 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight Integrated End-to-End Training for Cascaded Speech Translation
Nov 24, 2020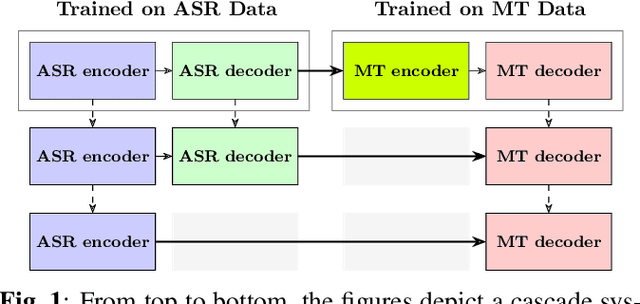
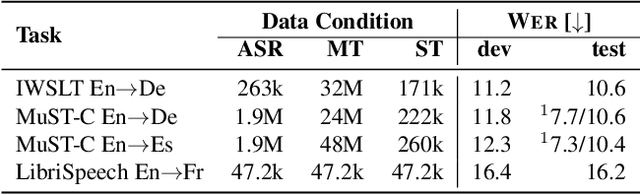
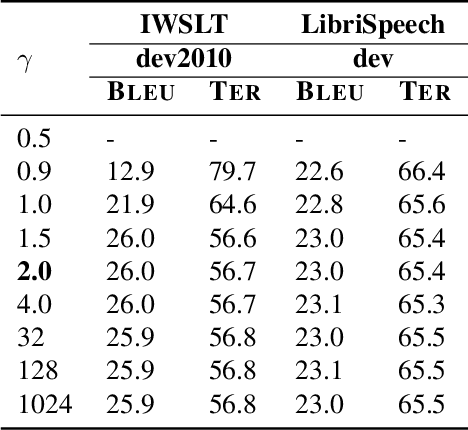
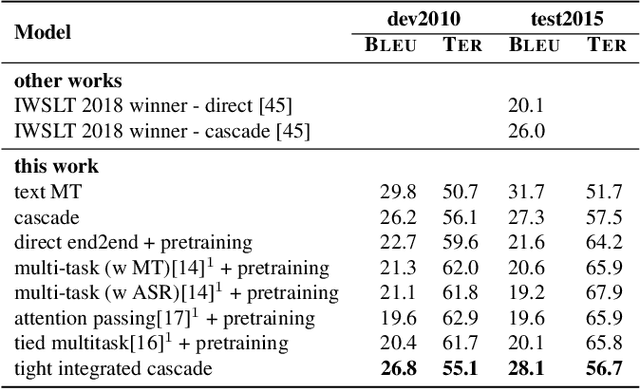
A cascaded speech translation model relies on discrete and non-differentiable transcription, which provides a supervision signal from the source side and helps the transformation between source speech and target text. Such modeling suffers from error propagation between ASR and MT models. Direct speech translation is an alternative method to avoid error propagation; however, its performance is often behind the cascade system. To use an intermediate representation and preserve the end-to-end trainability, previous studies have proposed using two-stage models by passing the hidden vectors of the recognizer into the decoder of the MT model and ignoring the MT encoder. This work explores the feasibility of collapsing the entire cascade components into a single end-to-end trainable model by optimizing all parameters of ASR and MT models jointly without ignoring any learned parameters. It is a tightly integrated method that passes renormalized source word posterior distributions as a soft decision instead of one-hot vectors and enables backpropagation. Therefore, it provides both transcriptions and translations and achieves strong consistency between them. Our experiments on four tasks with different data scenarios show that the model outperforms cascade models up to 1.8% in BLEU and 2.0% in TER and is superior compared to direct models.
A Comparative Study on End-to-end Speech to Text Translation
Nov 20, 2019
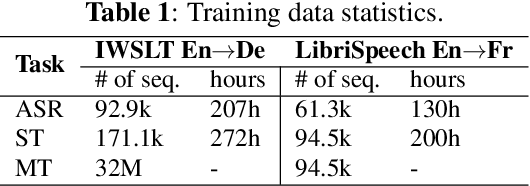
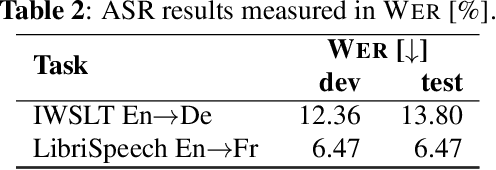
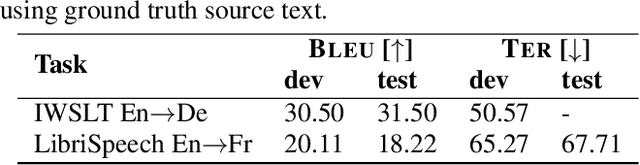
Recent advances in deep learning show that end-to-end speech to text translation model is a promising approach to direct the speech translation field. In this work, we provide an overview of different end-to-end architectures, as well as the usage of an auxiliary connectionist temporal classification (CTC) loss for better convergence. We also investigate on pre-training variants such as initializing different components of a model using pre-trained models, and their impact on the final performance, which gives boosts up to 4% in BLEU and 5% in TER. Our experiments are performed on 270h IWSLT TED-talks En->De, and 100h LibriSpeech Audiobooks En->Fr. We also show improvements over the current end-to-end state-of-the-art systems on both tasks.