 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution learning via neural differential equations: a nonparametric statistical perspective
Sep 03, 2023Ordinary differential equations (ODEs), via their induced flow maps, provide a powerful framework to parameterize invertible transformations for the purpose of representing complex probability distributions. While such models have achieved enormous success in machine learning, particularly for generative modeling and density estimation, little is known about their statistical properties. This work establishes the first general nonparametric statistical convergence analysis for distribution learning via ODE models trained through likelihood maximization. We first prove a convergence theorem applicable to arbitrary velocity field classes $\mathcal{F}$ satisfying certain simple boundary constraints. This general result captures the trade-off between approximation error (`bias') and the complexity of the ODE model (`variance'). We show that the latter can be quantified via the $C^1$-metric entropy of the class $\mathcal F$. We then apply this general framework to the setting of $C^k$-smooth target densities, and establish nearly minimax-optimal convergence rates for two relevant velocity field classes $\mathcal F$: $C^k$ functions and neural networks. The latter is the practically important case of neural ODEs. Our proof techniques require a careful synthesis of (i) analytical stability results for ODEs, (ii) classical theory for sieved M-estimators, and (iii) recent results on approximation rates and metric entropies of neural network classes. The results also provide theoretical insight on how the choice of velocity field class, and the dependence of this choice on sample size $n$ (e.g., the scaling of width, depth, and sparsity of neural network classes), impacts statistical performance.
Infinite-Dimensional Diffusion Models for Function Spaces
Feb 20, 2023



We define diffusion-based generative models in infinite dimensions, and apply them to the generative modeling of functions. By first formulating such models in the infinite-dimensional limit and only then discretizing, we are able to obtain a sampling algorithm that has \emph{dimension-free} bounds on the distance from the sample measure to the target measure. Furthermore, we propose a new way to perform conditional sampling in an infinite-dimensional space and show that our approach outperforms previously suggested procedures.
On free energy barriers in Gaussian priors and failure of MCMC for high-dimensional unimodal distributions
Sep 05, 2022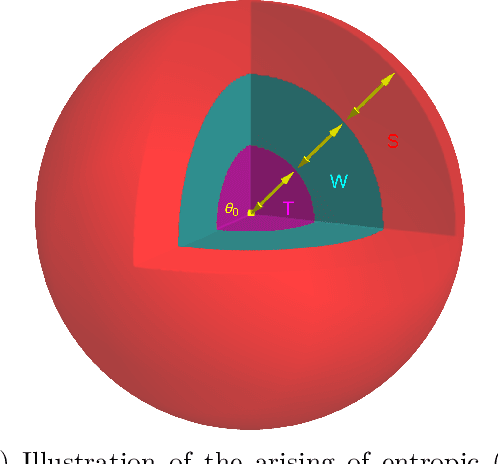
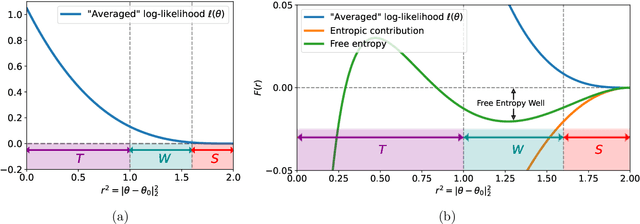
We exhibit examples of high-dimensional unimodal posterior distributions arising in non-linear regression models with Gaussian process priors for which worst-case (`cold start') initialised MCMC methods typically take an exponential run-time to enter the regions where the bulk of the posterior measure concentrates. The counter-examples hold for general MCMC schemes based on gradient or random walk steps, and the theory is illustrated for Metropolis-Hastings adjusted methods such as pCN and MALA.
On minimax density estimation via measure transport
Jul 20, 2022We study the convergence properties, in Hellinger and related distances, of nonparametric density estimators based on measure transport. These estimators represent the measure of interest as the pushforward of a chosen reference distribution under a transport map, where the map is chosen via a maximum likelihood objective (equivalently, minimizing an empirical Kullback-Leibler loss) or a penalized version thereof. We establish concentration inequalities for a general class of penalized measure transport estimators, by combining techniques from M-estimation with analytical properties of the transport-based density representation. We then demonstrate the implications of our theory for the case of triangular Knothe-Rosenblatt (KR) transports on the $d$-dimensional unit cube, and show that both penalized and unpenalized versions of such estimators achieve minimax optimal convergence rates over H\"older classes of densities. Specifically, we establish optimal rates for unpenalized nonparametric maximum likelihood estimation over bounded H\"older-type balls, and then for certain Sobolev-penalized estimators and sieved wavelet estimators.