images with distinctive classes have shown great success, but their performance in discriminating fine-grained changes is not at the same level. We address this by proposing an end-to-end CNN model, which learns meaningful features linking fine-grained changes using our novel attention mechanism. It captures the spatial structures in images by identifying semantic regions (SRs) and their spatial distributions, and is proved to be the key to modelling subtle changes in images. We automatically identify these SRs by grouping the detected keypoints in a given image. The ``usefulness'' of these SRs for image recognition is measured using our innovative attentional mechanism focusing on parts of the image that are most relevant to a given task. This framework applies to traditional and fine-grained image recognition tasks and does not require manually annotated regions (e.g. bounding-box of body parts, objects, etc.) for learning and prediction. Moreover, the proposed keypoints-driven attention mechanism can be easily integrated into the existing CNN models. The framework is evaluated on six diverse benchmark datasets. The model outperforms the state-of-the-art approaches by a considerable margin using Distracted Driver V1 (Acc: 3.39%), Distracted Driver V2 (Acc: 6.58%), Stanford-40 Actions (mAP: 2.15%), People Playing Musical Instruments (mAP: 16.05%), Food-101 (Acc: 6.30%) and Caltech-256 (Acc: 2.59%) datasets.
* Published in IEEE Transaction on Image Processing 2021, Vol. 30, pp. 3691 - 3704
An attention-driven hierarchical multi-scale representation for visual recognition
Oct 23, 2021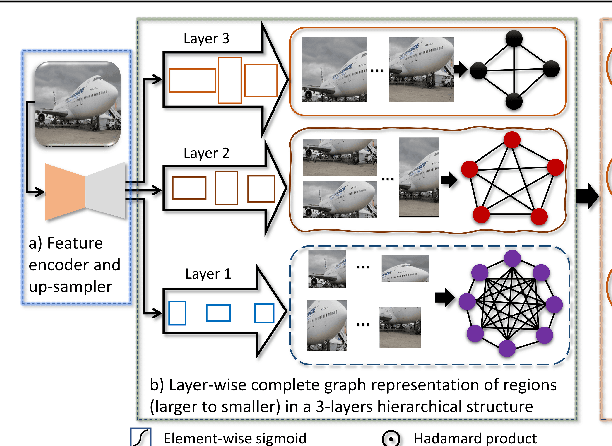


Convolutional Neural Networks (CNNs) have revolutionized the understanding of visual content. This is mainly due to their ability to break down an image into smaller pieces, extract multi-scale localized features and compose them to construct highly expressive representations for decision making. However, the convolution operation is unable to capture long-range dependencies such as arbitrary relations between pixels since it operates on a fixed-size window. Therefore, it may not be suitable for discriminating subtle changes (e.g. fine-grained visual recognition). To this end, our proposed method captures the high-level long-range dependencies by exploring Graph Convolutional Networks (GCNs), which aggregate information by establishing relationships among multi-scale hierarchical regions. These regions consist of smaller (closer look) to larger (far look), and the dependency between regions is modeled by an innovative attention-driven message propagation, guided by the graph structure to emphasize the neighborhoods of a given region. Our approach is simple yet extremely effective in solving both the fine-grained and generic visual classification problems. It outperforms the state-of-the-arts with a significant margin on three and is very competitive on other two datasets.
* Accepted in the 32nd British Machine Vision Conference (BMVC) 2021
Coarse Temporal Attention Network (CTA-Net) for Driver's Activity Recognition
Jan 17, 2021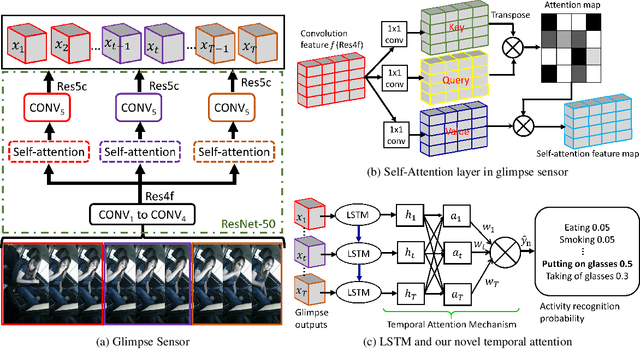
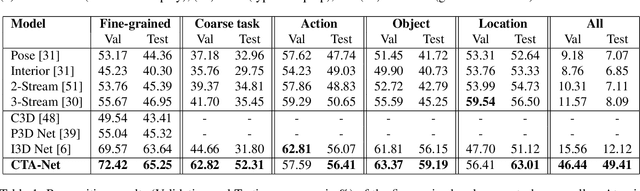

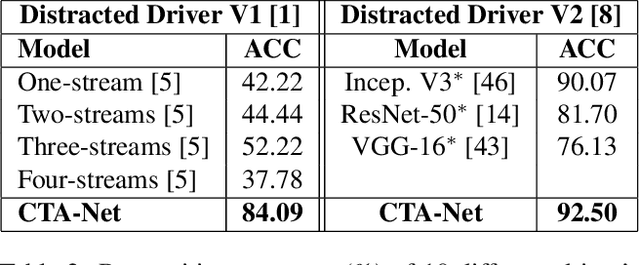
There is significant progress in recognizing traditional human activities from videos focusing on highly distinctive actions involving discriminative body movements, body-object and/or human-human interactions. Driver's activities are different since they are executed by the same subject with similar body parts movements, resulting in subtle changes. To address this, we propose a novel framework by exploiting the spatiotemporal attention to model the subtle changes. Our model is named Coarse Temporal Attention Network (CTA-Net), in which coarse temporal branches are introduced in a trainable glimpse network. The goal is to allow the glimpse to capture high-level temporal relationships, such as 'during', 'before' and 'after' by focusing on a specific part of a video. These branches also respect the topology of the temporal dynamics in the video, ensuring that different branches learn meaningful spatial and temporal changes. The model then uses an innovative attention mechanism to generate high-level action specific contextual information for activity recognition by exploring the hidden states of an LSTM. The attention mechanism helps in learning to decide the importance of each hidden state for the recognition task by weighing them when constructing the representation of the video. Our approach is evaluated on four publicly accessible datasets and significantly outperforms the state-of-the-art by a considerable margin with only RGB video as input.
* Extended version of the accepted WACV 2021
Context-aware Attentional Pooling (CAP) for Fine-grained Visual Classification
Jan 17, 2021
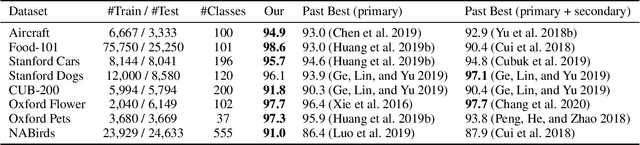


Deep convolutional neural networks (CNNs) have shown a strong ability in mining discriminative object pose and parts information for image recognition. For fine-grained recognition, context-aware rich feature representation of object/scene plays a key role since it exhibits a significant variance in the same subcategory and subtle variance among different subcategories. Finding the subtle variance that fully characterizes the object/scene is not straightforward. To address this, we propose a novel context-aware attentional pooling (CAP) that effectively captures subtle changes via sub-pixel gradients, and learns to attend informative integral regions and their importance in discriminating different subcategories without requiring the bounding-box and/or distinguishable part annotations. We also introduce a novel feature encoding by considering the intrinsic consistency between the informativeness of the integral regions and their spatial structures to capture the semantic correlation among them. Our approach is simple yet extremely effective and can be easily applied on top of a standard classification backbone network. We evaluate our approach using six state-of-the-art (SotA) backbone networks and eight benchmark datasets. Our method significantly outperforms the SotA approaches on six datasets and is very competitive with the remaining two.
* Extended version of the accepted paper in 35th AAAI Conference on Artificial Intelligence 2021
Regional Attention Network for Head Pose and Fine-grained Gesture Recognition
Jan 17, 2021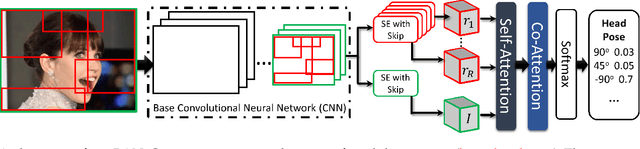
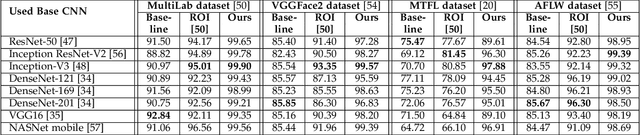
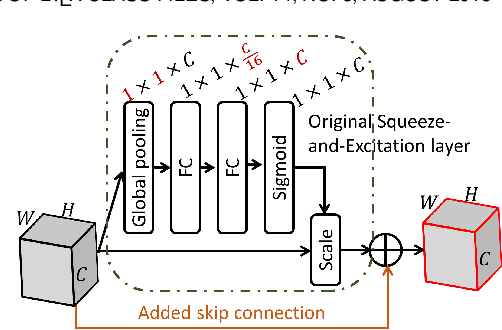
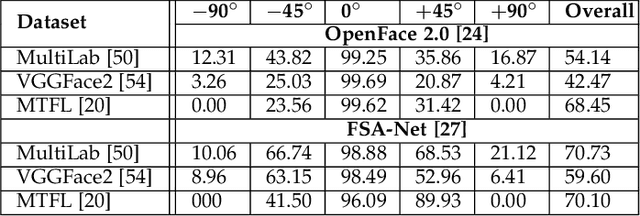
Affect is often expressed via non-verbal body language such as actions/gestures, which are vital indicators for human behaviors. Recent studies on recognition of fine-grained actions/gestures in monocular images have mainly focused on modeling spatial configuration of body parts representing body pose, human-objects interactions and variations in local appearance. The results show that this is a brittle approach since it relies on accurate body parts/objects detection. In this work, we argue that there exist local discriminative semantic regions, whose "informativeness" can be evaluated by the attention mechanism for inferring fine-grained gestures/actions. To this end, we propose a novel end-to-end \textbf{Regional Attention Network (RAN)}, which is a fully Convolutional Neural Network (CNN) to combine multiple contextual regions through attention mechanism, focusing on parts of the images that are most relevant to a given task. Our regions consist of one or more consecutive cells and are adapted from the strategies used in computing HOG (Histogram of Oriented Gradient) descriptor. The model is extensively evaluated on ten datasets belonging to 3 different scenarios: 1) head pose recognition, 2) drivers state recognition, and 3) human action and facial expression recognition. The proposed approach outperforms the state-of-the-art by a considerable margin in different metrics.
* This manuscript is the accepted version of the published paper in IEEE Transaction on Affective Computing