 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFH: A Multi-faceted Heuristic Algorithm Selection Approach for Software Verification
Mar 28, 2025Currently, many verification algorithms are available to improve the reliability of software systems. Selecting the appropriate verification algorithm typically demands domain expertise and non-trivial manpower. An automated algorithm selector is thus desired. However, existing selectors, either depend on machine-learned strategies or manually designed heuristics, encounter issues such as reliance on high-quality samples with algorithm labels and limited scalability. In this paper, an automated algorithm selection approach, namely MFH, is proposed for software verification. Our approach leverages the heuristics that verifiers producing correct results typically implement certain appropriate algorithms, and the supported algorithms by these verifiers indirectly reflect which ones are potentially applicable. Specifically, MFH embeds the code property graph (CPG) of a semantic-preserving transformed program to enhance the robustness of the prediction model. Furthermore, our approach decomposes the selection task into the sub-tasks of predicting potentially applicable algorithms and matching the most appropriate verifiers. Additionally, MFH also introduces a feedback loop on incorrect predictions to improve model prediction accuracy. We evaluate MFH on 20 verifiers and over 15,000 verification tasks. Experimental results demonstrate the effectiveness of MFH, achieving a prediction accuracy of 91.47% even without ground truth algorithm labels provided during the training phase. Moreover, the prediction accuracy decreases only by 0.84% when introducing 10 new verifiers, indicating the strong scalability of the proposed approach.
AutoTestForge: A Multidimensional Automated Testing Framework for Natural Language Processing Models
Mar 07, 2025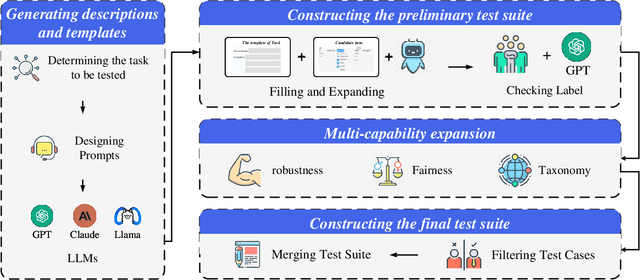
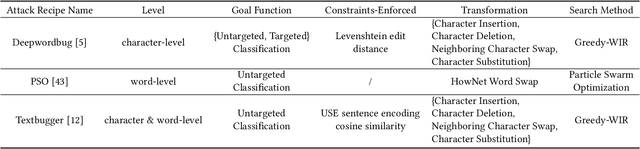

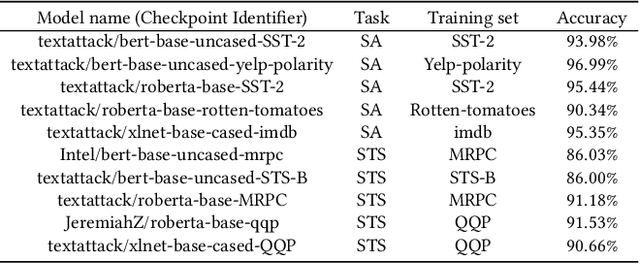
In recent years, the application of behavioral testing in Natural Language Processing (NLP) model evaluation has experienced a remarkable and substantial growth. However, the existing methods continue to be restricted by the requirements for manual labor and the limited scope of capability assessment. To address these limitations, we introduce AutoTestForge, an automated and multidimensional testing framework for NLP models in this paper. Within AutoTestForge, through the utilization of Large Language Models (LLMs) to automatically generate test templates and instantiate them, manual involvement is significantly reduced. Additionally, a mechanism for the validation of test case labels based on differential testing is implemented which makes use of a multi-model voting system to guarantee the quality of test cases. The framework also extends the test suite across three dimensions, taxonomy, fairness, and robustness, offering a comprehensive evaluation of the capabilities of NLP models. This expansion enables a more in-depth and thorough assessment of the models, providing valuable insights into their strengths and weaknesses. A comprehensive evaluation across sentiment analysis (SA) and semantic textual similarity (STS) tasks demonstrates that AutoTestForge consistently outperforms existing datasets and testing tools, achieving higher error detection rates (an average of $30.89\%$ for SA and $34.58\%$ for STS). Moreover, different generation strategies exhibit stable effectiveness, with error detection rates ranging from $29.03\% - 36.82\%$.
ParMod: A Parallel and Modular Framework for Learning Non-Markovian Tasks
Dec 17, 2024



The commonly used Reinforcement Learning (RL) model, MDPs (Markov Decision Processes), has a basic premise that rewards depend on the current state and action only. However, many real-world tasks are non-Markovian, which has long-term memory and dependency. The reward sparseness problem is further amplified in non-Markovian scenarios. Hence learning a non-Markovian task (NMT) is inherently more difficult than learning a Markovian one. In this paper, we propose a novel \textbf{Par}allel and \textbf{Mod}ular RL framework, ParMod, specifically for learning NMTs specified by temporal logic. With the aid of formal techniques, the NMT is modulaized into a series of sub-tasks based on the automaton structure (equivalent to its temporal logic counterpart). On this basis, sub-tasks will be trained by a group of agents in a parallel fashion, with one agent handling one sub-task. Besides parallel training, the core of ParMod lies in: a flexible classification method for modularizing the NMT, and an effective reward shaping method for improving the sample efficiency. A comprehensive evaluation is conducted on several challenging benchmark problems with respect to various metrics. The experimental results show that ParMod achieves superior performance over other relevant studies. Our work thus provides a good synergy among RL, NMT and temporal logic.
Using Experience Classification for Training Non-Markovian Tasks
Oct 18, 2023



Unlike the standard Reinforcement Learning (RL) model, many real-world tasks are non-Markovian, whose rewards are predicated on state history rather than solely on the current state. Solving a non-Markovian task, frequently applied in practical applications such as autonomous driving, financial trading, and medical diagnosis, can be quite challenging. We propose a novel RL approach to achieve non-Markovian rewards expressed in temporal logic LTL$_f$ (Linear Temporal Logic over Finite Traces). To this end, an encoding of linear complexity from LTL$_f$ into MDPs (Markov Decision Processes) is introduced to take advantage of advanced RL algorithms. Then, a prioritized experience replay technique based on the automata structure (semantics equivalent to LTL$_f$ specification) is utilized to improve the training process. We empirically evaluate several benchmark problems augmented with non-Markovian tasks to demonstrate the feasibility and effectiveness of our approach.