 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViWOZ: A Multi-Domain Task-Oriented Dialogue Systems Dataset For Low-resource Language
Paper and Code
Mar 15, 2022

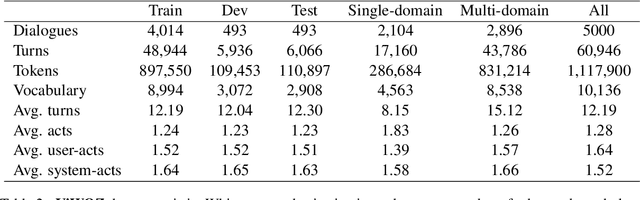

Most of the current task-oriented dialogue systems (ToD), despite having interesting results, are designed for a handful of languages like Chinese and English. Therefore, their performance in low-resource languages is still a significant problem due to the absence of a standard dataset and evaluation policy. To address this problem, we proposed ViWOZ, a fully-annotated Vietnamese task-oriented dialogue dataset. ViWOZ is the first multi-turn, multi-domain tasked oriented dataset in Vietnamese, a low-resource language. The dataset consists of a total of 5,000 dialogues, including 60,946 fully annotated utterances. Furthermore, we provide a comprehensive benchmark of both modular and end-to-end models in low-resource language scenarios. With those characteristics, the ViWOZ dataset enables future studies on creating a multilingual task-oriented dialogue system.