 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Visible Watermark Removal with Morphological Dilation
Feb 04, 2025

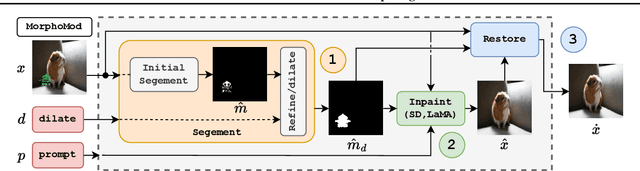

Visible watermarks pose significant challenges for image restoration techniques, especially when the target background is unknown. Toward this end, we present MorphoMod, a novel method for automated visible watermark removal that operates in a blind setting -- without requiring target images. Unlike existing methods, MorphoMod effectively removes opaque and transparent watermarks while preserving semantic content, making it well-suited for real-world applications. Evaluations on benchmark datasets, including the Colored Large-scale Watermark Dataset (CLWD), LOGO-series, and the newly introduced Alpha1 datasets, demonstrate that MorphoMod achieves up to a 50.8% improvement in watermark removal effectiveness compared to state-of-the-art methods. Ablation studies highlight the impact of prompts used for inpainting, pre-removal filling strategies, and inpainting model performance on watermark removal. Additionally, a case study on steganographic disorientation reveals broader applications for watermark removal in disrupting high-level hidden messages. MorphoMod offers a robust, adaptable solution for watermark removal and opens avenues for further advancements in image restoration and adversarial manipulation.
SUDS: Sanitizing Universal and Dependent Steganography
Sep 23, 2023



Steganography, or hiding messages in plain sight, is a form of information hiding that is most commonly used for covert communication. As modern steganographic mediums include images, text, audio, and video, this communication method is being increasingly used by bad actors to propagate malware, exfiltrate data, and discreetly communicate. Current protection mechanisms rely upon steganalysis, or the detection of steganography, but these approaches are dependent upon prior knowledge, such as steganographic signatures from publicly available tools and statistical knowledge about known hiding methods. These dependencies render steganalysis useless against new or unique hiding methods, which are becoming increasingly common with the application of deep learning models. To mitigate the shortcomings of steganalysis, this work focuses on a deep learning sanitization technique called SUDS that is not reliant upon knowledge of steganographic hiding techniques and is able to sanitize universal and dependent steganography. SUDS is tested using least significant bit method (LSB), dependent deep hiding (DDH), and universal deep hiding (UDH). We demonstrate the capabilities and limitations of SUDS by answering five research questions, including baseline comparisons and an ablation study. Additionally, we apply SUDS to a real-world scenario, where it is able to increase the resistance of a poisoned classifier against attacks by 1375%.