 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Domain Adaptation through Prompt Gradient Alignment
Jun 13, 2024Prior Unsupervised Domain Adaptation (UDA) methods often aim to train a domain-invariant feature extractor, which may hinder the model from learning sufficiently discriminative features. To tackle this, a line of works based on prompt learning leverages the power of large-scale pre-trained vision-language models to learn both domain-invariant and specific features through a set of domain-agnostic and domain-specific learnable prompts. Those studies typically enforce invariant constraints on representation, output, or prompt space to learn such prompts. Differently, we cast UDA as a multiple-objective optimization problem in which each objective is represented by a domain loss. Under this new framework, we propose aligning per-objective gradients to foster consensus between them. Additionally, to prevent potential overfitting when fine-tuning this deep learning architecture, we penalize the norm of these gradients. To achieve these goals, we devise a practical gradient update procedure that can work under both single-source and multi-source UDA. Empirically, our method consistently surpasses other prompt-based baselines by a large margin on different UDA benchmarks
KOPPA: Improving Prompt-based Continual Learning with Key-Query Orthogonal Projection and Prototype-based One-Versus-All
Nov 30, 2023



Drawing inspiration from prompt tuning techniques applied to Large Language Models, recent methods based on pre-trained ViT networks have achieved remarkable results in the field of Continual Learning. Specifically, these approaches propose to maintain a set of prompts and allocate a subset of them to learn each task using a key-query matching strategy. However, they may encounter limitations when lacking control over the correlations between old task queries and keys of future tasks, the shift of features in the latent space, and the relative separation of latent vectors learned in independent tasks. In this work, we introduce a novel key-query learning strategy based on orthogonal projection, inspired by model-agnostic meta-learning, to enhance prompt matching efficiency and address the challenge of shifting features. Furthermore, we introduce a One-Versus-All (OVA) prototype-based component that enhances the classification head distinction. Experimental results on benchmark datasets demonstrate that our method empowers the model to achieve results surpassing those of current state-of-the-art approaches by a large margin of up to 20%.
Robust Contrastive Learning With Theory Guarantee
Nov 16, 2023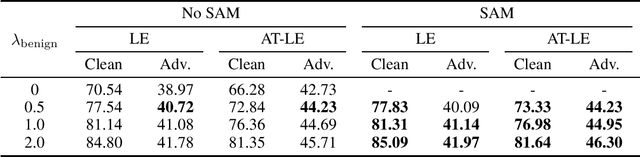

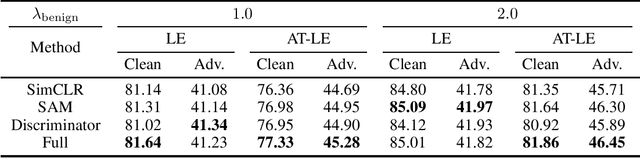
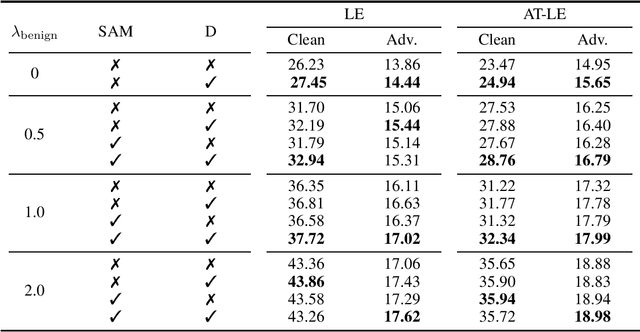
Contrastive learning (CL) is a self-supervised training paradigm that allows us to extract meaningful features without any label information. A typical CL framework is divided into two phases, where it first tries to learn the features from unlabelled data, and then uses those features to train a linear classifier with the labeled data. While a fair amount of existing theoretical works have analyzed how the unsupervised loss in the first phase can support the supervised loss in the second phase, none has examined the connection between the unsupervised loss and the robust supervised loss, which can shed light on how to construct an effective unsupervised loss for the first phase of CL. To fill this gap, our work develops rigorous theories to dissect and identify which components in the unsupervised loss can help improve the robust supervised loss and conduct proper experiments to verify our findings.
Conditional Support Alignment for Domain Adaptation with Label Shift
May 29, 2023



Unsupervised domain adaptation (UDA) refers to a domain adaptation framework in which a learning model is trained based on the labeled samples on the source domain and unlabelled ones in the target domain. The dominant existing methods in the field that rely on the classical covariate shift assumption to learn domain-invariant feature representation have yielded suboptimal performance under the label distribution shift between source and target domains. In this paper, we propose a novel conditional adversarial support alignment (CASA) whose aim is to minimize the conditional symmetric support divergence between the source's and target domain's feature representation distributions, aiming at a more helpful representation for the classification task. We also introduce a novel theoretical target risk bound, which justifies the merits of aligning the supports of conditional feature distributions compared to the existing marginal support alignment approach in the UDA settings. We then provide a complete training process for learning in which the objective optimization functions are precisely based on the proposed target risk bound. Our empirical results demonstrate that CASA outperforms other state-of-the-art methods on different UDA benchmark tasks under label shift conditions.
Improving Multi-task Learning via Seeking Task-based Flat Regions
Nov 24, 2022



Multi-Task Learning (MTL) is a widely-used and powerful learning paradigm for training deep neural networks that allows learning more than one objective by a single backbone. Compared to training tasks separately, MTL significantly reduces computational costs, improves data efficiency, and potentially enhances model performance by leveraging knowledge across tasks. Hence, it has been adopted in a variety of applications, ranging from computer vision to natural language processing and speech recognition. Among them, there is an emerging line of work in MTL that focuses on manipulating the task gradient to derive an ultimate gradient descent direction to benefit all tasks. Despite achieving impressive results on many benchmarks, directly applying these approaches without using appropriate regularization techniques might lead to suboptimal solutions on real-world problems. In particular, standard training that minimizes the empirical loss on the training data can easily suffer from overfitting to low-resource tasks or be spoiled by noisy-labeled ones, which can cause negative transfer between tasks and overall performance drop. To alleviate such problems, we propose to leverage a recently introduced training method, named Sharpness-aware Minimization, which can enhance model generalization ability on single-task learning. Accordingly, we present a novel MTL training methodology, encouraging the model to find task-based flat minima for coherently improving its generalization capability on all tasks. Finally, we conduct comprehensive experiments on a variety of applications to demonstrate the merit of our proposed approach to existing gradient-based MTL methods, as suggested by our developed theory.
Security and Privacy Enhanced Gait Authentication with Random Representation Learning and Digital Lockers
Aug 05, 2021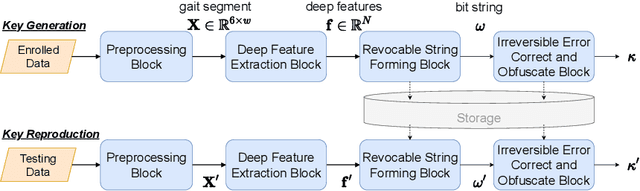
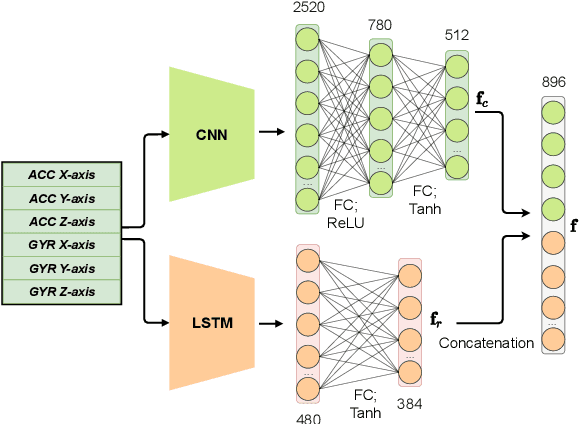
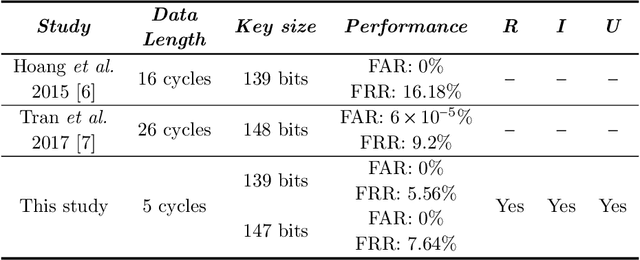

Gait data captured by inertial sensors have demonstrated promising results on user authentication. However, most existing approaches stored the enrolled gait pattern insecurely for matching with the validating pattern, thus, posed critical security and privacy issues. In this study, we present a gait cryptosystem that generates from gait data the random key for user authentication, meanwhile, secures the gait pattern. First, we propose a revocable and random binary string extraction method using a deep neural network followed by feature-wise binarization. A novel loss function for network optimization is also designed, to tackle not only the intrauser stability but also the inter-user randomness. Second, we propose a new biometric key generation scheme, namely Irreversible Error Correct and Obfuscate (IECO), improved from the Error Correct and Obfuscate (ECO) scheme, to securely generate from the binary string the random and irreversible key. The model was evaluated with two benchmark datasets as OU-ISIR and whuGAIT. We showed that our model could generate the key of 139 bits from 5-second data sequence with zero False Acceptance Rate (FAR) and False Rejection Rate (FRR) smaller than 5.441%. In addition, the security and user privacy analyses showed that our model was secure against existing attacks on biometric template protection, and fulfilled irreversibility and unlinkability.
From Implicit to Explicit feedback: A deep neural network for modeling sequential behaviours and long-short term preferences of online users
Jul 26, 2021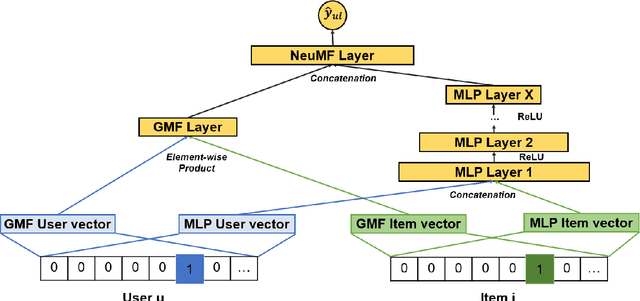
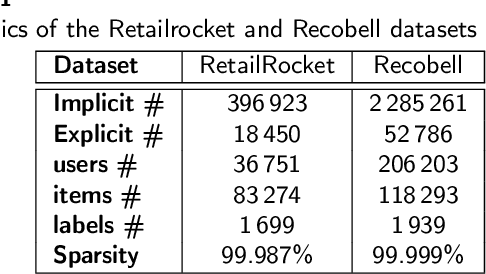
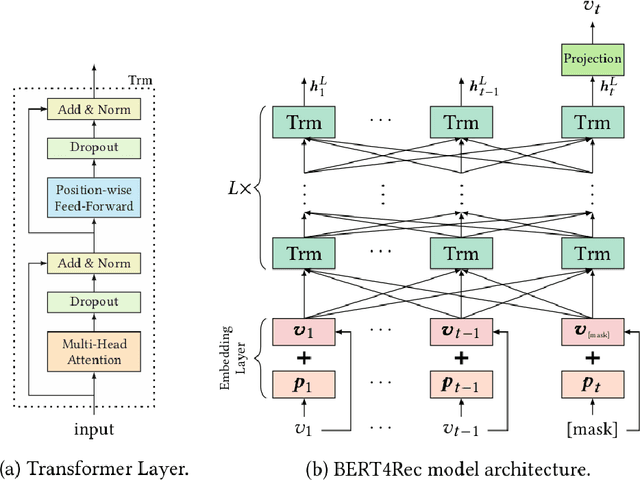
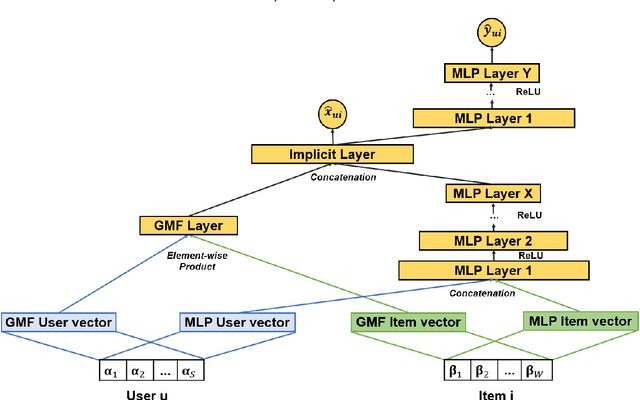
In this work, we examine the advantages of using multiple types of behaviour in recommendation systems. Intuitively, each user has to do some implicit actions (e.g., click) before making an explicit decision (e.g., purchase). Previous studies showed that implicit and explicit feedback have different roles for a useful recommendation. However, these studies either exploit implicit and explicit behaviour separately or ignore the semantic of sequential interactions between users and items. In addition, we go from the hypothesis that a user's preference at a time is a combination of long-term and short-term interests. In this paper, we propose some Deep Learning architectures. The first one is Implicit to Explicit (ITE), to exploit users' interests through the sequence of their actions. And two versions of ITE with Bidirectional Encoder Representations from Transformers based (BERT-based) architecture called BERT-ITE and BERT-ITE-Si, which combine users' long- and short-term preferences without and with side information to enhance user representation. The experimental results show that our models outperform previous state-of-the-art ones and also demonstrate our views on the effectiveness of exploiting the implicit to explicit order as well as combining long- and short-term preferences in two large-scale datasets.