 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpening the Scope of Openness in AI
May 09, 2025


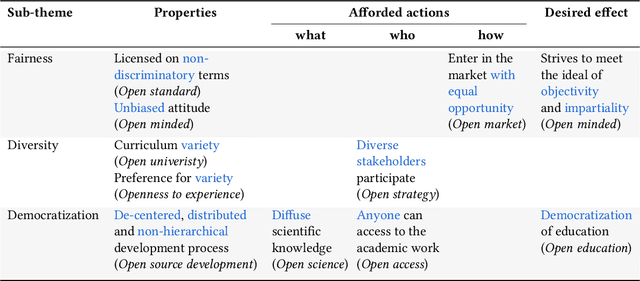
The concept of openness in AI has so far been heavily inspired by the definition and community practice of open source software. This positions openness in AI as having positive connotations; it introduces assumptions of certain advantages, such as collaborative innovation and transparency. However, the practices and benefits of open source software are not fully transferable to AI, which has its own challenges. Framing a notion of openness tailored to AI is crucial to addressing its growing societal implications, risks, and capabilities. We argue that considering the fundamental scope of openness in different disciplines will broaden discussions, introduce important perspectives, and reflect on what openness in AI should mean. Toward this goal, we qualitatively analyze 98 concepts of openness discovered from topic modeling, through which we develop a taxonomy of openness. Using this taxonomy as an instrument, we situate the current discussion on AI openness, identify gaps and highlight links with other disciplines. Our work contributes to the recent efforts in framing openness in AI by reflecting principles and practices of openness beyond open source software and calls for a more holistic view of openness in terms of actions, system properties, and ethical objectives.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
NTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024


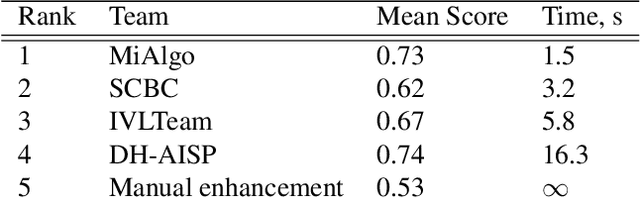
This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024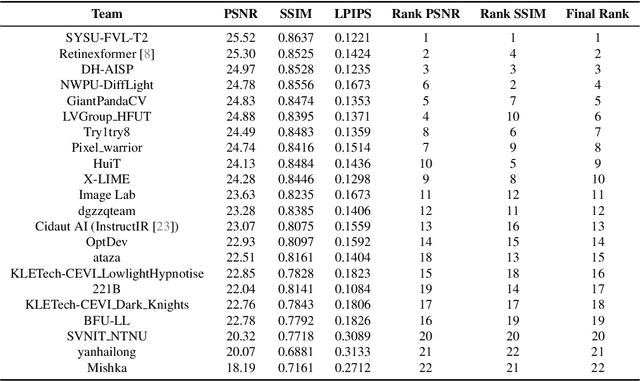

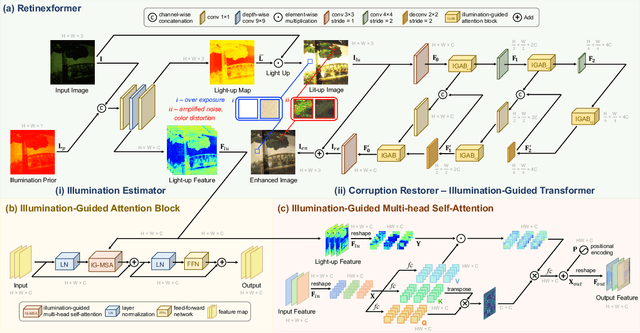

This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Early Warning via tipping-preserving latent stochastic dynamical system and meta label correcting
Oct 09, 2023Early warning for epilepsy patients is crucial for their safety and well-being, in terms of preventing or minimizing the severity of seizures. Through the patients' EEG data, we propose a meta learning framework for improving prediction on early ictal signals. To better utilize the meta label corrector method, we fuse the information from both the real data and the augmented data from the latent Stochastic differential equation(SDE). Besides, we also optimally select the latent dynamical system via distribution of transition time between real data and that from the latent SDE. In this way, the extracted tipping dynamical feature is also integrated into the meta network to better label the noisy data. To validate our method, LSTM is implemented as the baseline model. We conduct a series of experiments to predict seizure in various long-term window from 1-2 seconds input data and find surprisingly increment of prediction accuracy.
Learning Stochastic Dynamical Systems as an Implicit Regularization with Graph Neural Networks
Jul 12, 2023Stochastic Gumbel graph networks are proposed to learn high-dimensional time series, where the observed dimensions are often spatially correlated. To that end, the observed randomness and spatial-correlations are captured by learning the drift and diffusion terms of the stochastic differential equation with a Gumble matrix embedding, respectively. In particular, this novel framework enables us to investigate the implicit regularization effect of the noise terms in S-GGNs. We provide a theoretical guarantee for the proposed S-GGNs by deriving the difference between the two corresponding loss functions in a small neighborhood of weight. Then, we employ Kuramoto's model to generate data for comparing the spectral density from the Hessian Matrix of the two loss functions. Experimental results on real-world data, demonstrate that S-GGNs exhibit superior convergence, robustness, and generalization, compared with state-of-the-arts.
The Vault: A Comprehensive Multilingual Dataset for Advancing Code Understanding and Generation
May 09, 2023We present The Vault, an open-source, large-scale code-text dataset designed to enhance the training of code-focused large language models (LLMs). Existing open-source datasets for training code-based LLMs often face challenges in terms of size, quality (due to noisy signals), and format (only containing code function and text explanation pairings). The Vault overcomes these limitations by providing 40 million code-text pairs across 10 popular programming languages, thorough cleaning for 10+ prevalent issues, and various levels of code-text pairings, including class, function, and line levels. Researchers and practitioners can utilize The Vault for training diverse code-focused LLMs or incorporate the provided data cleaning methods and scripts to improve their datasets. By employing The Vault as the training dataset for code-centric LLMs, we anticipate significant advancements in code understanding and generation tasks, fostering progress in both artificial intelligence research and software development practices.
Better Language Models of Code through Self-Improvement
Apr 02, 2023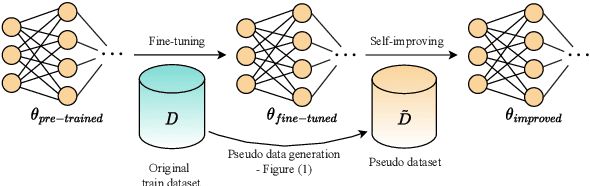
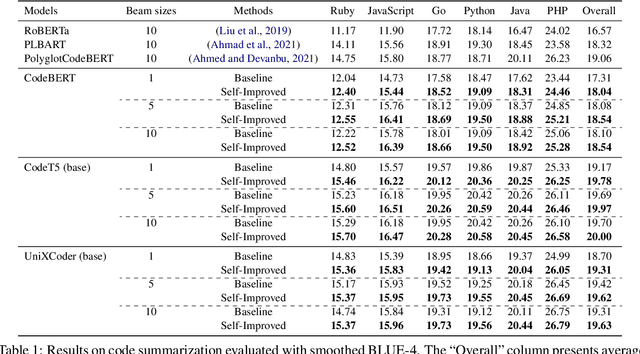
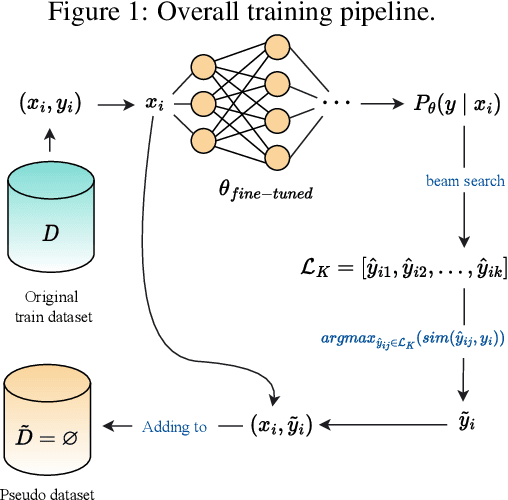
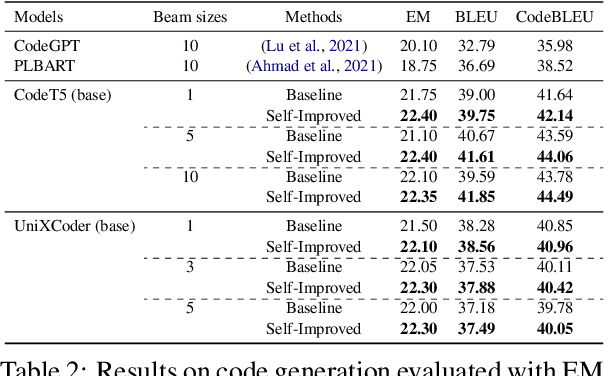
Pre-trained language models for code (PLMCs) have gained attention in recent research. These models are pre-trained on large-scale datasets using multi-modal objectives. However, fine-tuning them requires extensive supervision and is limited by the size of the dataset provided. We aim to improve this issue by proposing a simple data augmentation framework. Our framework utilizes knowledge gained during the pre-training and fine-tuning stage to generate pseudo data, which is then used as training data for the next step. We incorporate this framework into the state-of-the-art language models, such as CodeT5, CodeBERT, and UnixCoder. The results show that our framework significantly improves PLMCs' performance in code-related sequence generation tasks, such as code summarization and code generation in the CodeXGLUE benchmark.
Continuous Temporal Graph Networks for Event-Based Graph Data
May 31, 2022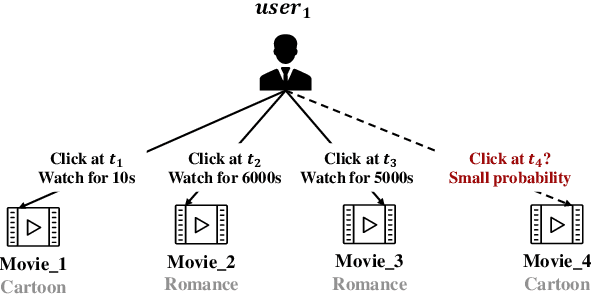
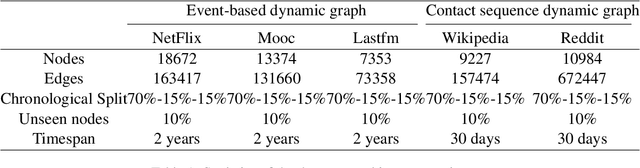
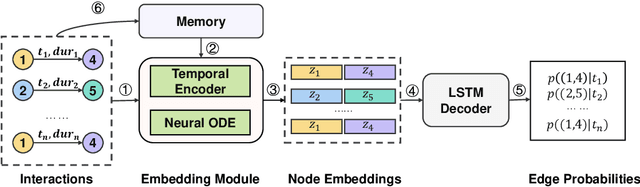
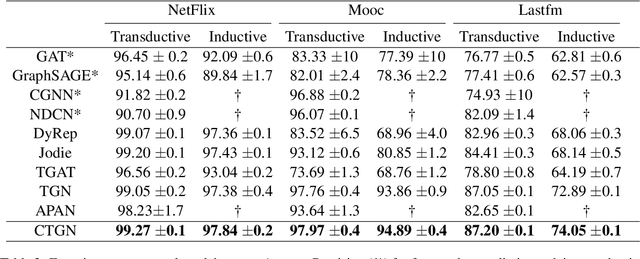
There has been an increasing interest in modeling continuous-time dynamics of temporal graph data. Previous methods encode time-evolving relational information into a low-dimensional representation by specifying discrete layers of neural networks, while real-world dynamic graphs often vary continuously over time. Hence, we propose Continuous Temporal Graph Networks (CTGNs) to capture the continuous dynamics of temporal graph data. We use both the link starting timestamps and link duration as evolving information to model the continuous dynamics of nodes. The key idea is to use neural ordinary differential equations (ODE) to characterize the continuous dynamics of node representations over dynamic graphs. We parameterize ordinary differential equations using a novel graph neural network. The existing dynamic graph networks can be considered as a specific discretization of CTGNs. Experiment results on both transductive and inductive tasks demonstrate the effectiveness of our proposed approach over competitive baselines.
Stock Trading Optimization through Model-based Reinforcement Learning with Resistance Support Relative Strength
May 30, 2022

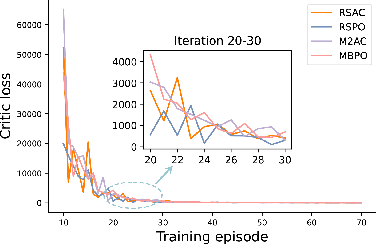
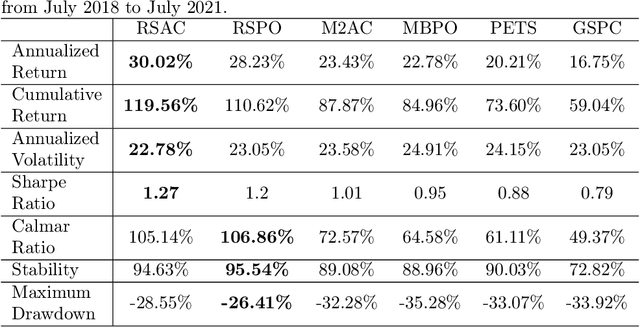
Reinforcement learning (RL) is gaining attention by more and more researchers in quantitative finance as the agent-environment interaction framework is aligned with decision making process in many business problems. Most of the current financial applications using RL algorithms are based on model-free method, which still faces stability and adaptivity challenges. As lots of cutting-edge model-based reinforcement learning (MBRL) algorithms mature in applications such as video games or robotics, we design a new approach that leverages resistance and support (RS) level as regularization terms for action in MBRL, to improve the algorithm's efficiency and stability. From the experiment results, we can see RS level, as a market timing technique, enhances the performance of pure MBRL models in terms of various measurements and obtains better profit gain with less riskiness. Besides, our proposed method even resists big drop (less maximum drawdown) during COVID-19 pandemic period when the financial market got unpredictable crisis. Explanations on why control of resistance and support level can boost MBRL is also investigated through numerical experiments, such as loss of actor-critic network and prediction error of the transition dynamical model. It shows that RS indicators indeed help the MBRL algorithms to converge faster at early stage and obtain smaller critic loss as training episodes increase.