 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA solvable high-dimensional model where nonlinear autoencoders learn structure invisible to PCA while test loss misaligns with generalization
Feb 11, 2026Many real-world datasets contain hidden structure that cannot be detected by simple linear correlations between input features. For example, latent factors may influence the data in a coordinated way, even though their effect is invisible to covariance-based methods such as PCA. In practice, nonlinear neural networks often succeed in extracting such hidden structure in unsupervised and self-supervised learning. However, constructing a minimal high-dimensional model where this advantage can be rigorously analyzed has remained an open theoretical challenge. We introduce a tractable high-dimensional spiked model with two latent factors: one visible to covariance, and one statistically dependent yet uncorrelated, appearing only in higher-order moments. PCA and linear autoencoders fail to recover the latter, while a minimal nonlinear autoencoder provably extracts both. We analyze both the population risk, and empirical risk minimization. Our model also provides a tractable example where self-supervised test loss is poorly aligned with representation quality: nonlinear autoencoders recover latent structure that linear methods miss, even though their reconstruction loss is higher.
The Nuclear Route: Sharp Asymptotics of ERM in Overparameterized Quadratic Networks
May 23, 2025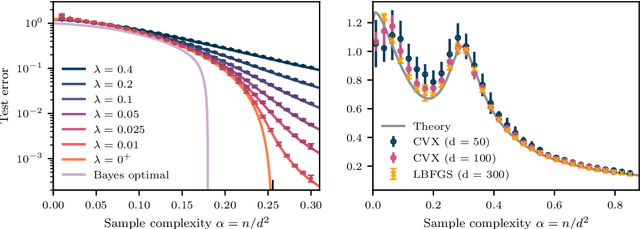


We study the high-dimensional asymptotics of empirical risk minimization (ERM) in over-parametrized two-layer neural networks with quadratic activations trained on synthetic data. We derive sharp asymptotics for both training and test errors by mapping the $\ell_2$-regularized learning problem to a convex matrix sensing task with nuclear norm penalization. This reveals that capacity control in such networks emerges from a low-rank structure in the learned feature maps. Our results characterize the global minima of the loss and yield precise generalization thresholds, showing how the width of the target function governs learnability. This analysis bridges and extends ideas from spin-glass methods, matrix factorization, and convex optimization and emphasizes the deep link between low-rank matrix sensing and learning in quadratic neural networks.
Bilinear Sequence Regression: A Model for Learning from Long Sequences of High-dimensional Tokens
Oct 24, 2024Current progress in artificial intelligence is centered around so-called large language models that consist of neural networks processing long sequences of high-dimensional vectors called tokens. Statistical physics provides powerful tools to study the functioning of learning with neural networks and has played a recognized role in the development of modern machine learning. The statistical physics approach relies on simplified and analytically tractable models of data. However, simple tractable models for long sequences of high-dimensional tokens are largely underexplored. Inspired by the crucial role models such as the single-layer teacher-student perceptron (aka generalized linear regression) played in the theory of fully connected neural networks, in this paper, we introduce and study the bilinear sequence regression (BSR) as one of the most basic models for sequences of tokens. We note that modern architectures naturally subsume the BSR model due to the skip connections. Building on recent methodological progress, we compute the Bayes-optimal generalization error for the model in the limit of long sequences of high-dimensional tokens, and provide a message-passing algorithm that matches this performance. We quantify the improvement that optimal learning brings with respect to vectorizing the sequence of tokens and learning via simple linear regression. We also unveil surprising properties of the gradient descent algorithms in the BSR model.
Les Houches Lectures on Deep Learning at Large & Infinite Width
Sep 08, 2023These lectures, presented at the 2022 Les Houches Summer School on Statistical Physics and Machine Learning, focus on the infinite-width limit and large-width regime of deep neural networks. Topics covered include various statistical and dynamical properties of these networks. In particular, the lecturers discuss properties of random deep neural networks; connections between trained deep neural networks, linear models, kernels, and Gaussian processes that arise in the infinite-width limit; and perturbative and non-perturbative treatments of large but finite-width networks, at initialization and after training.
Asymptotic Characterisation of Robust Empirical Risk Minimisation Performance in the Presence of Outliers
May 30, 2023


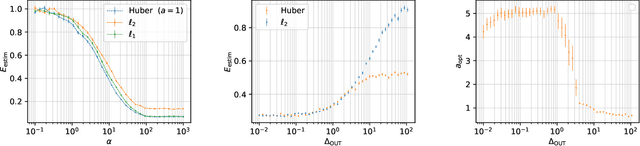
We study robust linear regression in high-dimension, when both the dimension $d$ and the number of data points $n$ diverge with a fixed ratio $\alpha=n/d$, and study a data model that includes outliers. We provide exact asymptotics for the performances of the empirical risk minimisation (ERM) using $\ell_2$-regularised $\ell_2$, $\ell_1$, and Huber loss, which are the standard approach to such problems. We focus on two metrics for the performance: the generalisation error to similar datasets with outliers, and the estimation error of the original, unpolluted function. Our results are compared with the information theoretic Bayes-optimal estimation bound. For the generalization error, we find that optimally-regularised ERM is asymptotically consistent in the large sample complexity limit if one perform a simple calibration, and compute the rates of convergence. For the estimation error however, we show that due to a norm calibration mismatch, the consistency of the estimator requires an oracle estimate of the optimal norm, or the presence of a cross-validation set not corrupted by the outliers. We examine in detail how performance depends on the loss function and on the degree of outlier corruption in the training set and identify a region of parameters where the optimal performance of the Huber loss is identical to that of the $\ell_2$ loss, offering insights into the use cases of different loss functions.
Intrinsic dimension estimation for locally undersampled data
Jun 18, 2019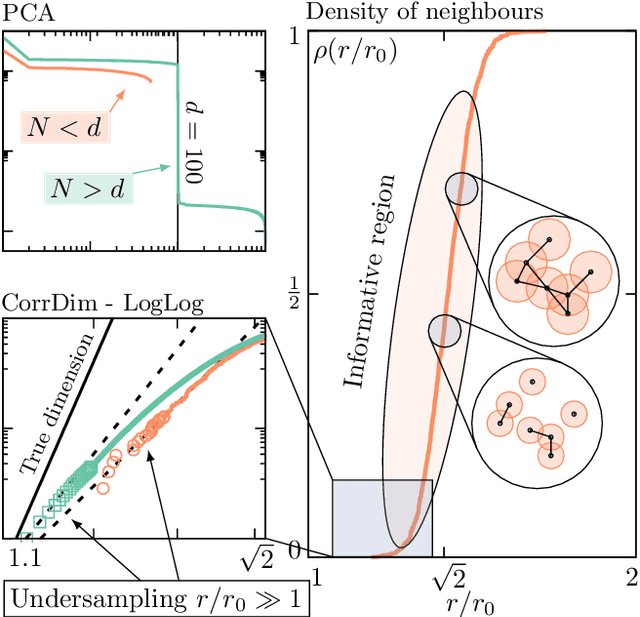
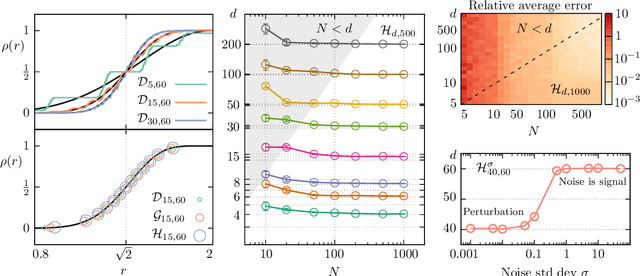
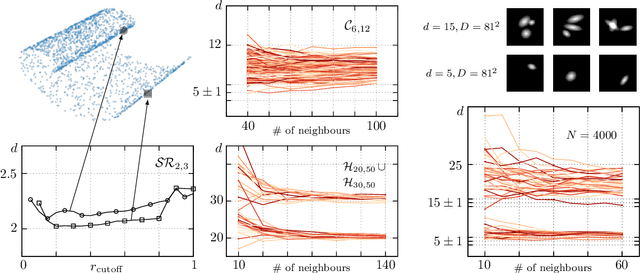
High-dimensional data are ubiquitous in contemporary science and finding methods to compress them is one of the primary goals of machine learning. Given a dataset lying in a high-dimensional space (in principle hundreds to several thousands of dimensions), it is often useful to project it onto a lower-dimensional manifold, without loss of information. Identifying the minimal dimension of such manifold is a challenging problem known in the literature as intrinsic dimension estimation (IDE). Traditionally, most IDE algorithms are either based on multiscale principal component analysis (PCA) or on the notion of correlation dimension (and more in general on k-nearest-neighbors distances). These methods are affected, in different ways, by a severe curse of dimensionality. In particular, none of the existing algorithms can provide accurate ID estimates in the extreme locally undersampled regime, i.e. in the limit where the number of samples in any local patch of the manifold is less than (or of the same order of) the ID of the dataset. Here we introduce a new ID estimator that leverages on simple properties of the tangent space of a manifold to overcome these shortcomings. The method is based on the full correlation integral, going beyond the limit of small radius used for the estimation of the correlation dimension. Our estimator alleviates the extreme undersampling problem, intractable with other methods. Based on this insight, we explore a multiscale generalization of the algorithm. We show that it is capable of (i) identifying multiple dimensionalities in a dataset, and (ii) providing accurate estimates of the ID of extremely curved manifolds. In particular, we test the method on manifolds generated from global transformations of high-contrast images, relevant for invariant object recognition and considered a challenge for state-of-the-art ID estimators.