 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCA: Local Classifier Alignment for Continual Learning
Mar 11, 2026A fundamental requirement for intelligent systems is the ability to learn continuously under changing environments. However, models trained in this regime often suffer from catastrophic forgetting. Leveraging pre-trained models has recently emerged as a promising solution, since their generalized feature extractors enable faster and more robust adaptation. While some earlier works mitigate forgetting by fine-tuning only on the first task, this approach quickly deteriorates as the number of tasks grows and the data distributions diverge. More recent research instead seeks to consolidate task knowledge into a unified backbone, or adapting the backbone as new tasks arrive. However, such approaches may create a (potential) \textit{mismatch} between task-specific classifiers and the adapted backbone. To address this issue, we propose a novel \textit{Local Classifier Alignment} (LCA) loss to better align the classifier with backbone. Theoretically, we show that this LCA loss can enable the classifier to not only generalize well for all observed tasks, but also improve robustness. Furthermore, we develop a complete solution for continual learning, following the model merging approach and using LCA. Extensive experiments on several standard benchmarks demonstrate that our method often achieves leading performance, sometimes surpasses the state-of-the-art methods with a large margin.
Provably Improving Generalization of Few-Shot Models with Synthetic Data
May 30, 2025Few-shot image classification remains challenging due to the scarcity of labeled training examples. Augmenting them with synthetic data has emerged as a promising way to alleviate this issue, but models trained on synthetic samples often face performance degradation due to the inherent gap between real and synthetic distributions. To address this limitation, we develop a theoretical framework that quantifies the impact of such distribution discrepancies on supervised learning, specifically in the context of image classification. More importantly, our framework suggests practical ways to generate good synthetic samples and to train a predictor with high generalization ability. Building upon this framework, we propose a novel theoretical-based algorithm that integrates prototype learning to optimize both data partitioning and model training, effectively bridging the gap between real few-shot data and synthetic data. Extensive experiments results show that our approach demonstrates superior performance compared to state-of-the-art methods, outperforming them across multiple datasets.
Weighted Average Gradients for Feature Attribution
May 06, 2025In explainable AI, Integrated Gradients (IG) is a widely adopted technique for assessing the significance of feature attributes of the input on model outputs by evaluating contributions from a baseline input to the current input. The choice of the baseline input significantly influences the resulting explanation. While the traditional Expected Gradients (EG) method assumes baselines can be uniformly sampled and averaged with equal weights, this study argues that baselines should not be treated equivalently. We introduce Weighted Average Gradients (WG), a novel approach that unsupervisedly evaluates baseline suitability and incorporates a strategy for selecting effective baselines. Theoretical analysis demonstrates that WG satisfies essential explanation method criteria and offers greater stability than prior approaches. Experimental results further confirm that WG outperforms EG across diverse scenarios, achieving an improvement of 10-35\% on main metrics. Moreover, by evaluating baselines, our method can filter a subset of effective baselines for each input to calculate explanations, maintaining high accuracy while reducing computational cost. The code is available at: https://github.com/Tamnt240904/weighted_baseline.
Non-vacuous Generalization Bounds for Deep Neural Networks without any modification to the trained models
Mar 10, 2025Deep neural network (NN) with millions or billions of parameters can perform really well on unseen data, after being trained from a finite training set. Various prior theories have been developed to explain such excellent ability of NNs, but do not provide a meaningful bound on the test error. Some recent theories, based on PAC-Bayes and mutual information, are non-vacuous and hence show a great potential to explain the excellent performance of NNs. However, they often require a stringent assumption and extensive modification (e.g. compression, quantization) to the trained model of interest. Therefore, those prior theories provide a guarantee for the modified versions only. In this paper, we propose two novel bounds on the test error of a model. Our bounds uses the training set only and require no modification to the model. Those bounds are verified on a large class of modern NNs, pretrained by Pytorch on the ImageNet dataset, and are non-vacuous. To the best of our knowledge, these are the first non-vacuous bounds at this large scale, without any modification to the pretrained models.
Gentle robustness implies Generalization
Dec 09, 2024Robustness and generalization ability of machine learning models are of utmost importance in various application domains. There is a wide interest in efficient ways to analyze those properties. One important direction is to analyze connection between those two properties. Prior theories suggest that a robust learning algorithm can produce trained models with a high generalization ability. However, we show in this work that the existing error bounds are vacuous for the Bayes optimal classifier which is the best among all measurable classifiers for a classification problem with overlapping classes. Those bounds cannot converge to the true error of this ideal classifier. This is undesirable, surprizing, and never known before. We then present a class of novel bounds, which are model-dependent and provably tighter than the existing robustness-based ones. Unlike prior ones, our bounds are guaranteed to converge to the true error of the best classifier, as the number of samples increases. We further provide an extensive experiment and find that two of our bounds are often non-vacuous for a large class of deep neural networks, pretrained from ImageNet.
On Inference Stability for Diffusion Models
Dec 19, 2023Denoising Probabilistic Models (DPMs) represent an emerging domain of generative models that excel in generating diverse and high-quality images. However, most current training methods for DPMs often neglect the correlation between timesteps, limiting the model's performance in generating images effectively. Notably, we theoretically point out that this issue can be caused by the cumulative estimation gap between the predicted and the actual trajectory. To minimize that gap, we propose a novel \textit{sequence-aware} loss that aims to reduce the estimation gap to enhance the sampling quality. Furthermore, we theoretically show that our proposed loss function is a tighter upper bound of the estimation loss in comparison with the conventional loss in DPMs. Experimental results on several benchmark datasets including CIFAR10, CelebA, and CelebA-HQ consistently show a remarkable improvement of our proposed method regarding the image generalization quality measured by FID and Inception Score compared to several DPM baselines. Our code and pre-trained checkpoints are available at \url{https://github.com/viettmab/SA-DPM}.
KOPPA: Improving Prompt-based Continual Learning with Key-Query Orthogonal Projection and Prototype-based One-Versus-All
Nov 30, 2023



Drawing inspiration from prompt tuning techniques applied to Large Language Models, recent methods based on pre-trained ViT networks have achieved remarkable results in the field of Continual Learning. Specifically, these approaches propose to maintain a set of prompts and allocate a subset of them to learn each task using a key-query matching strategy. However, they may encounter limitations when lacking control over the correlations between old task queries and keys of future tasks, the shift of features in the latent space, and the relative separation of latent vectors learned in independent tasks. In this work, we introduce a novel key-query learning strategy based on orthogonal projection, inspired by model-agnostic meta-learning, to enhance prompt matching efficiency and address the challenge of shifting features. Furthermore, we introduce a One-Versus-All (OVA) prototype-based component that enhances the classification head distinction. Experimental results on benchmark datasets demonstrate that our method empowers the model to achieve results surpassing those of current state-of-the-art approaches by a large margin of up to 20%.
Continual Learning with Optimal Transport based Mixture Model
Dec 05, 2022Online Class Incremental learning (CIL) is a challenging setting in Continual Learning (CL), wherein data of new tasks arrive in incoming streams and online learning models need to handle incoming data streams without revisiting previous ones. Existing works used a single centroid adapted with incoming data streams to characterize a class. This approach possibly exposes limitations when the incoming data stream of a class is naturally multimodal. To address this issue, in this work, we first propose an online mixture model learning approach based on nice properties of the mature optimal transport theory (OT-MM). Specifically, the centroids and covariance matrices of the mixture model are adapted incrementally according to incoming data streams. The advantages are two-fold: (i) we can characterize more accurately complex data streams and (ii) by using centroids for each class produced by OT-MM, we can estimate the similarity of an unseen example to each class more reasonably when doing inference. Moreover, to combat the catastrophic forgetting in the CIL scenario, we further propose Dynamic Preservation. Particularly, after performing the dynamic preservation technique across data streams, the latent representations of the classes in the old and new tasks become more condensed themselves and more separate from each other. Together with a contraction feature extractor, this technique facilitates the model in mitigating the catastrophic forgetting. The experimental results on real-world datasets show that our proposed method can significantly outperform the current state-of-the-art baselines.
Face Swapping as A Simple Arithmetic Operation
Nov 19, 2022



We propose a novel high-fidelity face swapping method called "Arithmetic Face Swapping" (AFS) that explicitly disentangles the intermediate latent space W+ of a pretrained StyleGAN into the "identity" and "style" subspaces so that a latent code in W+ is the sum of an "identity" code and a "style" code in the corresponding subspaces. Via our disentanglement, face swapping (FS) can be regarded as a simple arithmetic operation in W+, i.e., the summation of a source "identity" code and a target "style" code. This makes AFS more intuitive and elegant than other FS methods. In addition, our method can generalize over the standard face swapping to support other interesting operations, e.g., combining the identity of one source with styles of multiple targets and vice versa. We implement our identity-style disentanglement by learning a neural network that maps a latent code to a "style" code. We provide a condition for this network which theoretically guarantees identity preservation of the source face even after a sequence of face swapping operations. Extensive experiments demonstrate the advantage of our method over state-of-the-art FS methods in producing high-quality swapped faces.
From Implicit to Explicit feedback: A deep neural network for modeling sequential behaviours and long-short term preferences of online users
Jul 26, 2021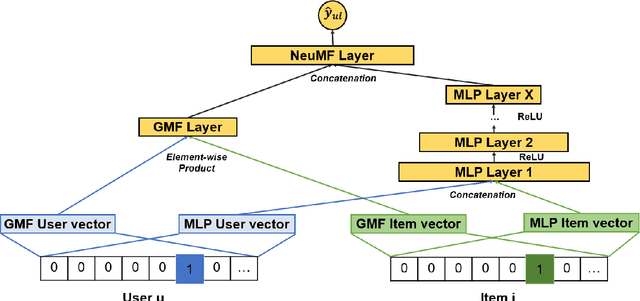
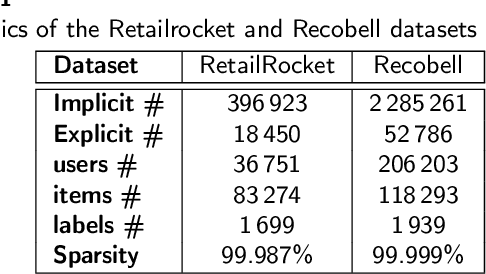
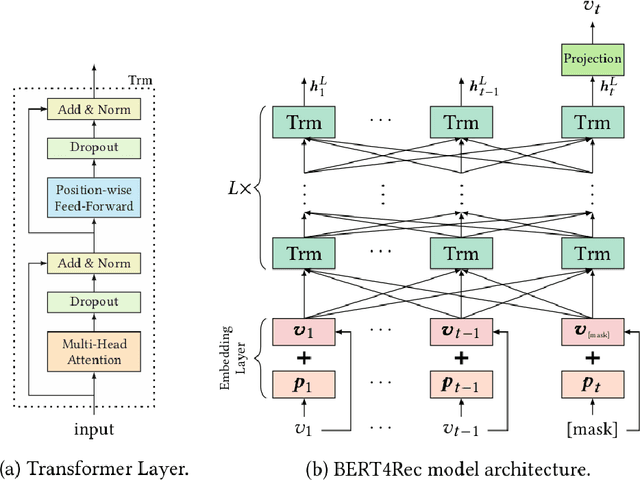
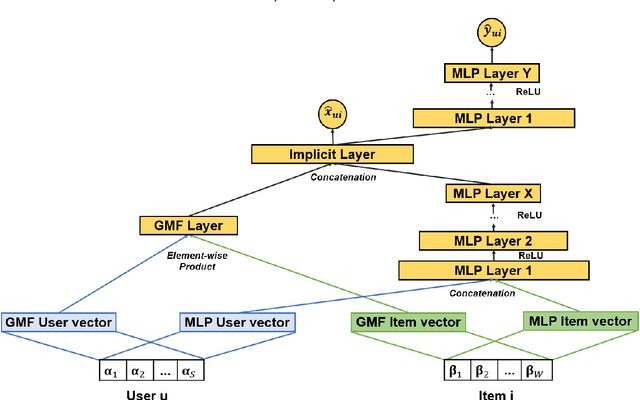
In this work, we examine the advantages of using multiple types of behaviour in recommendation systems. Intuitively, each user has to do some implicit actions (e.g., click) before making an explicit decision (e.g., purchase). Previous studies showed that implicit and explicit feedback have different roles for a useful recommendation. However, these studies either exploit implicit and explicit behaviour separately or ignore the semantic of sequential interactions between users and items. In addition, we go from the hypothesis that a user's preference at a time is a combination of long-term and short-term interests. In this paper, we propose some Deep Learning architectures. The first one is Implicit to Explicit (ITE), to exploit users' interests through the sequence of their actions. And two versions of ITE with Bidirectional Encoder Representations from Transformers based (BERT-based) architecture called BERT-ITE and BERT-ITE-Si, which combine users' long- and short-term preferences without and with side information to enhance user representation. The experimental results show that our models outperform previous state-of-the-art ones and also demonstrate our views on the effectiveness of exploiting the implicit to explicit order as well as combining long- and short-term preferences in two large-scale datasets.