 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetail store customer behavior analysis system: Design and Implementation
Sep 05, 2023



Understanding customer behavior in retail stores plays a crucial role in improving customer satisfaction by adding personalized value to services. Behavior analysis reveals both general and detailed patterns in the interaction of customers with a store items and other people, providing store managers with insight into customer preferences. Several solutions aim to utilize this data by recognizing specific behaviors through statistical visualization. However, current approaches are limited to the analysis of small customer behavior sets, utilizing conventional methods to detect behaviors. They do not use deep learning techniques such as deep neural networks, which are powerful methods in the field of computer vision. Furthermore, these methods provide limited figures when visualizing the behavioral data acquired by the system. In this study, we propose a framework that includes three primary parts: mathematical modeling of customer behaviors, behavior analysis using an efficient deep learning based system, and individual and group behavior visualization. Each module and the entire system were validated using data from actual situations in a retail store.
F2SD: A dataset for end-to-end group detection algorithms
Nov 20, 2022The lack of large-scale datasets has been impeding the advance of deep learning approaches to the problem of F-formation detection. Moreover, most research works on this problem rely on input sensor signals of object location and orientation rather than image signals. To address this, we develop a new, large-scale dataset of simulated images for F-formation detection, called F-formation Simulation Dataset (F2SD). F2SD contains nearly 60,000 images simulated from GTA-5, with bounding boxes and orientation information on images, making it useful for a wide variety of modelling approaches. It is also closer to practical scenarios, where three-dimensional location and orientation information are costly to record. It is challenging to construct such a large-scale simulated dataset while keeping it realistic. Furthermore, the available research utilizes conventional methods to detect groups. They do not detect groups directly from the image. In this work, we propose (1) a large-scale simulation dataset F2SD and a pipeline for F-formation simulation, (2) a first-ever end-to-end baseline model for the task, and experiments on our simulation dataset.
ViWOZ: A Multi-Domain Task-Oriented Dialogue Systems Dataset For Low-resource Language
Mar 15, 2022

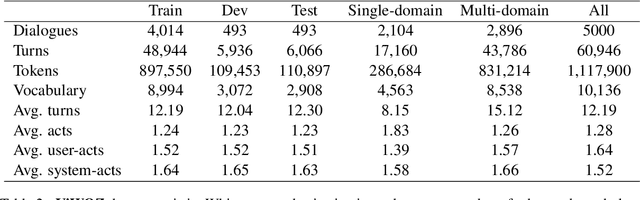

Most of the current task-oriented dialogue systems (ToD), despite having interesting results, are designed for a handful of languages like Chinese and English. Therefore, their performance in low-resource languages is still a significant problem due to the absence of a standard dataset and evaluation policy. To address this problem, we proposed ViWOZ, a fully-annotated Vietnamese task-oriented dialogue dataset. ViWOZ is the first multi-turn, multi-domain tasked oriented dataset in Vietnamese, a low-resource language. The dataset consists of a total of 5,000 dialogues, including 60,946 fully annotated utterances. Furthermore, we provide a comprehensive benchmark of both modular and end-to-end models in low-resource language scenarios. With those characteristics, the ViWOZ dataset enables future studies on creating a multilingual task-oriented dialogue system.