 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePND-Net: Plant Nutrition Deficiency and Disease Classification using Graph Convolutional Network
Oct 16, 2024Crop yield production could be enhanced for agricultural growth if various plant nutrition deficiencies, and diseases are identified and detected at early stages. The deep learning methods have proven its superior performances in the automated detection of plant diseases and nutrition deficiencies from visual symptoms in leaves. This article proposes a new deep learning method for plant nutrition deficiencies and disease classification using a graph convolutional network (GNN), added upon a base convolutional neural network (CNN). Sometimes, a global feature descriptor might fail to capture the vital region of a diseased leaf, which causes inaccurate classification of disease. To address this issue, regional feature learning is crucial for a holistic feature aggregation. In this work, region-based feature summarization at multi-scales is explored using spatial pyramidal pooling for discriminative feature representation. A GCN is developed to capacitate learning of finer details for classifying plant diseases and insufficiency of nutrients. The proposed method, called Plant Nutrition Deficiency and Disease Network (PND-Net), is evaluated on two public datasets for nutrition deficiency, and two for disease classification using four CNNs. The best classification performances are: (a) 90.00% Banana and 90.54% Coffee nutrition deficiency; and (b) 96.18% Potato diseases and 84.30% on PlantDoc datasets using Xception backbone. Furthermore, additional experiments have been carried out for generalization, and the proposed method has achieved state-of-the-art performances on two public datasets, namely the Breast Cancer Histopathology Image Classification (BreakHis 40X: 95.50%, and BreakHis 100X: 96.79% accuracy) and Single cells in Pap smear images for cervical cancer classification (SIPaKMeD: 99.18% accuracy). Also, PND-Net achieves improved performances using five-fold cross validation.
RAFA-Net: Region Attention Network For Food Items And Agricultural Stress Recognition
Oct 16, 2024



Deep Convolutional Neural Networks (CNNs) have facilitated remarkable success in recognizing various food items and agricultural stress. A decent performance boost has been witnessed in solving the agro-food challenges by mining and analyzing of region-based partial feature descriptors. Also, computationally expensive ensemble learning schemes using multiple CNNs have been studied in earlier works. This work proposes a region attention scheme for modelling long-range dependencies by building a correlation among different regions within an input image. The attention method enhances feature representation by learning the usefulness of context information from complementary regions. Spatial pyramidal pooling and average pooling pair aggregate partial descriptors into a holistic representation. Both pooling methods establish spatial and channel-wise relationships without incurring extra parameters. A context gating scheme is applied to refine the descriptiveness of weighted attentional features, which is relevant for classification. The proposed Region Attention network for Food items and Agricultural stress recognition method, dubbed RAFA-Net, has been experimented on three public food datasets, and has achieved state-of-the-art performances with distinct margins. The highest top-1 accuracies of RAFA-Net are 91.69%, 91.56%, and 96.97% on the UECFood-100, UECFood-256, and MAFood-121 datasets, respectively. In addition, better accuracies have been achieved on two benchmark agricultural stress datasets. The best top-1 accuracies on the Insect Pest (IP-102) and PlantDoc-27 plant disease datasets are 92.36%, and 85.54%, respectively; implying RAFA-Net's generalization capability.
Human Identification using Selected Features from Finger Geometric Profiles
Oct 13, 2024



A finger biometric system at an unconstrained environment is presented in this paper. A technique for hand image normalization is implemented at the preprocessing stage that decomposes the main hand contour into finger-level shape representation. This normalization technique follows subtraction of transformed binary image from binary hand contour image to generate the left side of finger profiles (LSFP). Then, XOR is applied to LSFP image and hand contour image to produce the right side of finger profiles (RSFP). During feature extraction, initially, thirty geometric features are computed from every normalized finger. The rank-based forward-backward greedy algorithm is followed to select relevant features and to enhance classification accuracy. Two different subsets of features containing nine and twelve discriminative features per finger are selected for two separate experimentations those use the kNN and the Random Forest (RF) for classification on the Bosphorus hand database. The experiments with the selected features of four fingers except the thumb have obtained improved performances compared to features extracted from five fingers and also other existing methods evaluated on the Bosphorus database. The best identification accuracies of 96.56% and 95.92% using the RF classifier have been achieved for the right- and left-hand images of 638 sub-jects, respectively. An equal error rate of 0.078 is obtained for both types of the hand images.
Fusion Based Hand Geometry Recognition Using Dempster-Shafer Theory
Oct 13, 2024



This paper presents a new technique for person recognition based on the fusion of hand geometric features of both the hands without any pose restrictions. All the features are extracted from normalized left and right hand images. Fusion is applied at feature level and also at decision level. Two probability based algorithms are proposed for classification. The first algorithm computes the maximum probability for nearest three neighbors. The second algorithm determines the maximum probability of the number of matched features with respect to a thresholding on distances. Based on these two highest probabilities initial decisions are made. The final decision is considered according to the highest probability as calculated by the Dempster-Shafer theory of evidence. Depending on the various combinations of the initial decisions, three schemes are experimented with 201 subjects for identification and verification. The correct identification rate found to be 99.5%, and the False Acceptance Rate (FAR) of 0.625% has been found during verification.
Two-Stage Human Verification using HandCAPTCHA and Anti-Spoofed Finger Biometrics with Feature Selection
Oct 13, 2024



This paper presents a human verification scheme in two independent stages to overcome the vulnerabilities of attacks and to enhance security. At the first stage, a hand image-based CAPTCHA (HandCAPTCHA) is tested to avert automated bot-attacks on the subsequent biometric stage. In the next stage, finger biometric verification of a legitimate user is performed with presentation attack detection (PAD) using the real hand images of the person who has passed a random HandCAPTCHA challenge. The electronic screen-based PAD is tested using image quality metrics. After this spoofing detection, geometric features are extracted from the four fingers (excluding the thumb) of real users. A modified forward-backward (M-FoBa) algorithm is devised to select relevant features for biometric authentication. The experiments are performed on the Bogazici University (BU) and the IIT-Delhi (IITD) hand databases using the k-nearest neighbor and random forest classifiers. The average accuracy of the correct HandCAPTCHA solution is 98.5%, and the false accept rate of a bot is 1.23%. The PAD is tested on 255 subjects of BU, and the best average error is 0%. The finger biometric identification accuracy of 98% and an equal error rate (EER) of 6.5% have been achieved for 500 subjects of the BU. For 200 subjects of the IITD, 99.5% identification accuracy, and 5.18% EER are obtained.
Hand Biometrics in Digital Forensics
Feb 17, 2024Digital forensic is now an unavoidable part for securing the digital world from identity theft. Higher order of crimes, dealing with a massive database is really very challenging problem for any intelligent system. Biometric is a better solution to win over the problems encountered by digital forensics. Many biometric characteristics are playing their significant roles in forensics over the decades. The potential benefits and scope of hand based modes in forensics have been investigated with an illustration of hand geometry verifi-cation method. It can be applied when effective biometric evidences are properly unavailable; gloves are damaged, and dirt or any kind of liquid can minimize the accessibility and reliability of the fingerprint or palmprint. Due to the crisis of pure uniqueness of hand features for a very large database, it may be relevant for verification only. Some unimodal and multimodal hand based biometrics (e.g. hand geometry, palmprint and hand vein) with several feature extractions, database and verification methods have been discussed with 2D, 3D and infrared images.
Finger Biometric Recognition With Feature Selection
Dec 19, 2023Biometrics is indispensable in this modern digital era for secure automated human authentication in various fields of machine learning and pattern recognition. Hand geometry is a promising physiological biometric trait with ample deployed application areas for identity verification. Due to the intricate anatomic foundation of the thumb and substantial inter-finger posture variation, satisfactory performances cannot be achieved while the thumb is included in the contact-free environment. To overcome the hindrances associated with the thumb, four finger-based (excluding the thumb) biometric approaches have been devised. In this chapter, a four-finger based biometric method has been presented. Again, selection of salient features is essential to reduce the feature dimensionality by eliminating the insignificant features. Weights are assigned according to the discriminative efficiency of the features to emphasize on the essential features. Two different strategies namely, the global and local feature selection methods are adopted based on the adaptive forward-selection and backward-elimination (FoBa) algorithm. The identification performances are evaluated using the weighted k-nearest neighbor (wk-NN) and random forest (RF) classifiers. The experiments are conducted using the selected feature subsets over the 300 subjects of the Bosphorus hand database. The best identification accuracy of 98.67%, and equal error rate (EER) of 4.6% have been achieved using the subset of 25 features which are selected by the rank-based local FoBa algorithm.
Deep Ear Biometrics for Gender Classification
Aug 17, 2023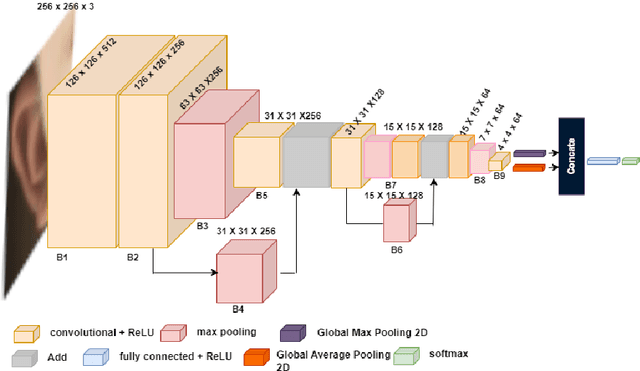
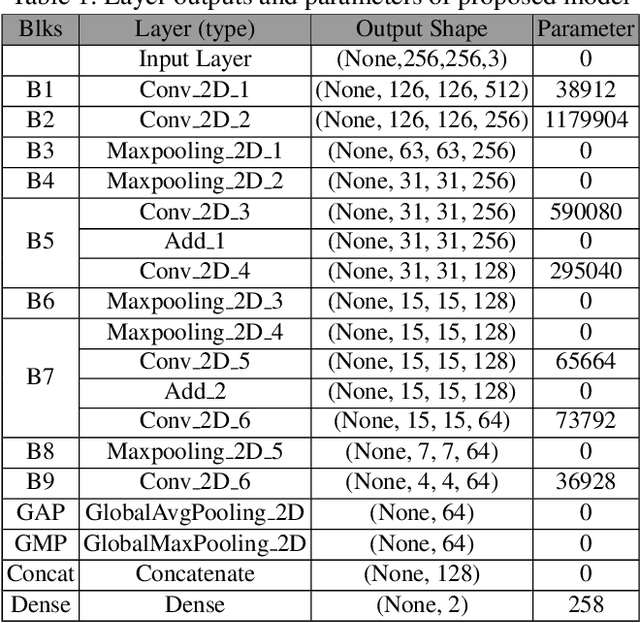
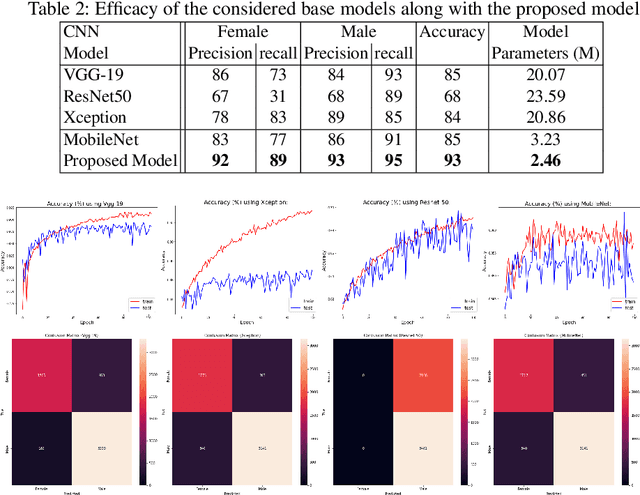
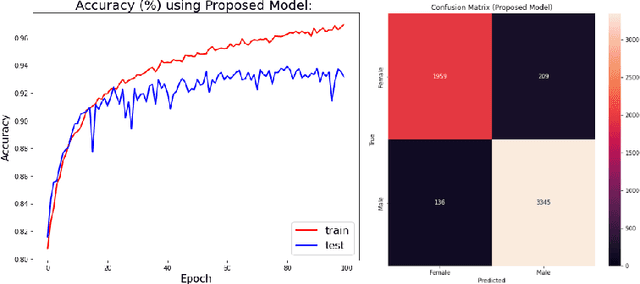
Human gender classification based on biometric features is a major concern for computer vision due to its vast variety of applications. The human ear is popular among researchers as a soft biometric trait, because it is less affected by age or changing circumstances, and is non-intrusive. In this study, we have developed a deep convolutional neural network (CNN) model for automatic gender classification using the samples of ear images. The performance is evaluated using four cutting-edge pre-trained CNN models. In terms of trainable parameters, the proposed technique requires significantly less computational complexity. The proposed model has achieved 93% accuracy on the EarVN1.0 ear dataset.
Deep Neural Networks Fused with Textures for Image Classification
Aug 03, 2023Fine-grained image classification (FGIC) is a challenging task in computer vision for due to small visual differences among inter-subcategories, but, large intra-class variations. Deep learning methods have achieved remarkable success in solving FGIC. In this paper, we propose a fusion approach to address FGIC by combining global texture with local patch-based information. The first pipeline extracts deep features from various fixed-size non-overlapping patches and encodes features by sequential modelling using the long short-term memory (LSTM). Another path computes image-level textures at multiple scales using the local binary patterns (LBP). The advantages of both streams are integrated to represent an efficient feature vector for image classification. The method is tested on eight datasets representing the human faces, skin lesions, food dishes, marine lives, etc. using four standard backbone CNNs. Our method has attained better classification accuracy over existing methods with notable margins.
* 14 pages, 6 figures, 4 tables, conference
Fine-Grained Sports, Yoga, and Dance Postures Recognition: A Benchmark Analysis
Aug 01, 2023



Human body-pose estimation is a complex problem in computer vision. Recent research interests have been widened specifically on the Sports, Yoga, and Dance (SYD) postures for maintaining health conditions. The SYD pose categories are regarded as a fine-grained image classification task due to the complex movement of body parts. Deep Convolutional Neural Networks (CNNs) have attained significantly improved performance in solving various human body-pose estimation problems. Though decent progress has been achieved in yoga postures recognition using deep learning techniques, fine-grained sports, and dance recognition necessitates ample research attention. However, no benchmark public image dataset with sufficient inter-class and intra-class variations is available yet to address sports and dance postures classification. To solve this limitation, we have proposed two image datasets, one for 102 sport categories and another for 12 dance styles. Two public datasets, Yoga-82 which contains 82 classes and Yoga-107 represents 107 classes are collected for yoga postures. These four SYD datasets are experimented with the proposed deep model, SYD-Net, which integrates a patch-based attention (PbA) mechanism on top of standard backbone CNNs. The PbA module leverages the self-attention mechanism that learns contextual information from a set of uniform and multi-scale patches and emphasizes discriminative features to understand the semantic correlation among patches. Moreover, random erasing data augmentation is applied to improve performance. The proposed SYD-Net has achieved state-of-the-art accuracy on Yoga-82 using five base CNNs. SYD-Net's accuracy on other datasets is remarkable, implying its efficiency. Our Sports-102 and Dance-12 datasets are publicly available at https://sites.google.com/view/syd-net/home.
* 12 pages, 12 figures, 10 tables