 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorisation, convergence and generalisation in generative models
May 20, 2026Generative neural networks learn how to produce highly realistic images from a large, but finite number of examples - or do they simply memorise their training set? To settle this question, Kadkhodaie, Guth, Simoncelli and Mallat (ICLR '24) trained diffusion models independently on disjoint subsets of a dataset and showed that they converge to nearly the same density when the number of training images is large enough. This result raises two basic questions: how much data do you need for convergence, and what does convergence capture about learning the data distribution? Here, we address these questions by providing an exact analytical characterisation of the transition from memorisation to generalisation in linear generative models. We find that these models memorise at small load, while convergence emerges continuously when the number of samples is linear in the input dimension. Strikingly, we find that convergence is insensitive to recovery of the principal latent factors of the data, which are recovered in a sharp transition. After extending our approach to data with power-law spectra, we find the same distinction between convergence and latent recovery in our experiments with convolutional denoisers and in the data of Kadkhodaie et al. We thus show that generalisation in generative models decomposes into at least two distinct objectives: matching the bulk of the data distribution and recovering the principal latent factors. These objectives correspond to two different distances between true and learnt data distribution, and only the first one is captured by convergence.
Factual recall in linear associative memories: sharp asymptotics and mechanistic insights
May 11, 2026Large language models demonstrate remarkable ability in factual recall, yet the fundamental limits of storing and retrieving input--output associations with neural networks remain unclear. We study these limits in a minimal setting: a linear associative memory that maps $p$ input embeddings in $\mathbb{R}^d$ to their corresponding~$d$-dimensional targets via a single layer, requiring each mapped input to be well separated from all other targets. Unlike in supervised classification, this strict separation induces~$p$ constraints per association and produces strong correlations between constraints that make a direct characterisation of the storage capacity difficult. Here, we provide a precise characterisation of this capacity in the following way. We first introduce a decoupled model in which each input has its own independent set of competing outputs, and provide numerical and analytical evidence that this decoupled model is equivalent to the original model in terms of storage capacity, spectra of the learnt weights, and storage mechanism. Using tools from statistical physics, we show that the decoupled model can store up to $p_c \log p_c / d^2 = 1 / 2$ associations, and generalise the computation of $p_c$ to linear two-layer architectures. Our analysis also gives mechanistic insight into how the optimal solution improves over a naïve Hebbian learning rule: rather than boosting input-output alignments with broad fluctuations, the optimal solution raises the correct scores just above the extreme-value threshold set by the competing outputs. These findings give a sharp statistical-physics characterisation of factual storage in linear networks and provide a baseline for understanding the memory capacity of more realistic neural architectures.
A Noise Sensitivity Exponent Controls Large Statistical-to-Computational Gaps in Single- and Multi-Index Models
Mar 18, 2026Understanding when learning is statistically possible yet computationally hard is a central challenge in high-dimensional statistics. In this work, we investigate this question in the context of single- and multi-index models, classes of functions widely studied as benchmarks to probe the ability of machine learning methods to discover features in high-dimensional data. Our main contribution is to show that a Noise Sensitivity Exponent (NSE) - a simple quantity determined by the activation function - governs the existence and magnitude of statistical-to-computational gaps within a broad regime of these models. We first establish that, in single-index models with large additive noise, the onset of a computational bottleneck is fully characterized by the NSE. We then demonstrate that the same exponent controls a statistical-computational gap in the specialization transition of large separable multi-index models, where individual components become learnable. Finally, in hierarchical multi-index models, we show that the NSE governs the optimal computational rate in which different directions are sequentially learned. Taken together, our results identify the NSE as a unifying property linking noise robustness, computational hardness, and feature specialization in high-dimensional learning.
Optimal scaling laws in learning hierarchical multi-index models
Feb 05, 2026In this work, we provide a sharp theory of scaling laws for two-layer neural networks trained on a class of hierarchical multi-index targets, in a genuinely representation-limited regime. We derive exact information-theoretic scaling laws for subspace recovery and prediction error, revealing how the hierarchical features of the target are sequentially learned through a cascade of phase transitions. We further show that these optimal rates are achieved by a simple, target-agnostic spectral estimator, which can be interpreted as the small learning-rate limit of gradient descent on the first-layer weights. Once an adapted representation is identified, the readout can be learned statistically optimally, using an efficient procedure. As a consequence, we provide a unified and rigorous explanation of scaling laws, plateau phenomena, and spectral structure in shallow neural networks trained on such hierarchical targets.
Fundamental Limits of Matrix Sensing: Exact Asymptotics, Universality, and Applications
Mar 18, 2025In the matrix sensing problem, one wishes to reconstruct a matrix from (possibly noisy) observations of its linear projections along given directions. We consider this model in the high-dimensional limit: while previous works on this model primarily focused on the recovery of low-rank matrices, we consider in this work more general classes of structured signal matrices with potentially large rank, e.g. a product of two matrices of sizes proportional to the dimension. We provide rigorous asymptotic equations characterizing the Bayes-optimal learning performance from a number of samples which is proportional to the number of entries in the matrix. Our proof is composed of three key ingredients: $(i)$ we prove universality properties to handle structured sensing matrices, related to the ''Gaussian equivalence'' phenomenon in statistical learning, $(ii)$ we provide a sharp characterization of Bayes-optimal learning in generalized linear models with Gaussian data and structured matrix priors, generalizing previously studied settings, and $(iii)$ we leverage previous works on the problem of matrix denoising. The generality of our results allow for a variety of applications: notably, we mathematically establish predictions obtained via non-rigorous methods from statistical physics in [ETB+24] regarding Bilinear Sequence Regression, a benchmark model for learning from sequences of tokens, and in [MTM+24] on Bayes-optimal learning in neural networks with quadratic activation function, and width proportional to the dimension.
Bilinear Sequence Regression: A Model for Learning from Long Sequences of High-dimensional Tokens
Oct 24, 2024Current progress in artificial intelligence is centered around so-called large language models that consist of neural networks processing long sequences of high-dimensional vectors called tokens. Statistical physics provides powerful tools to study the functioning of learning with neural networks and has played a recognized role in the development of modern machine learning. The statistical physics approach relies on simplified and analytically tractable models of data. However, simple tractable models for long sequences of high-dimensional tokens are largely underexplored. Inspired by the crucial role models such as the single-layer teacher-student perceptron (aka generalized linear regression) played in the theory of fully connected neural networks, in this paper, we introduce and study the bilinear sequence regression (BSR) as one of the most basic models for sequences of tokens. We note that modern architectures naturally subsume the BSR model due to the skip connections. Building on recent methodological progress, we compute the Bayes-optimal generalization error for the model in the limit of long sequences of high-dimensional tokens, and provide a message-passing algorithm that matches this performance. We quantify the improvement that optimal learning brings with respect to vectorizing the sequence of tokens and learning via simple linear regression. We also unveil surprising properties of the gradient descent algorithms in the BSR model.
Bayes-optimal learning of an extensive-width neural network from quadratically many samples
Aug 07, 2024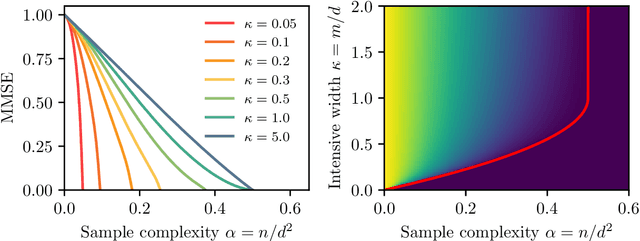
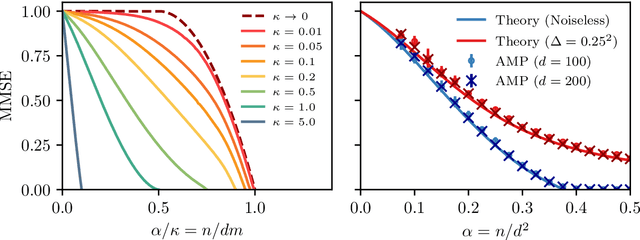
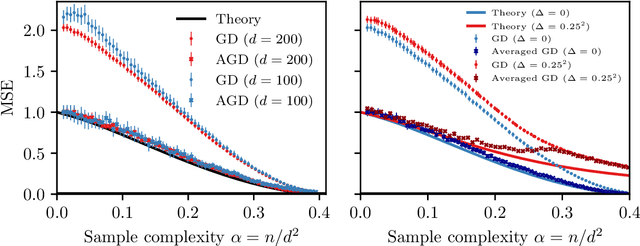
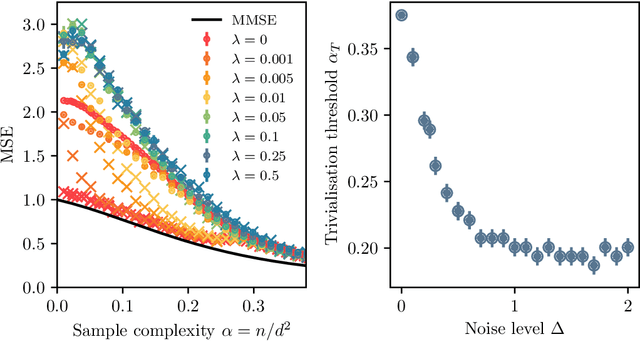
We consider the problem of learning a target function corresponding to a single hidden layer neural network, with a quadratic activation function after the first layer, and random weights. We consider the asymptotic limit where the input dimension and the network width are proportionally large. Recent work [Cui & al '23] established that linear regression provides Bayes-optimal test error to learn such a function when the number of available samples is only linear in the dimension. That work stressed the open challenge of theoretically analyzing the optimal test error in the more interesting regime where the number of samples is quadratic in the dimension. In this paper, we solve this challenge for quadratic activations and derive a closed-form expression for the Bayes-optimal test error. We also provide an algorithm, that we call GAMP-RIE, which combines approximate message passing with rotationally invariant matrix denoising, and that asymptotically achieves the optimal performance. Technically, our result is enabled by establishing a link with recent works on optimal denoising of extensive-rank matrices and on the ellipsoid fitting problem. We further show empirically that, in the absence of noise, randomly-initialized gradient descent seems to sample the space of weights, leading to zero training loss, and averaging over initialization leads to a test error equal to the Bayes-optimal one.
Fitting an ellipsoid to a quadratic number of random points
Jul 03, 2023We consider the problem $(\mathrm{P})$ of fitting $n$ standard Gaussian random vectors in $\mathbb{R}^d$ to the boundary of a centered ellipsoid, as $n, d \to \infty$. This problem is conjectured to have a sharp feasibility transition: for any $\varepsilon > 0$, if $n \leq (1 - \varepsilon) d^2 / 4$ then $(\mathrm{P})$ has a solution with high probability, while $(\mathrm{P})$ has no solutions with high probability if $n \geq (1 + \varepsilon) d^2 /4$. So far, only a trivial bound $n \geq d^2 / 2$ is known on the negative side, while the best results on the positive side assume $n \leq d^2 / \mathrm{polylog}(d)$. In this work, we improve over previous approaches using a key result of Bartl & Mendelson on the concentration of Gram matrices of random vectors under mild assumptions on their tail behavior. This allows us to give a simple proof that $(\mathrm{P})$ is feasible with high probability when $n \leq d^2 / C$, for a (possibly large) constant $C > 0$.
Injectivity of ReLU networks: perspectives from statistical physics
Feb 27, 2023When can the input of a ReLU neural network be inferred from its output? In other words, when is the network injective? We consider a single layer, $x \mapsto \mathrm{ReLU}(Wx)$, with a random Gaussian $m \times n$ matrix $W$, in a high-dimensional setting where $n, m \to \infty$. Recent work connects this problem to spherical integral geometry giving rise to a conjectured sharp injectivity threshold for $\alpha = \frac{m}{n}$ by studying the expected Euler characteristic of a certain random set. We adopt a different perspective and show that injectivity is equivalent to a property of the ground state of the spherical perceptron, an important spin glass model in statistical physics. By leveraging the (non-rigorous) replica symmetry-breaking theory, we derive analytical equations for the threshold whose solution is at odds with that from the Euler characteristic. Furthermore, we use Gordon's min--max theorem to prove that a replica-symmetric upper bound refutes the Euler characteristic prediction. Along the way we aim to give a tutorial-style introduction to key ideas from statistical physics in an effort to make the exposition accessible to a broad audience. Our analysis establishes a connection between spin glasses and integral geometry but leaves open the problem of explaining the discrepancies.
On free energy barriers in Gaussian priors and failure of MCMC for high-dimensional unimodal distributions
Sep 05, 2022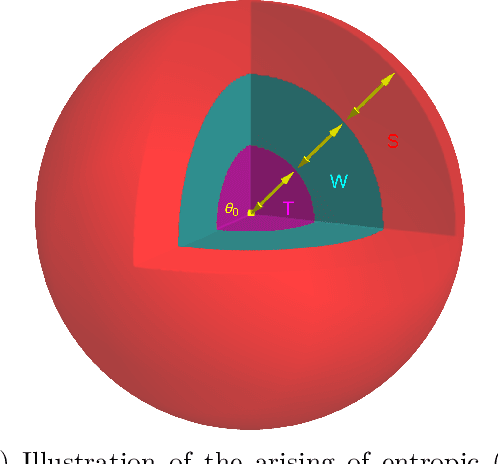
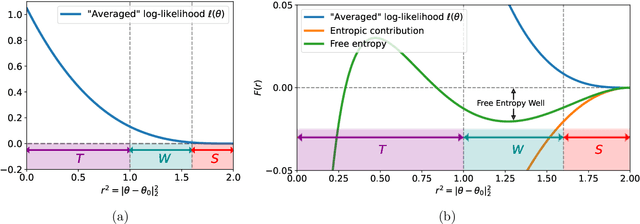
We exhibit examples of high-dimensional unimodal posterior distributions arising in non-linear regression models with Gaussian process priors for which worst-case (`cold start') initialised MCMC methods typically take an exponential run-time to enter the regions where the bulk of the posterior measure concentrates. The counter-examples hold for general MCMC schemes based on gradient or random walk steps, and the theory is illustrated for Metropolis-Hastings adjusted methods such as pCN and MALA.