 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Enhanced Sampling-Based Method With Modified Next-Best View Strategy For 2D Autonomous Robot Exploration
May 08, 2023



Autonomous exploration is a new technology in the field of robotics that has found widespread application due to its objective to help robots independently localize, scan maps, and navigate any terrain without human control. Up to present, the sampling-based exploration strategies have been the most effective for aerial and ground vehicles equipped with depth sensors producing three-dimensional point clouds. Those methods utilize the sampling task to choose random points or make samples based on Rapidly-exploring Random Trees (RRT). Then, they decide on frontiers or Next Best Views (NBV) with useful volumetric information. However, most state-of-the-art sampling-based methodology is challenging to implement in two-dimensional robots due to the lack of environmental knowledge, thus resulting in a bad volumetric gain for evaluating random destinations. This study proposed an enhanced sampling-based solution for indoor robot exploration to decide Next Best View (NBV) in 2D environments. Our method makes RRT until have the endpoints as frontiers and evaluates those with the enhanced utility function. The volumetric information obtained from environments was estimated using non-uniform distribution to determine cells that are occupied and have an uncertain probability. Compared to the sampling-based Frontier Detection and Receding Horizon NBV approaches, the methodology executed performed better in Gazebo platform-simulated environments, achieving a significantly larger explored area, with the average distance and time traveled being reduced. Moreover, the operated proposed method on an author-built 2D robot exploring the entire natural environment confirms that the method is effective and applicable in real-world scenarios.
A sensor fusion approach for improving implementation speed and accuracy of RTAB-Map algorithm based indoor 3D mapping
May 08, 2023



In recent years, 3D mapping for indoor environments has undergone considerable research and improvement because of its effective applications in various fields, including robotics, autonomous navigation, and virtual reality. Building an accurate 3D map for indoor environment is challenging due to the complex nature of the indoor space, the problem of real-time embedding and positioning errors of the robot system. This study proposes a method to improve the accuracy, speed, and quality of 3D indoor mapping by fusing data from the Inertial Measurement System (IMU) of the Intel Realsense D435i camera, the Ultrasonic-based Indoor Positioning System (IPS), and the encoder of the robot's wheel using the extended Kalman filter (EKF) algorithm. The merged data is processed using a Real-time Image Based Mapping algorithm (RTAB-Map), with the processing frequency updated in synch with the position frequency of the IPS device. The results suggest that fusing IMU and IPS data significantly improves the accuracy, mapping time, and quality of 3D maps. Our study highlights the proposed method's potential to improve indoor mapping in various fields, indicating that the fusion of multiple data sources can be a valuable tool in creating high-quality 3D indoor maps.
Development of a Vision System to Enhance the Reliability of the Pick-and-Place Robot for Autonomous Testing of Camera Module used in Smartphones
May 08, 2023
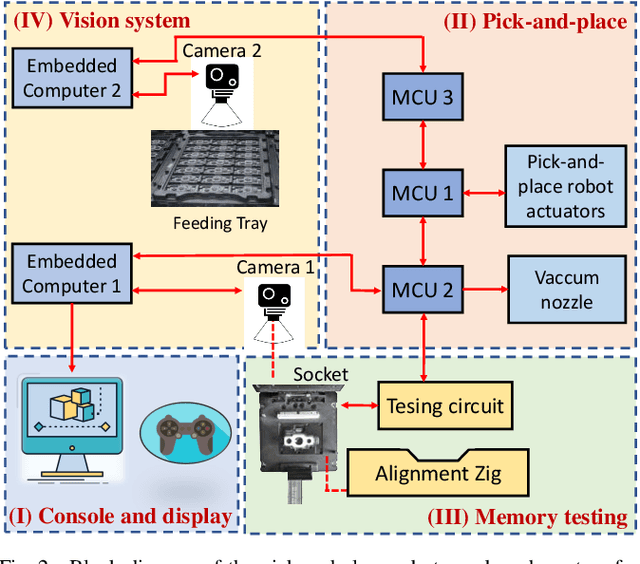

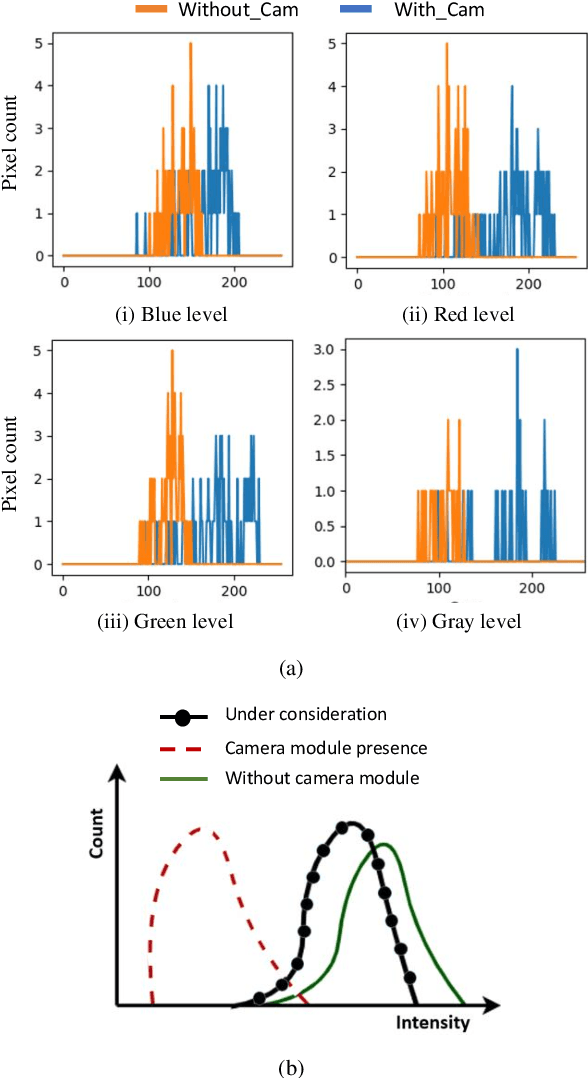
Pick-and-place robots are commonly used in modern industrial manufacturing. For complex devices/parts like camera modules used in smartphones, which contain optical parts, electrical components and interfacing connectors, the placement operation may not absolutely accurate, which may cause damage in the device under test during the mechanical movement to make good contact for electrical functions inspection. In this paper, we proposed an effective vision system including hardware and algorithm to enhance the reliability of the pick-and-place robot for autonomous testing memory of camera modules. With limited hardware based on camera and raspberry PI and using simplify image processing algorithm based on histogram information, the vision system can confirm the presence of the camera modules in feeding tray and the placement accuracy of the camera module in test socket. Through that, the system can work with more flexibility and avoid damaging the device under test. The system was experimentally quantified through testing approximately 2000 camera modules in a stable light condition. Experimental results demonstrate that the system achieves accuracy of more than 99.92%. With its simplicity and effectiveness, the proposed vision system can be considered as a useful solution for using in pick-and-place systems in industry.
LAPFormer: A Light and Accurate Polyp Segmentation Transformer
Oct 10, 2022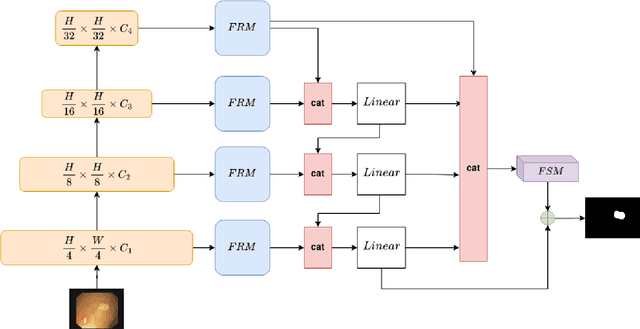
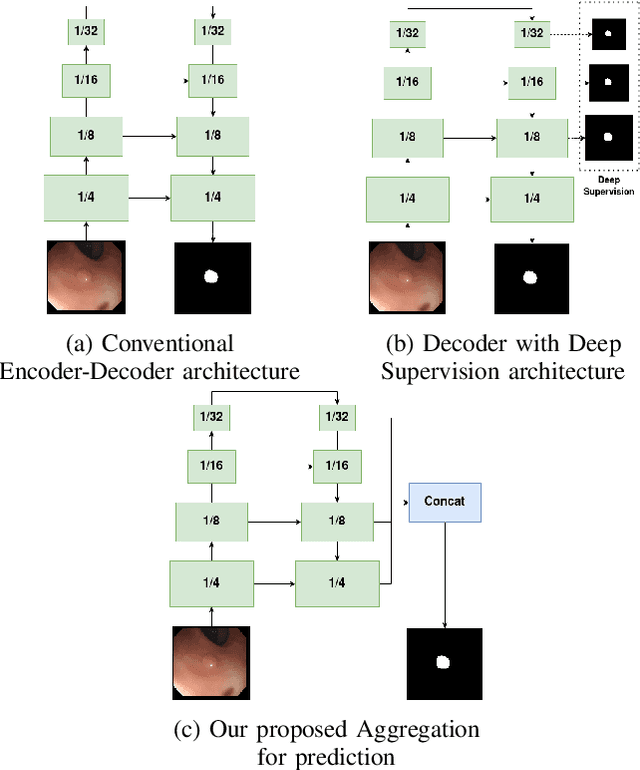
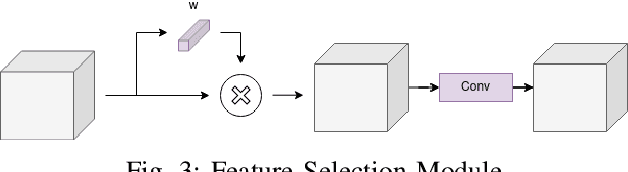

Polyp segmentation is still known as a difficult problem due to the large variety of polyp shapes, scanning and labeling modalities. This prevents deep learning model to generalize well on unseen data. However, Transformer-based approach recently has achieved some remarkable results on performance with the ability of extracting global context better than CNN-based architecture and yet lead to better generalization. To leverage this strength of Transformer, we propose a new model with encoder-decoder architecture named LAPFormer, which uses a hierarchical Transformer encoder to better extract global feature and combine with our novel CNN (Convolutional Neural Network) decoder for capturing local appearance of the polyps. Our proposed decoder contains a progressive feature fusion module designed for fusing feature from upper scales and lower scales and enable multi-scale features to be more correlative. Besides, we also use feature refinement module and feature selection module for processing feature. We test our model on five popular benchmark datasets for polyp segmentation, including Kvasir, CVC-Clinic DB, CVC-ColonDB, CVC-T, and ETIS-Larib