 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios
Dec 23, 2025



Existing benchmarks for AI coding agents focus on isolated, single-issue tasks such as fixing a bug or implementing a small feature. However, real-world software engineering is fundamentally a long-horizon endeavor: developers must interpret high-level requirements, plan coordinated changes across many files, and evolve codebases over multiple iterations while preserving existing functionality. We introduce SWE-EVO, a benchmark that evaluates agents on this long-horizon software evolution challenge. Constructed from release notes and version histories of seven mature open-source Python projects, Tool comprises 48 evolution tasks that require agents to implement multi-step modifications spanning an average of 21 files, validated against comprehensive test suites averaging 874 tests per instance. Experiments with state-of-the-art models reveal a striking capability gap: even GPT-5 with OpenHands achieves only a 21 percent resolution rate on Tool, compared to 65 percent on the single-issue SWE-Bench Verified. This demonstrates that current agents struggle with sustained, multi-file reasoning. We also propose Fix Rate, a fine-grained metric that captures partial progress toward solving these complex, long-horizon tasks.
The Vault: A Comprehensive Multilingual Dataset for Advancing Code Understanding and Generation
May 09, 2023We present The Vault, an open-source, large-scale code-text dataset designed to enhance the training of code-focused large language models (LLMs). Existing open-source datasets for training code-based LLMs often face challenges in terms of size, quality (due to noisy signals), and format (only containing code function and text explanation pairings). The Vault overcomes these limitations by providing 40 million code-text pairs across 10 popular programming languages, thorough cleaning for 10+ prevalent issues, and various levels of code-text pairings, including class, function, and line levels. Researchers and practitioners can utilize The Vault for training diverse code-focused LLMs or incorporate the provided data cleaning methods and scripts to improve their datasets. By employing The Vault as the training dataset for code-centric LLMs, we anticipate significant advancements in code understanding and generation tasks, fostering progress in both artificial intelligence research and software development practices.
ViWOZ: A Multi-Domain Task-Oriented Dialogue Systems Dataset For Low-resource Language
Mar 15, 2022

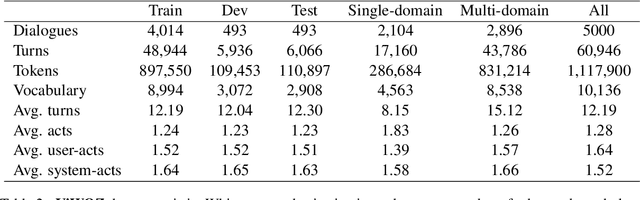

Most of the current task-oriented dialogue systems (ToD), despite having interesting results, are designed for a handful of languages like Chinese and English. Therefore, their performance in low-resource languages is still a significant problem due to the absence of a standard dataset and evaluation policy. To address this problem, we proposed ViWOZ, a fully-annotated Vietnamese task-oriented dialogue dataset. ViWOZ is the first multi-turn, multi-domain tasked oriented dataset in Vietnamese, a low-resource language. The dataset consists of a total of 5,000 dialogues, including 60,946 fully annotated utterances. Furthermore, we provide a comprehensive benchmark of both modular and end-to-end models in low-resource language scenarios. With those characteristics, the ViWOZ dataset enables future studies on creating a multilingual task-oriented dialogue system.