 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn using 2D sequence-to-sequence models for speech recognition
Paper and Code
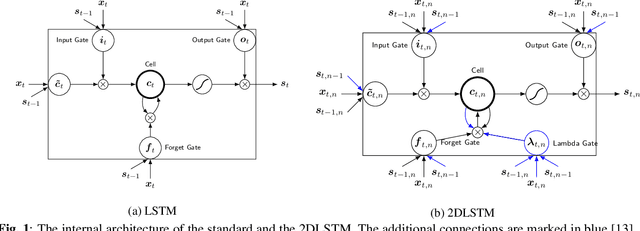

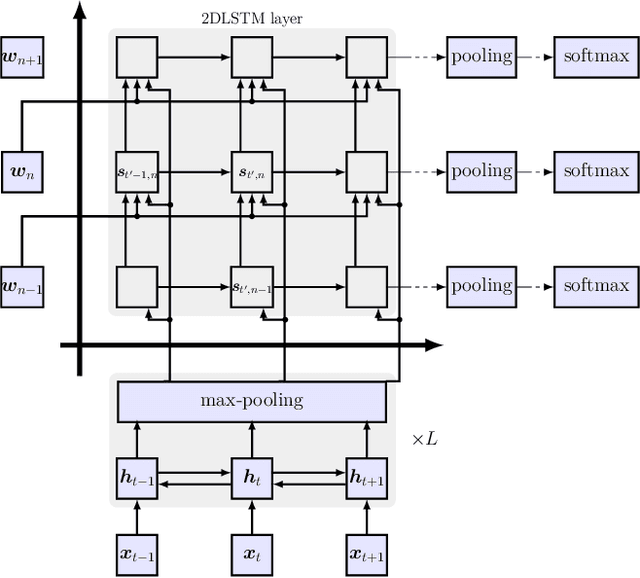

Attention-based sequence-to-sequence models have shown promising results in automatic speech recognition. Using these architectures, one-dimensional input and output sequences are related by an attention approach, thereby replacing more explicit alignment processes, like in classical HMM-based modeling. In contrast, here we apply a novel two-dimensional long short-term memory (2DLSTM) architecture to directly model the input/output relation between audio/feature vector sequences and word sequences. The proposed model is an alternative model such that instead of using any type of attention components, we apply a 2DLSTM layer to assimilate the context from both input observations and output transcriptions. The experimental evaluation on the Switchboard 300h automatic speech recognition task shows word error rates for the 2DLSTM model that are competitive to end-to-end attention-based model.