 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchocardiography video synthesis from end diastolic semantic map via diffusion model
Oct 11, 2023Denoising Diffusion Probabilistic Models (DDPMs) have demonstrated significant achievements in various image and video generation tasks, including the domain of medical imaging. However, generating echocardiography videos based on semantic anatomical information remains an unexplored area of research. This is mostly due to the constraints imposed by the currently available datasets, which lack sufficient scale and comprehensive frame-wise annotations for every cardiac cycle. This paper aims to tackle the aforementioned challenges by expanding upon existing video diffusion models for the purpose of cardiac video synthesis. More specifically, our focus lies in generating video using semantic maps of the initial frame during the cardiac cycle, commonly referred to as end diastole. To further improve the synthesis process, we integrate spatial adaptive normalization into multiscale feature maps. This enables the inclusion of semantic guidance during synthesis, resulting in enhanced realism and coherence of the resultant video sequences. Experiments are conducted on the CAMUS dataset, which is a highly used dataset in the field of echocardiography. Our model exhibits better performance compared to the standard diffusion technique in terms of multiple metrics, including FID, FVD, and SSMI.
Simultaneous face detection and 360 degree headpose estimation
Nov 23, 2021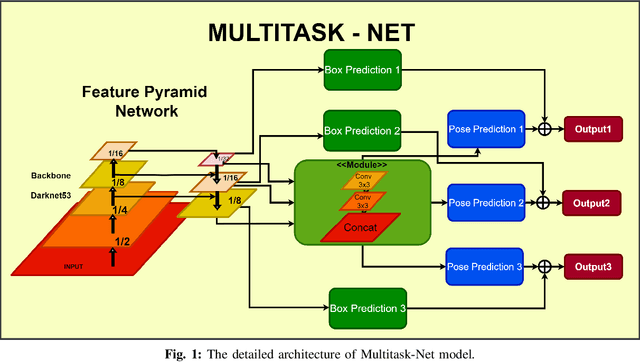
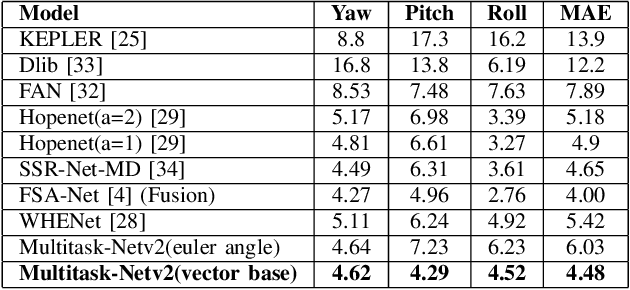
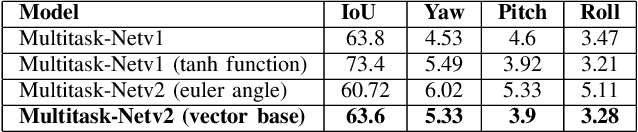
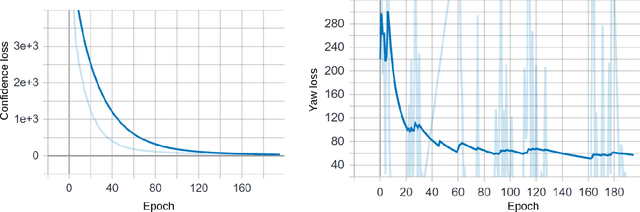
With many practical applications in human life, including manufacturing surveillance cameras, analyzing and processing customer behavior, many researchers are noticing face detection and head pose estimation on digital images. A large number of proposed deep learning models have state-of-the-art accuracy such as YOLO, SSD, MTCNN, solving the problem of face detection or HopeNet, FSA-Net, RankPose model used for head pose estimation problem. According to many state-of-the-art methods, the pipeline of this task consists of two parts, from face detection to head pose estimation. These two steps are completely independent and do not share information. This makes the model clear in setup but does not leverage most of the featured resources extracted in each model. In this paper, we proposed the Multitask-Net model with the motivation to leverage the features extracted from the face detection model, sharing them with the head pose estimation branch to improve accuracy. Also, with the variety of data, the Euler angle domain representing the face is large, our model can predict with results in the 360 Euler angle domain. Applying the multitask learning method, the Multitask-Net model can simultaneously predict the position and direction of the human head. To increase the ability to predict the head direction of the model, we change there presentation of the human face from the Euler angle to vectors of the Rotation matrix.
UET-Headpose: A sensor-based top-view head pose dataset
Nov 13, 2021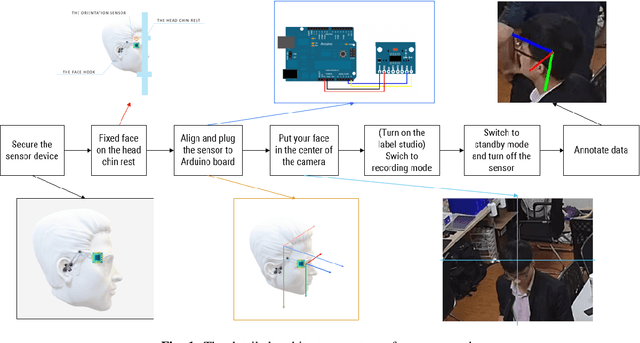
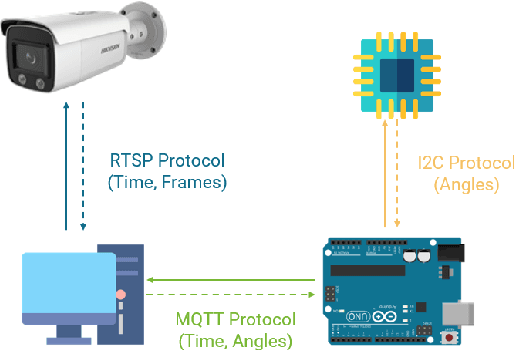
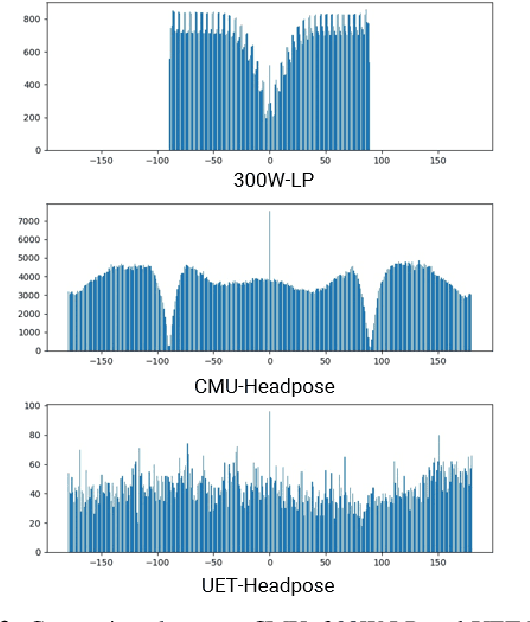
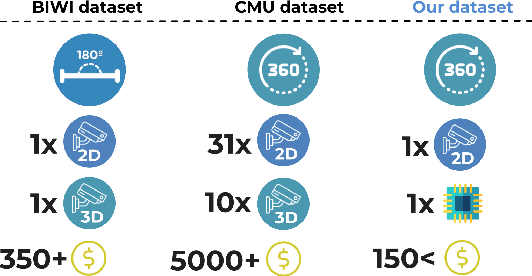
Head pose estimation is a challenging task that aims to solve problems related to predicting three dimensions vector, that serves for many applications in human-robot interaction or customer behavior. Previous researches have proposed some precise methods for collecting head pose data. But those methods require either expensive devices like depth cameras or complex laboratory environment setup. In this research, we introduce a new approach with efficient cost and easy setup to collecting head pose images, namely UET-Headpose dataset, with top-view head pose data. This method uses an absolute orientation sensor instead of Depth cameras to be set up quickly and small cost but still ensure good results. Through experiments, our dataset has been shown the difference between its distribution and available dataset like CMU Panoptic Dataset \cite{CMU}. Besides using the UET-Headpose dataset and other head pose datasets, we also introduce the full-range model called FSANet-Wide, which significantly outperforms head pose estimation results by the UET-Headpose dataset, especially on top-view images. Also, this model is very lightweight and takes small size images.