 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of a Vision System to Enhance the Reliability of the Pick-and-Place Robot for Autonomous Testing of Camera Module used in Smartphones
May 08, 2023
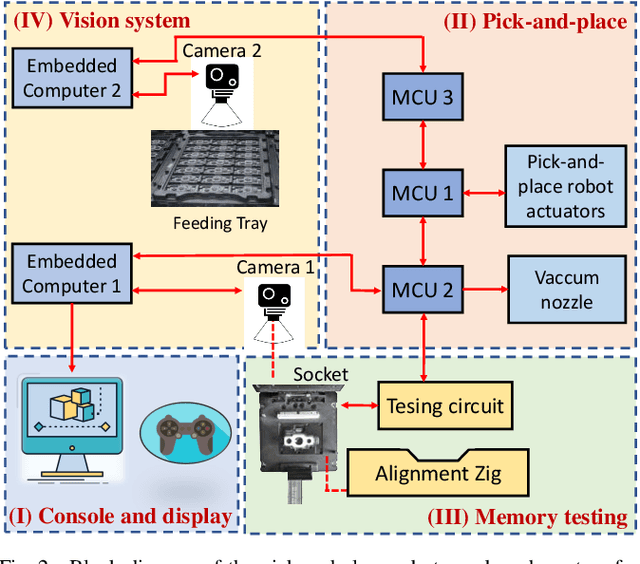

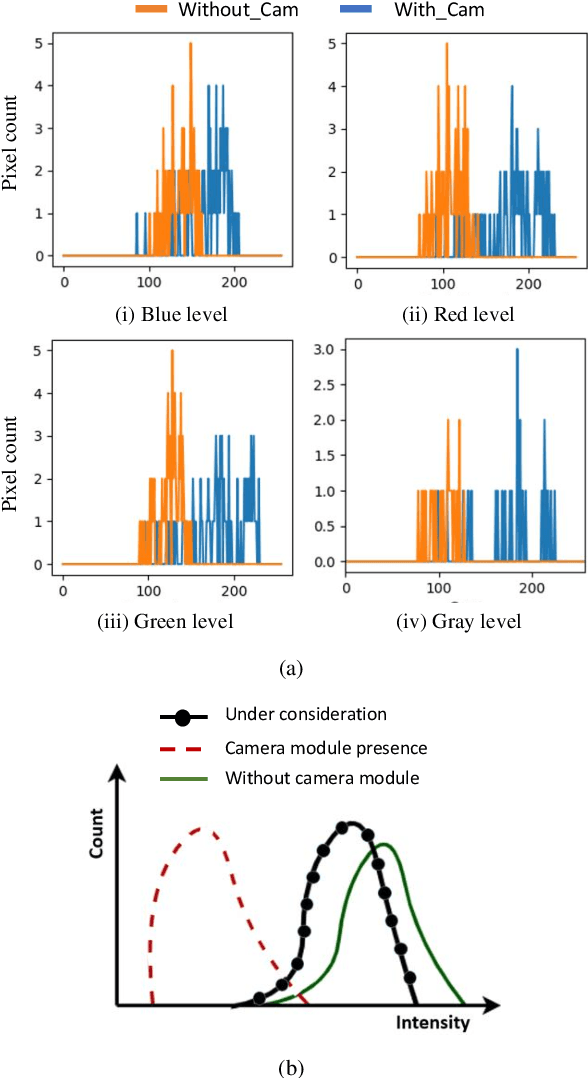
Pick-and-place robots are commonly used in modern industrial manufacturing. For complex devices/parts like camera modules used in smartphones, which contain optical parts, electrical components and interfacing connectors, the placement operation may not absolutely accurate, which may cause damage in the device under test during the mechanical movement to make good contact for electrical functions inspection. In this paper, we proposed an effective vision system including hardware and algorithm to enhance the reliability of the pick-and-place robot for autonomous testing memory of camera modules. With limited hardware based on camera and raspberry PI and using simplify image processing algorithm based on histogram information, the vision system can confirm the presence of the camera modules in feeding tray and the placement accuracy of the camera module in test socket. Through that, the system can work with more flexibility and avoid damaging the device under test. The system was experimentally quantified through testing approximately 2000 camera modules in a stable light condition. Experimental results demonstrate that the system achieves accuracy of more than 99.92%. With its simplicity and effectiveness, the proposed vision system can be considered as a useful solution for using in pick-and-place systems in industry.
F2SD: A dataset for end-to-end group detection algorithms
Nov 20, 2022The lack of large-scale datasets has been impeding the advance of deep learning approaches to the problem of F-formation detection. Moreover, most research works on this problem rely on input sensor signals of object location and orientation rather than image signals. To address this, we develop a new, large-scale dataset of simulated images for F-formation detection, called F-formation Simulation Dataset (F2SD). F2SD contains nearly 60,000 images simulated from GTA-5, with bounding boxes and orientation information on images, making it useful for a wide variety of modelling approaches. It is also closer to practical scenarios, where three-dimensional location and orientation information are costly to record. It is challenging to construct such a large-scale simulated dataset while keeping it realistic. Furthermore, the available research utilizes conventional methods to detect groups. They do not detect groups directly from the image. In this work, we propose (1) a large-scale simulation dataset F2SD and a pipeline for F-formation simulation, (2) a first-ever end-to-end baseline model for the task, and experiments on our simulation dataset.
Simultaneous face detection and 360 degree headpose estimation
Nov 23, 2021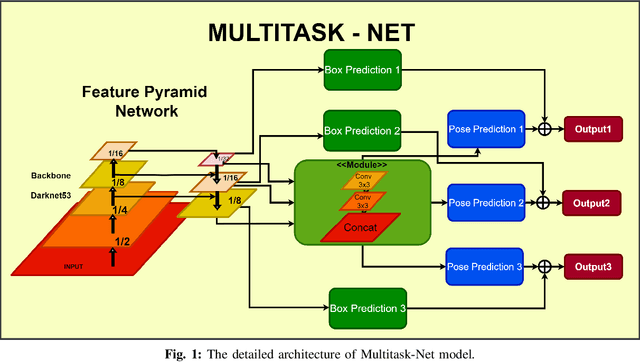
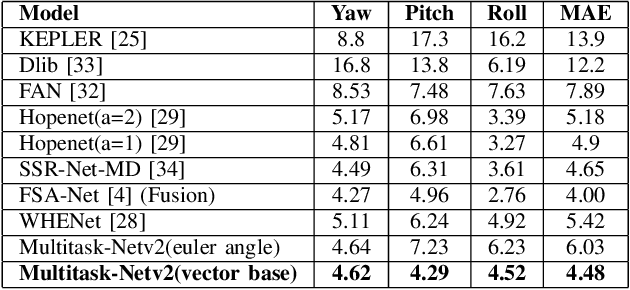
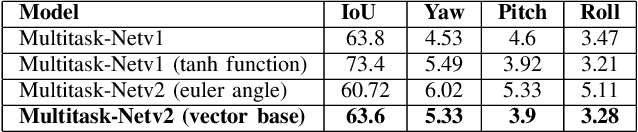
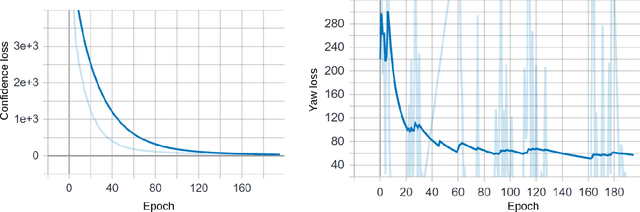
With many practical applications in human life, including manufacturing surveillance cameras, analyzing and processing customer behavior, many researchers are noticing face detection and head pose estimation on digital images. A large number of proposed deep learning models have state-of-the-art accuracy such as YOLO, SSD, MTCNN, solving the problem of face detection or HopeNet, FSA-Net, RankPose model used for head pose estimation problem. According to many state-of-the-art methods, the pipeline of this task consists of two parts, from face detection to head pose estimation. These two steps are completely independent and do not share information. This makes the model clear in setup but does not leverage most of the featured resources extracted in each model. In this paper, we proposed the Multitask-Net model with the motivation to leverage the features extracted from the face detection model, sharing them with the head pose estimation branch to improve accuracy. Also, with the variety of data, the Euler angle domain representing the face is large, our model can predict with results in the 360 Euler angle domain. Applying the multitask learning method, the Multitask-Net model can simultaneously predict the position and direction of the human head. To increase the ability to predict the head direction of the model, we change there presentation of the human face from the Euler angle to vectors of the Rotation matrix.
UET-Headpose: A sensor-based top-view head pose dataset
Nov 13, 2021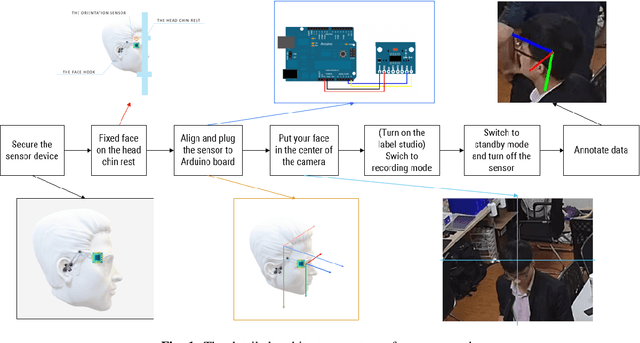
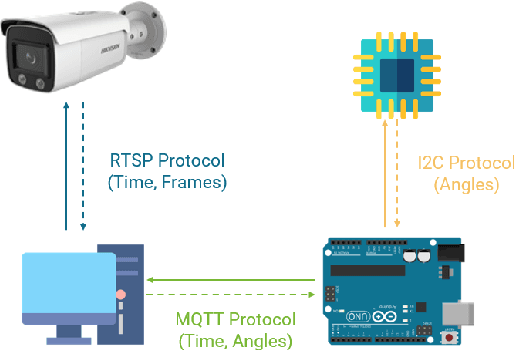
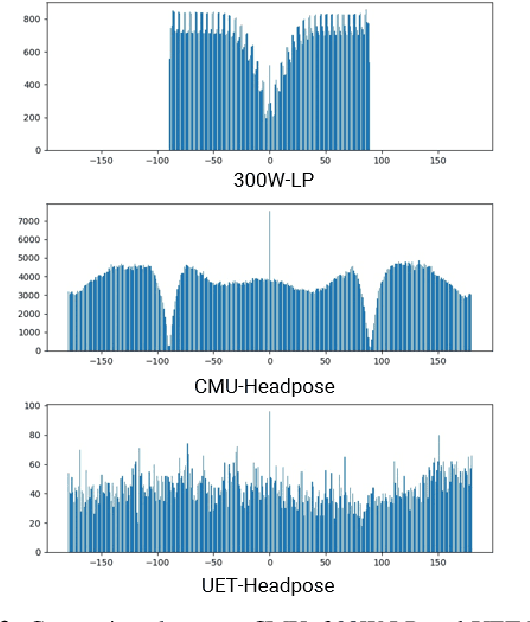
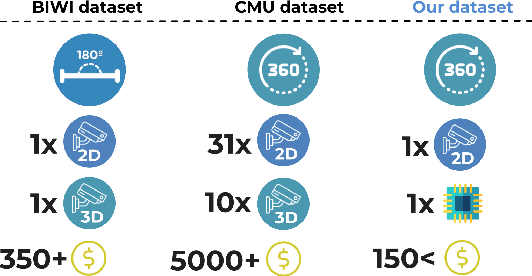
Head pose estimation is a challenging task that aims to solve problems related to predicting three dimensions vector, that serves for many applications in human-robot interaction or customer behavior. Previous researches have proposed some precise methods for collecting head pose data. But those methods require either expensive devices like depth cameras or complex laboratory environment setup. In this research, we introduce a new approach with efficient cost and easy setup to collecting head pose images, namely UET-Headpose dataset, with top-view head pose data. This method uses an absolute orientation sensor instead of Depth cameras to be set up quickly and small cost but still ensure good results. Through experiments, our dataset has been shown the difference between its distribution and available dataset like CMU Panoptic Dataset \cite{CMU}. Besides using the UET-Headpose dataset and other head pose datasets, we also introduce the full-range model called FSANet-Wide, which significantly outperforms head pose estimation results by the UET-Headpose dataset, especially on top-view images. Also, this model is very lightweight and takes small size images.