 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing GPUs And LLMs Can Be Satisfying for Nonlinear Real Arithmetic Problems
Mar 08, 2026Solving quantifier-free non-linear real arithmetic (NRA) problems is a computationally hard task. To tackle this problem, prior work proposed a promising approach based on gradient descent. In this work, we extend their ideas and combine LLMs and GPU acceleration to obtain an efficient technique. We have implemented our findings in the novel SMT solver GANRA (GPU Accelerated solving of Nonlinear Real Arithmetic problems). We evaluate GANRA on two different NRA benchmarks and demonstrate significant improvements over the previous state of the art. In particular, on the Sturm-MBO benchmark, we can prove satisfiability for more than five times as many instances in less than 1/20th of the previous state-of-the-art runtime.
The 6th International Verification of Neural Networks Competition (VNN-COMP 2025): Summary and Results
Dec 22, 2025This report summarizes the 6th International Verification of Neural Networks Competition (VNN-COMP 2025), held as a part of the 8th International Symposium on AI Verification (SAIV), that was collocated with the 37th International Conference on Computer-Aided Verification (CAV). VNN-COMP is held annually to facilitate the fair and objective comparison of state-of-the-art neural network verification tools, encourage the standardization of tool interfaces, and bring together the neural network verification community. To this end, standardized formats for networks (ONNX) and specification (VNN-LIB) were defined, tools were evaluated on equal-cost hardware (using an automatic evaluation pipeline based on AWS instances), and tool parameters were chosen by the participants before the final test sets were made public. In the 2025 iteration, 8 teams participated on a diverse set of 16 regular and 9 extended benchmarks. This report summarizes the rules, benchmarks, participating tools, results, and lessons learned from this iteration of this competition.
Scalable Neural Network Verification with Branch-and-bound Inferred Cutting Planes
Dec 31, 2024Recently, cutting-plane methods such as GCP-CROWN have been explored to enhance neural network verifiers and made significant advances. However, GCP-CROWN currently relies on generic cutting planes (cuts) generated from external mixed integer programming (MIP) solvers. Due to the poor scalability of MIP solvers, large neural networks cannot benefit from these cutting planes. In this paper, we exploit the structure of the neural network verification problem to generate efficient and scalable cutting planes specific for this problem setting. We propose a novel approach, Branch-and-bound Inferred Cuts with COnstraint Strengthening (BICCOS), which leverages the logical relationships of neurons within verified subproblems in the branch-and-bound search tree, and we introduce cuts that preclude these relationships in other subproblems. We develop a mechanism that assigns influence scores to neurons in each path to allow the strengthening of these cuts. Furthermore, we design a multi-tree search technique to identify more cuts, effectively narrowing the search space and accelerating the BaB algorithm. Our results demonstrate that BICCOS can generate hundreds of useful cuts during the branch-and-bound process and consistently increase the number of verifiable instances compared to other state-of-the-art neural network verifiers on a wide range of benchmarks, including large networks that previous cutting plane methods could not scale to. BICCOS is part of the $\alpha,\beta$-CROWN verifier, the VNN-COMP 2024 winner. The code is available at http://github.com/Lemutisme/BICCOS .
The Fifth International Verification of Neural Networks Competition (VNN-COMP 2024): Summary and Results
Dec 28, 2024

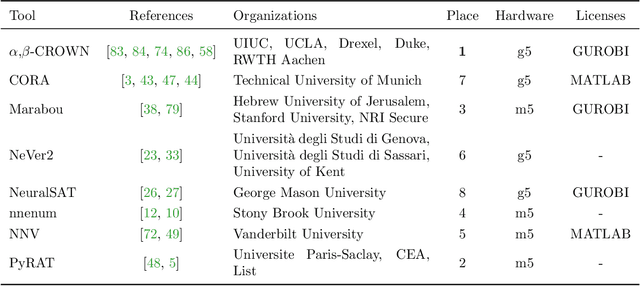

This report summarizes the 5th International Verification of Neural Networks Competition (VNN-COMP 2024), held as a part of the 7th International Symposium on AI Verification (SAIV), that was collocated with the 36th International Conference on Computer-Aided Verification (CAV). VNN-COMP is held annually to facilitate the fair and objective comparison of state-of-the-art neural network verification tools, encourage the standardization of tool interfaces, and bring together the neural network verification community. To this end, standardized formats for networks (ONNX) and specification (VNN-LIB) were defined, tools were evaluated on equal-cost hardware (using an automatic evaluation pipeline based on AWS instances), and tool parameters were chosen by the participants before the final test sets were made public. In the 2024 iteration, 8 teams participated on a diverse set of 12 regular and 8 extended benchmarks. This report summarizes the rules, benchmarks, participating tools, results, and lessons learned from this iteration of this competition.
The Fourth International Verification of Neural Networks Competition (VNN-COMP 2023): Summary and Results
Dec 28, 2023This report summarizes the 4th International Verification of Neural Networks Competition (VNN-COMP 2023), held as a part of the 6th Workshop on Formal Methods for ML-Enabled Autonomous Systems (FoMLAS), that was collocated with the 35th International Conference on Computer-Aided Verification (CAV). VNN-COMP is held annually to facilitate the fair and objective comparison of state-of-the-art neural network verification tools, encourage the standardization of tool interfaces, and bring together the neural network verification community. To this end, standardized formats for networks (ONNX) and specification (VNN-LIB) were defined, tools were evaluated on equal-cost hardware (using an automatic evaluation pipeline based on AWS instances), and tool parameters were chosen by the participants before the final test sets were made public. In the 2023 iteration, 7 teams participated on a diverse set of 10 scored and 4 unscored benchmarks. This report summarizes the rules, benchmarks, participating tools, results, and lessons learned from this iteration of this competition.
Provably Bounding Neural Network Preimages
Feb 07, 2023Most work on the formal verification of neural networks has focused on bounding forward images of neural networks, i.e., the set of outputs of a neural network that correspond to a given set of inputs (for example, bounded perturbations of a nominal input). However, many use cases of neural network verification require solving the inverse problem, i.e, over-approximating the set of inputs that lead to certain outputs. In this work, we present the first efficient bound propagation algorithm, INVPROP, for verifying properties over the preimage of a linearly constrained output set of a neural network, which can be combined with branch-and-bound to achieve completeness. Our efficient algorithm allows multiple passes of intermediate bound refinements, which are crucial for tight inverse verification because the bounds of an intermediate layer depend on relaxations both before and after this layer. We demonstrate our algorithm on applications related to quantifying safe control regions for a dynamical system and detecting out-of-distribution inputs to a neural network. Our results show that in certain settings, we can find over-approximations that are over 2500 times tighter than prior work while being 2.5 times faster on the same hardware.
First Three Years of the International Verification of Neural Networks Competition (VNN-COMP)
Jan 14, 2023This paper presents a summary and meta-analysis of the first three iterations of the annual International Verification of Neural Networks Competition (VNN-COMP) held in 2020, 2021, and 2022. In the VNN-COMP, participants submit software tools that analyze whether given neural networks satisfy specifications describing their input-output behavior. These neural networks and specifications cover a variety of problem classes and tasks, corresponding to safety and robustness properties in image classification, neural control, reinforcement learning, and autonomous systems. We summarize the key processes, rules, and results, present trends observed over the last three years, and provide an outlook into possible future developments.
The Third International Verification of Neural Networks Competition (VNN-COMP 2022): Summary and Results
Dec 20, 2022
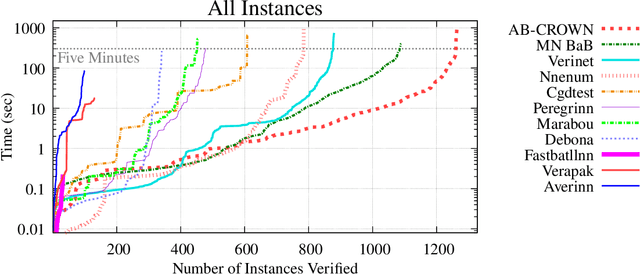
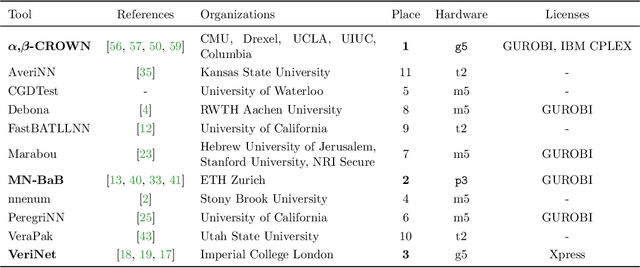
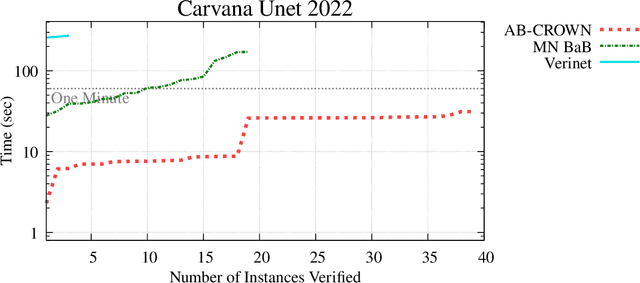
This report summarizes the 3rd International Verification of Neural Networks Competition (VNN-COMP 2022), held as a part of the 5th Workshop on Formal Methods for ML-Enabled Autonomous Systems (FoMLAS), which was collocated with the 34th International Conference on Computer-Aided Verification (CAV). VNN-COMP is held annually to facilitate the fair and objective comparison of state-of-the-art neural network verification tools, encourage the standardization of tool interfaces, and bring together the neural network verification community. To this end, standardized formats for networks (ONNX) and specification (VNN-LIB) were defined, tools were evaluated on equal-cost hardware (using an automatic evaluation pipeline based on AWS instances), and tool parameters were chosen by the participants before the final test sets were made public. In the 2022 iteration, 11 teams participated on a diverse set of 12 scored benchmarks. This report summarizes the rules, benchmarks, participating tools, results, and lessons learned from this iteration of this competition.
Two-Way Neural Machine Translation: A Proof of Concept for Bidirectional Translation Modeling using a Two-Dimensional Grid
Nov 24, 2020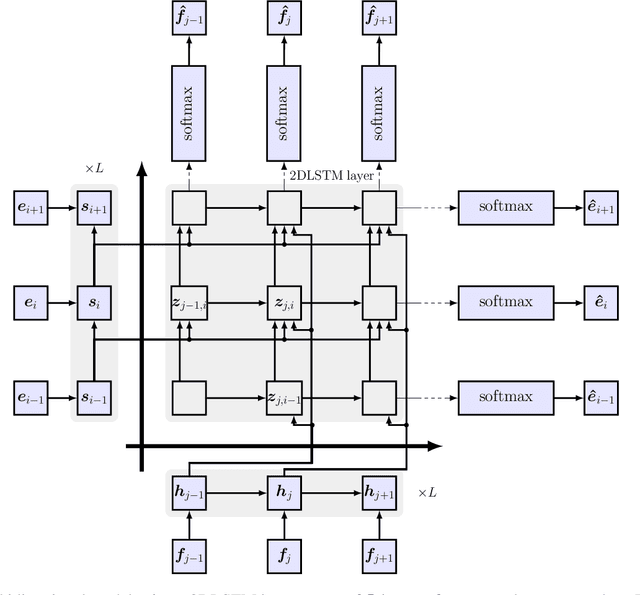
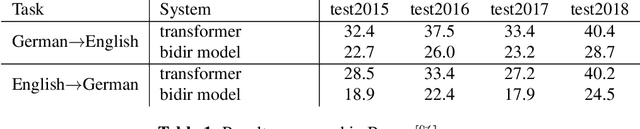
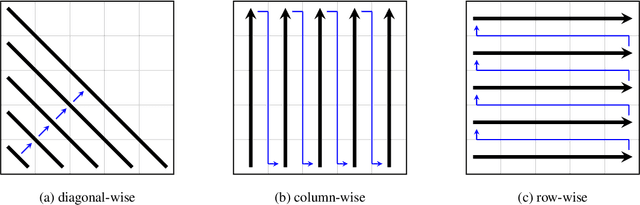
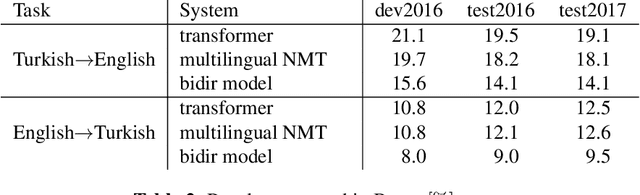
Neural translation models have proven to be effective in capturing sufficient information from a source sentence and generating a high-quality target sentence. However, it is not easy to get the best effect for bidirectional translation, i.e., both source-to-target and target-to-source translation using a single model. If we exclude some pioneering attempts, such as multilingual systems, all other bidirectional translation approaches are required to train two individual models. This paper proposes to build a single end-to-end bidirectional translation model using a two-dimensional grid, where the left-to-right decoding generates source-to-target, and the bottom-to-up decoding creates target-to-source output. Instead of training two models independently, our approach encourages a single network to jointly learn to translate in both directions. Experiments on the WMT 2018 German$\leftrightarrow$English and Turkish$\leftrightarrow$English translation tasks show that the proposed model is capable of generating a good translation quality and has sufficient potential to direct the research.
Debona: Decoupled Boundary Network Analysis for Tighter Bounds and Faster Adversarial Robustness Proofs
Jun 16, 2020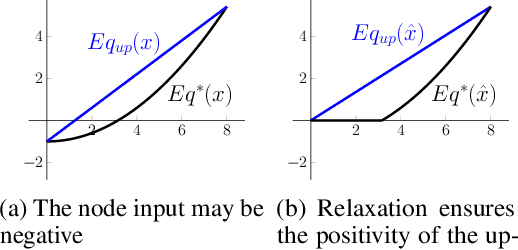
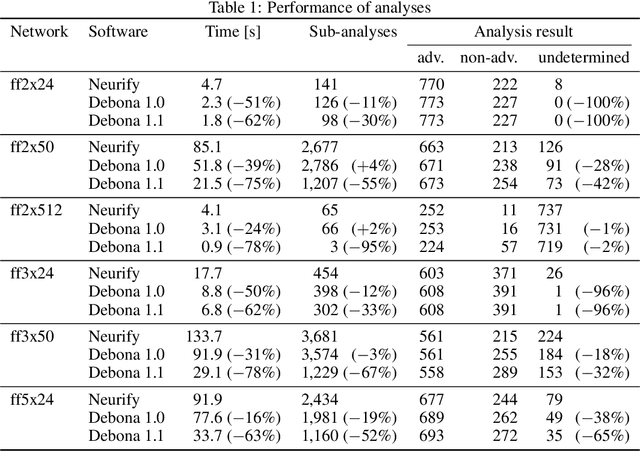
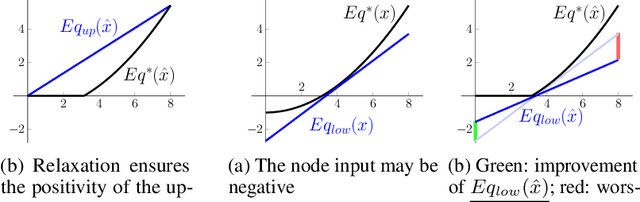
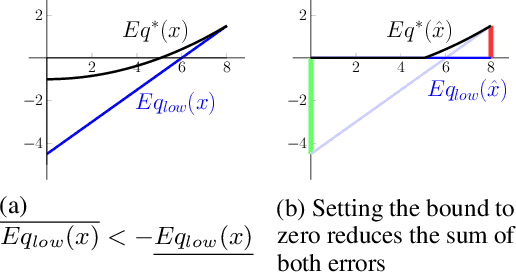
Neural networks are commonly used in safety-critical real-world applications. Unfortunately, the predicted output is often highly sensitive to small, and possibly imperceptible, changes to the input data. Proving that either no such adversarial examples exist, or providing a concrete instance, is therefore crucial to ensure safe applications. As enumerating and testing all potential adversarial examples is computationally infeasible, verification techniques have been developed to provide mathematically sound proofs of their absence using overestimations of the network activations. We propose an improved technique for computing tight upper and lower bounds of these node values, based on increased flexibility gained by computing both bounds independently of each other. Furthermore, we gain an additional improvement by re-implementing part of the original state-of-the-art software "Neurify", leading to a faster analysis. Combined, these adaptations reduce the necessary runtime by up to 78%, and allow a successful search for networks and inputs that were previously too complex. Finally, we provide proofs for tight upper and lower bounds on max-pooling layers in convolutional networks. To ensure widespread usability, we open source our implementation "Debona", featuring both the implementation specific enhancements as well as the refined boundary computation for faster and more exact results.