 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stochastic Dynamical Systems as an Implicit Regularization with Graph Neural Networks
Jul 12, 2023Stochastic Gumbel graph networks are proposed to learn high-dimensional time series, where the observed dimensions are often spatially correlated. To that end, the observed randomness and spatial-correlations are captured by learning the drift and diffusion terms of the stochastic differential equation with a Gumble matrix embedding, respectively. In particular, this novel framework enables us to investigate the implicit regularization effect of the noise terms in S-GGNs. We provide a theoretical guarantee for the proposed S-GGNs by deriving the difference between the two corresponding loss functions in a small neighborhood of weight. Then, we employ Kuramoto's model to generate data for comparing the spectral density from the Hessian Matrix of the two loss functions. Experimental results on real-world data, demonstrate that S-GGNs exhibit superior convergence, robustness, and generalization, compared with state-of-the-arts.
Meta contrastive label correction for financial time series
Mar 09, 2023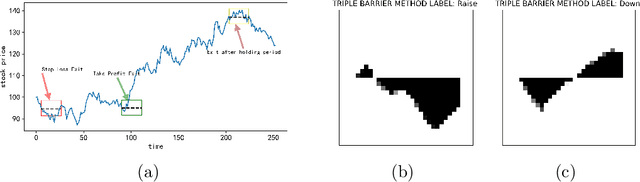
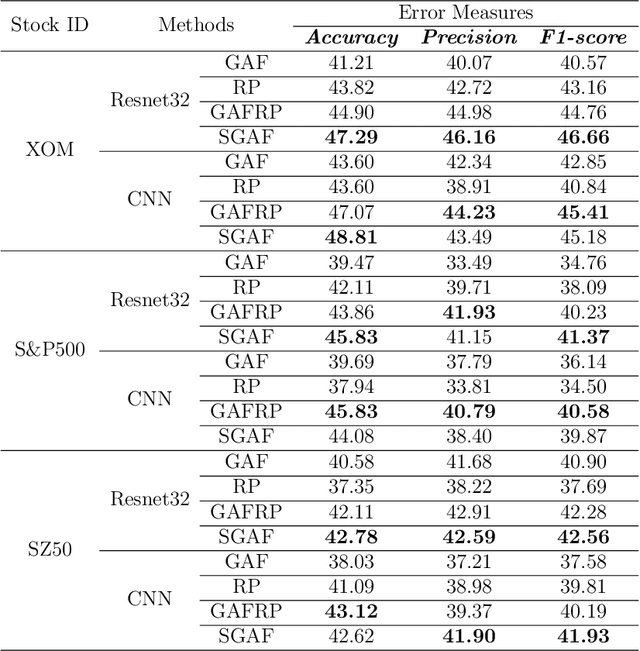
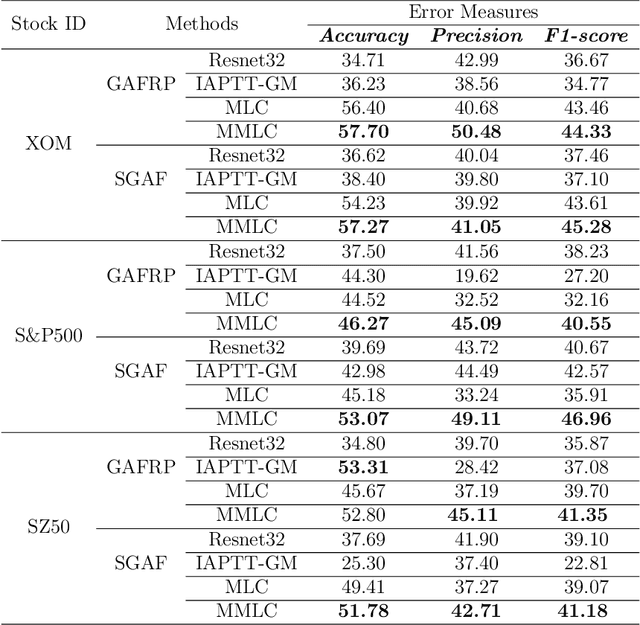
Financial applications such as stock price forecasting, usually face an issue that under the predefined labeling rules, it is hard to accurately predict the directions of stock movement. This is because traditional ways of labeling, taking Triple Barrier Method, for example, usually gives us inaccurate or even corrupted labels. To address this issue, we focus on two main goals. One is that our proposed method can automatically generate correct labels for noisy time series patterns, while at the same time, the method is capable of boosting classification performance on this new labeled dataset. Based on the aforementioned goals, our approach has the following three novelties: First, we fuse a new contrastive learning algorithm into the meta-learning framework to estimate correct labels iteratively when updating the classification model inside. Moreover, we utilize images generated from time series data through Gramian angular field and representative learning. Most important of all, we adopt multi-task learning to forecast temporal-variant labels. In the experiments, we work on 6% clean data and the rest unlabeled data. It is shown that our method is competitive and outperforms a lot compared with benchmarks.