 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake the Hint: Improving Arabic Diacritization with Partially-Diacritized Text
Jun 06, 2023


Automatic Arabic diacritization is useful in many applications, ranging from reading support for language learners to accurate pronunciation predictor for downstream tasks like speech synthesis. While most of the previous works focused on models that operate on raw non-diacritized text, production systems can gain accuracy by first letting humans partly annotate ambiguous words. In this paper, we propose 2SDiac, a multi-source model that can effectively support optional diacritics in input to inform all predictions. We also introduce Guided Learning, a training scheme to leverage given diacritics in input with different levels of random masking. We show that the provided hints during test affect more output positions than those annotated. Moreover, experiments on two common benchmarks show that our approach i) greatly outperforms the baseline also when evaluated on non-diacritized text; and ii) achieves state-of-the-art results while reducing the parameter count by over 60%.
Tight Integrated End-to-End Training for Cascaded Speech Translation
Nov 24, 2020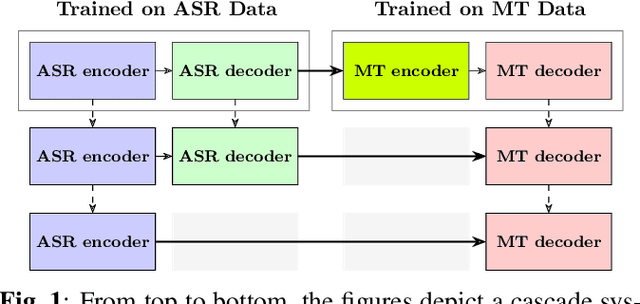
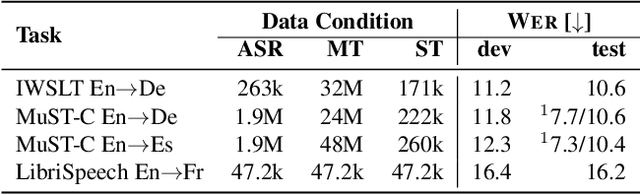
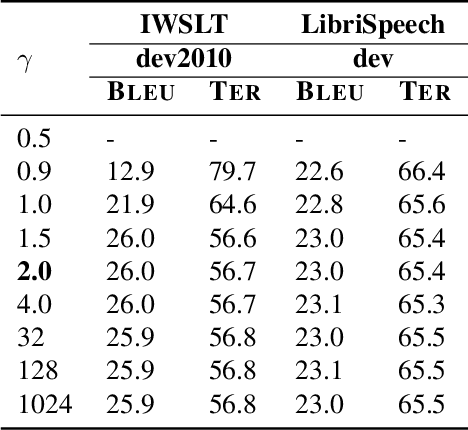
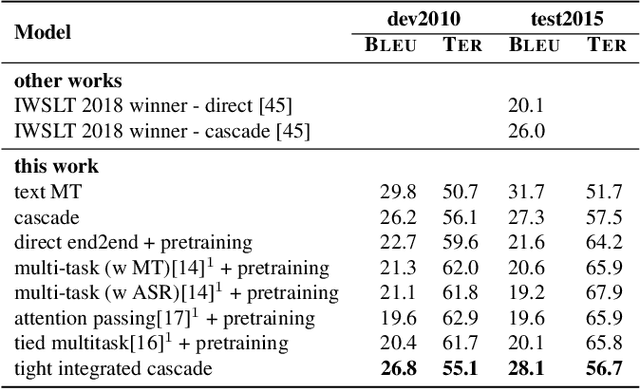
A cascaded speech translation model relies on discrete and non-differentiable transcription, which provides a supervision signal from the source side and helps the transformation between source speech and target text. Such modeling suffers from error propagation between ASR and MT models. Direct speech translation is an alternative method to avoid error propagation; however, its performance is often behind the cascade system. To use an intermediate representation and preserve the end-to-end trainability, previous studies have proposed using two-stage models by passing the hidden vectors of the recognizer into the decoder of the MT model and ignoring the MT encoder. This work explores the feasibility of collapsing the entire cascade components into a single end-to-end trainable model by optimizing all parameters of ASR and MT models jointly without ignoring any learned parameters. It is a tightly integrated method that passes renormalized source word posterior distributions as a soft decision instead of one-hot vectors and enables backpropagation. Therefore, it provides both transcriptions and translations and achieves strong consistency between them. Our experiments on four tasks with different data scenarios show that the model outperforms cascade models up to 1.8% in BLEU and 2.0% in TER and is superior compared to direct models.
Two-Way Neural Machine Translation: A Proof of Concept for Bidirectional Translation Modeling using a Two-Dimensional Grid
Nov 24, 2020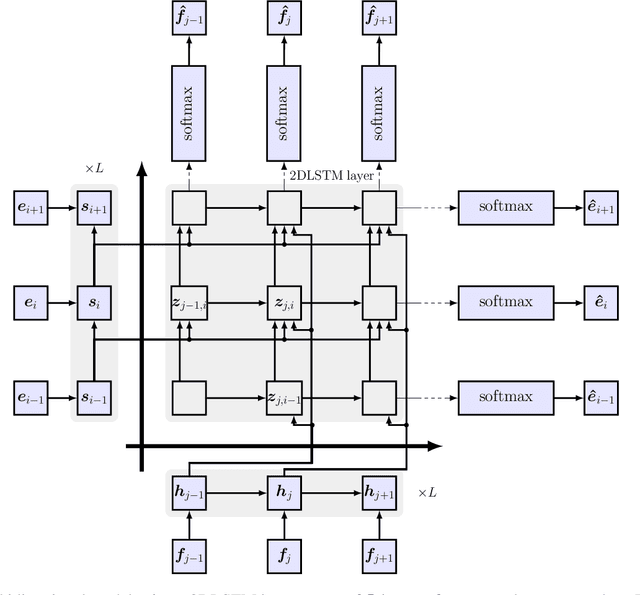
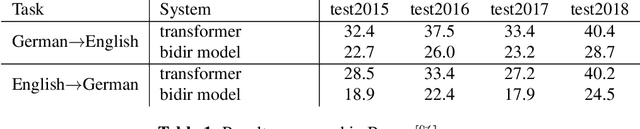
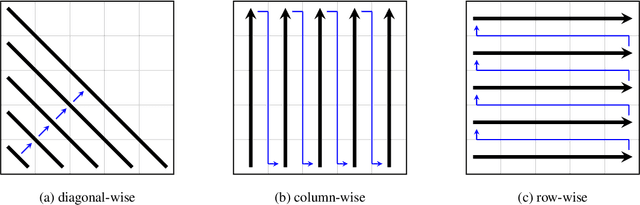
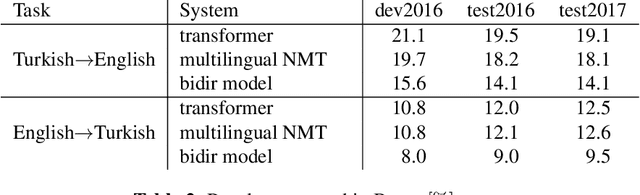
Neural translation models have proven to be effective in capturing sufficient information from a source sentence and generating a high-quality target sentence. However, it is not easy to get the best effect for bidirectional translation, i.e., both source-to-target and target-to-source translation using a single model. If we exclude some pioneering attempts, such as multilingual systems, all other bidirectional translation approaches are required to train two individual models. This paper proposes to build a single end-to-end bidirectional translation model using a two-dimensional grid, where the left-to-right decoding generates source-to-target, and the bottom-to-up decoding creates target-to-source output. Instead of training two models independently, our approach encourages a single network to jointly learn to translate in both directions. Experiments on the WMT 2018 German$\leftrightarrow$English and Turkish$\leftrightarrow$English translation tasks show that the proposed model is capable of generating a good translation quality and has sufficient potential to direct the research.
Successfully Applying the Stabilized Lottery Ticket Hypothesis to the Transformer Architecture
May 04, 2020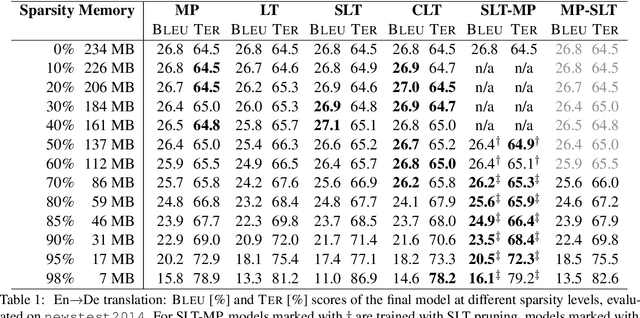
Sparse models require less memory for storage and enable a faster inference by reducing the necessary number of FLOPs. This is relevant both for time-critical and on-device computations using neural networks. The stabilized lottery ticket hypothesis states that networks can be pruned after none or few training iterations, using a mask computed based on the unpruned converged model. On the transformer architecture and the WMT 2014 English-to-German and English-to-French tasks, we show that stabilized lottery ticket pruning performs similar to magnitude pruning for sparsity levels of up to 85%, and propose a new combination of pruning techniques that outperforms all other techniques for even higher levels of sparsity. Furthermore, we confirm that the parameter's initial sign and not its specific value is the primary factor for successful training, and show that magnitude pruning cannot be used to find winning lottery tickets.
On using 2D sequence-to-sequence models for speech recognition
Nov 20, 2019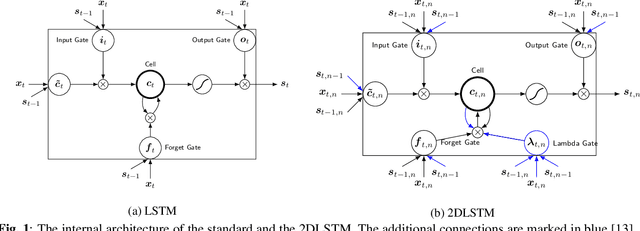

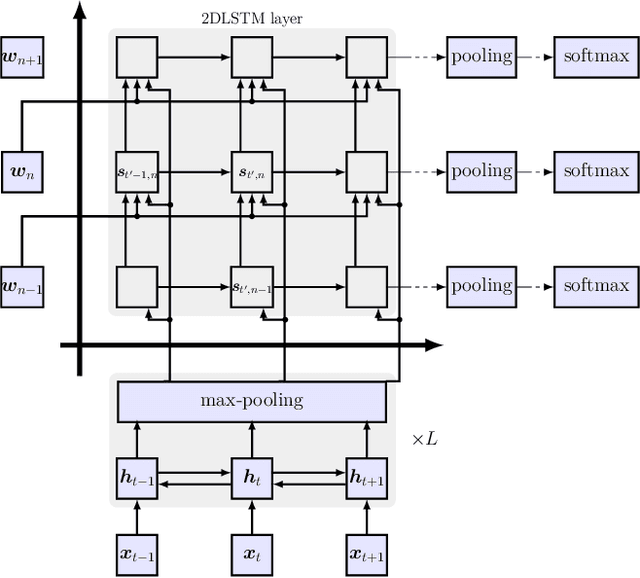

Attention-based sequence-to-sequence models have shown promising results in automatic speech recognition. Using these architectures, one-dimensional input and output sequences are related by an attention approach, thereby replacing more explicit alignment processes, like in classical HMM-based modeling. In contrast, here we apply a novel two-dimensional long short-term memory (2DLSTM) architecture to directly model the input/output relation between audio/feature vector sequences and word sequences. The proposed model is an alternative model such that instead of using any type of attention components, we apply a 2DLSTM layer to assimilate the context from both input observations and output transcriptions. The experimental evaluation on the Switchboard 300h automatic speech recognition task shows word error rates for the 2DLSTM model that are competitive to end-to-end attention-based model.
On Using SpecAugment for End-to-End Speech Translation
Nov 20, 2019

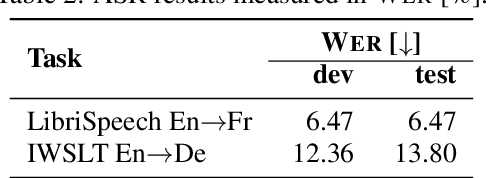
This work investigates a simple data augmentation technique, SpecAugment, for end-to-end speech translation. SpecAugment is a low-cost implementation method applied directly to the audio input features and it consists of masking blocks of frequency channels, and/or time steps. We apply SpecAugment on end-to-end speech translation tasks and achieve up to +2.2\% \BLEU on LibriSpeech Audiobooks En->Fr and +1.2% on IWSLT TED-talks En->De by alleviating overfitting to some extent. We also examine the effectiveness of the method in a variety of data scenarios and show that the method also leads to significant improvements in various data conditions irrespective of the amount of training data.
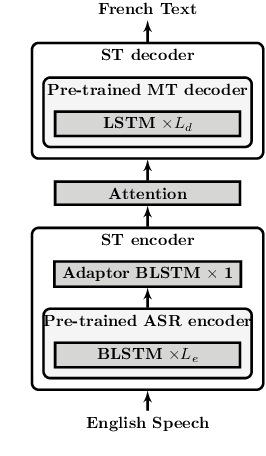
A Comparative Study on End-to-end Speech to Text Translation
Nov 20, 2019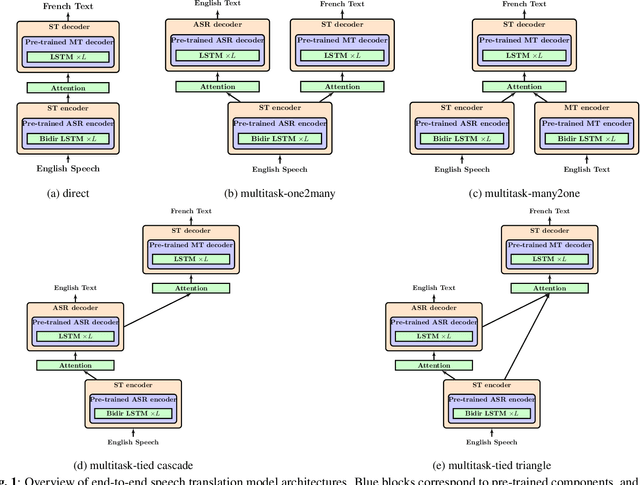
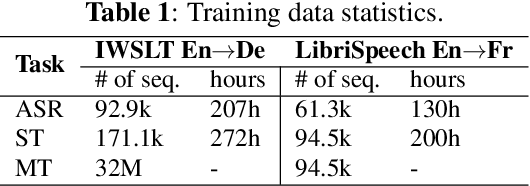
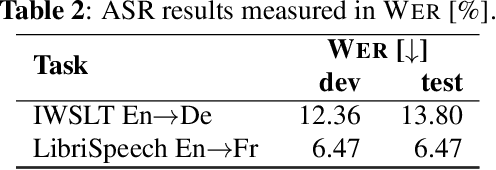
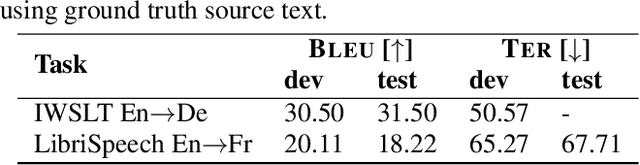
Recent advances in deep learning show that end-to-end speech to text translation model is a promising approach to direct the speech translation field. In this work, we provide an overview of different end-to-end architectures, as well as the usage of an auxiliary connectionist temporal classification (CTC) loss for better convergence. We also investigate on pre-training variants such as initializing different components of a model using pre-trained models, and their impact on the final performance, which gives boosts up to 4% in BLEU and 5% in TER. Our experiments are performed on 270h IWSLT TED-talks En->De, and 100h LibriSpeech Audiobooks En->Fr. We also show improvements over the current end-to-end state-of-the-art systems on both tasks.
Towards Two-Dimensional Sequence to Sequence Model in Neural Machine Translation
Oct 09, 2018

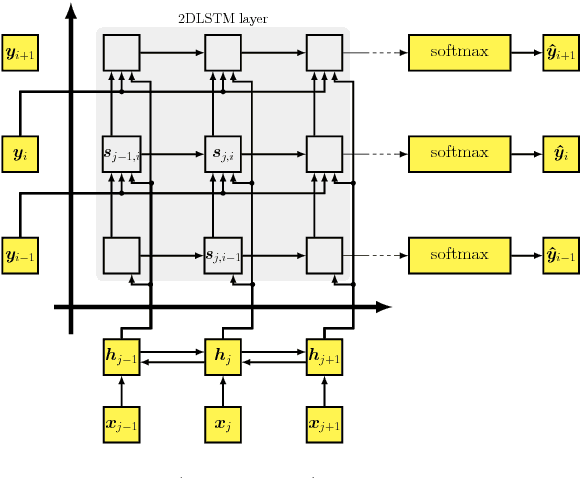

This work investigates an alternative model for neural machine translation (NMT) and proposes a novel architecture, where we employ a multi-dimensional long short-term memory (MDLSTM) for translation modeling. In the state-of-the-art methods, source and target sentences are treated as one-dimensional sequences over time, while we view translation as a two-dimensional (2D) mapping using an MDLSTM layer to define the correspondence between source and target words. We extend beyond the current sequence to sequence backbone NMT models to a 2D structure in which the source and target sentences are aligned with each other in a 2D grid. Our proposed topology shows consistent improvements over attention-based sequence to sequence model on two WMT 2017 tasks, German$\leftrightarrow$English.