 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFitting an ellipsoid to a quadratic number of random points
Jul 03, 2023We consider the problem $(\mathrm{P})$ of fitting $n$ standard Gaussian random vectors in $\mathbb{R}^d$ to the boundary of a centered ellipsoid, as $n, d \to \infty$. This problem is conjectured to have a sharp feasibility transition: for any $\varepsilon > 0$, if $n \leq (1 - \varepsilon) d^2 / 4$ then $(\mathrm{P})$ has a solution with high probability, while $(\mathrm{P})$ has no solutions with high probability if $n \geq (1 + \varepsilon) d^2 /4$. So far, only a trivial bound $n \geq d^2 / 2$ is known on the negative side, while the best results on the positive side assume $n \leq d^2 / \mathrm{polylog}(d)$. In this work, we improve over previous approaches using a key result of Bartl & Mendelson on the concentration of Gram matrices of random vectors under mild assumptions on their tail behavior. This allows us to give a simple proof that $(\mathrm{P})$ is feasible with high probability when $n \leq d^2 / C$, for a (possibly large) constant $C > 0$.
Injectivity of ReLU networks: perspectives from statistical physics
Feb 27, 2023When can the input of a ReLU neural network be inferred from its output? In other words, when is the network injective? We consider a single layer, $x \mapsto \mathrm{ReLU}(Wx)$, with a random Gaussian $m \times n$ matrix $W$, in a high-dimensional setting where $n, m \to \infty$. Recent work connects this problem to spherical integral geometry giving rise to a conjectured sharp injectivity threshold for $\alpha = \frac{m}{n}$ by studying the expected Euler characteristic of a certain random set. We adopt a different perspective and show that injectivity is equivalent to a property of the ground state of the spherical perceptron, an important spin glass model in statistical physics. By leveraging the (non-rigorous) replica symmetry-breaking theory, we derive analytical equations for the threshold whose solution is at odds with that from the Euler characteristic. Furthermore, we use Gordon's min--max theorem to prove that a replica-symmetric upper bound refutes the Euler characteristic prediction. Along the way we aim to give a tutorial-style introduction to key ideas from statistical physics in an effort to make the exposition accessible to a broad audience. Our analysis establishes a connection between spin glasses and integral geometry but leaves open the problem of explaining the discrepancies.
On free energy barriers in Gaussian priors and failure of MCMC for high-dimensional unimodal distributions
Sep 05, 2022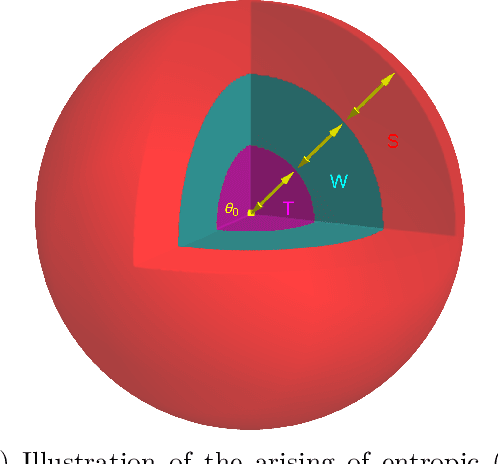
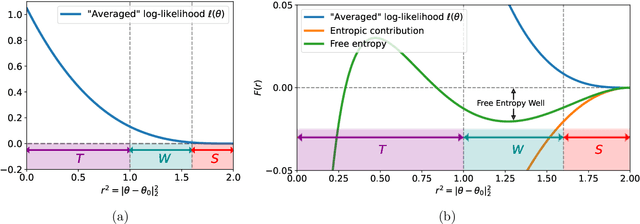
We exhibit examples of high-dimensional unimodal posterior distributions arising in non-linear regression models with Gaussian process priors for which worst-case (`cold start') initialised MCMC methods typically take an exponential run-time to enter the regions where the bulk of the posterior measure concentrates. The counter-examples hold for general MCMC schemes based on gradient or random walk steps, and the theory is illustrated for Metropolis-Hastings adjusted methods such as pCN and MALA.
The Franz-Parisi Criterion and Computational Trade-offs in High Dimensional Statistics
May 19, 2022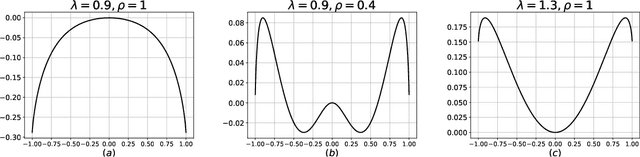
Many high-dimensional statistical inference problems are believed to possess inherent computational hardness. Various frameworks have been proposed to give rigorous evidence for such hardness, including lower bounds against restricted models of computation (such as low-degree functions), as well as methods rooted in statistical physics that are based on free energy landscapes. This paper aims to make a rigorous connection between the seemingly different low-degree and free-energy based approaches. We define a free-energy based criterion for hardness and formally connect it to the well-established notion of low-degree hardness for a broad class of statistical problems, namely all Gaussian additive models and certain models with a sparse planted signal. By leveraging these rigorous connections we are able to: establish that for Gaussian additive models the "algebraic" notion of low-degree hardness implies failure of "geometric" local MCMC algorithms, and provide new low-degree lower bounds for sparse linear regression which seem difficult to prove directly. These results provide both conceptual insights into the connections between different notions of hardness, as well as concrete technical tools such as new methods for proving low-degree lower bounds.
Community Detection with a Subsampled Semidefinite Program
Feb 03, 2021Semidefinite programming is an important tool to tackle several problems in data science and signal processing, including clustering and community detection. However, semidefinite programs are often slow in practice, so speed up techniques such as sketching are often considered. In the context of community detection in the stochastic block model, Mixon and Xie [9] have recently proposed a sketching framework in which a semidefinite program is solved only on a subsampled subgraph of the network, giving rise to significant computational savings. In this short paper, we provide a positive answer to a conjecture of Mixon and Xie about the statistical limits of this technique for the stochastic block model with two balanced communities.
The Average-Case Time Complexity of Certifying the Restricted Isometry Property
Jun 13, 2020In compressed sensing, the restricted isometry property (RIP) on $M \times N$ sensing matrices (where $M < N$) guarantees efficient reconstruction of sparse vectors. A matrix has the $(s,\delta)$-$\mathsf{RIP}$ property if behaves as a $\delta$-approximate isometry on $s$-sparse vectors. It is well known that an $M\times N$ matrix with i.i.d. $\mathcal{N}(0,1/M)$ entries is $(s,\delta)$-$\mathsf{RIP}$ with high probability as long as $s\lesssim \delta^2 M/\log N$. On the other hand, most prior works aiming to deterministically construct $(s,\delta)$-$\mathsf{RIP}$ matrices have failed when $s \gg \sqrt{M}$. An alternative way to find an RIP matrix could be to draw a random gaussian matrix and certify that it is indeed RIP. However, there is evidence that this certification task is computationally hard when $s \gg \sqrt{M}$, both in the worst case and the average case. In this paper, we investigate the exact average-case time complexity of certifying the RIP property for $M\times N$ matrices with i.i.d. $\mathcal{N}(0,1/M)$ entries, in the "possible but hard" regime $\sqrt{M} \ll s\lesssim M/\log N$, assuming that $M$ scales proportional to $N$. Based on analysis of the low-degree likelihood ratio, we give rigorous evidence that subexponential runtime $N^{\tilde\Omega(s^2/N)}$ is required, demonstrating a smooth tradeoff between the maximum tolerated sparsity and the required computational power. The lower bound is essentially tight, matching the runtime of an existing algorithm due to Koiran and Zouzias. Our hardness result allows $\delta$ to take any constant value in $(0,1)$, which captures the relevant regime for compressed sensing. This improves upon the existing average-case hardness result of Wang, Berthet, and Plan, which is limited to $\delta = o(1)$.
Computationally efficient sparse clustering
May 25, 2020We study statistical and computational limits of clustering when the means of the centres are sparse and their dimension is possibly much larger than the sample size. Our theoretical analysis focuses on the simple model $X_i = z_i \theta + \varepsilon_i$, $z_i \in \{-1,1\}$, $\varepsilon_i \thicksim \mathcal{N}(0, I)$, which has two clusters with centres $\theta$ and $-\theta$. We provide a finite sample analysis of a new sparse clustering algorithm based on sparse PCA and show that it achieves the minimax optimal misclustering rate in the regime $\|\theta\| \rightarrow \infty$, matching asymptotically the Bayes error. Our results require the sparsity to grow slower than the square root of the sample size. Using a recent framework for computational lower bounds---the low-degree likelihood ratio---we give evidence that this condition is necessary for any polynomial-time clustering algorithm to succeed below the BBP threshold. This complements existing evidence based on reductions and statistical query lower bounds. Compared to these existing results, we cover a wider set of parameter regimes and give a more precise understanding of the runtime required and the misclustering error achievable. We also discuss extensions of our results to more than two clusters.
Experimental performance of graph neural networks on random instances of max-cut
Aug 15, 2019
This note explores the applicability of unsupervised machine learning techniques towards hard optimization problems on random inputs. In particular we consider Graph Neural Networks (GNNs) -- a class of neural networks designed to learn functions on graphs -- and we apply them to the max-cut problem on random regular graphs. We focus on the max-cut problem on random regular graphs because it is a fundamental problem that has been widely studied. In particular, even though there is no known explicit solution to compare the output of our algorithm to, we can leverage the known asymptotics of the optimal max-cut value in order to evaluate the performance of the GNNs. In order to put the performance of the GNNs in context, we compare it with the classical semidefinite relaxation approach by Goemans and Williamson~(SDP), and with extremal optimization, which is a local optimization heuristic from the statistical physics literature. The numerical results we obtain indicate that, surprisingly, Graph Neural Networks attain comparable performance to the Goemans and Williamson SDP. We also observe that extremal optimization consistently outperforms the other two methods. Furthermore, the performances of the three methods present similar patterns, that is, for sparser, and for larger graphs, the size of the found cuts are closer to the asymptotic optimal max-cut value.
Notes on Computational Hardness of Hypothesis Testing: Predictions using the Low-Degree Likelihood Ratio
Jul 26, 2019These notes survey and explore an emerging method, which we call the low-degree method, for predicting and understanding statistical-versus-computational tradeoffs in high-dimensional inference problems. In short, the method posits that a certain quantity -- the second moment of the low-degree likelihood ratio -- gives insight into how much computational time is required to solve a given hypothesis testing problem, which can in turn be used to predict the computational hardness of a variety of statistical inference tasks. While this method originated in the study of the sum-of-squares (SoS) hierarchy of convex programs, we present a self-contained introduction that does not require knowledge of SoS. In addition to showing how to carry out predictions using the method, we include a discussion investigating both rigorous and conjectural consequences of these predictions. These notes include some new results, simplified proofs, and refined conjectures. For instance, we point out a formal connection between spectral methods and the low-degree likelihood ratio, and we give a sharp low-degree lower bound against subexponential-time algorithms for tensor PCA.
Subexponential-Time Algorithms for Sparse PCA
Jul 26, 2019We study the computational cost of recovering a unit-norm sparse principal component $x \in \mathbb{R}^n$ planted in a random matrix, in either the Wigner or Wishart spiked model (observing either $W + \lambda xx^\top$ with $W$ drawn from the Gaussian orthogonal ensemble, or $N$ independent samples from $\mathcal{N}(0, I_n + \beta xx^\top)$, respectively). Prior work has shown that when the signal-to-noise ratio ($\lambda$ or $\beta\sqrt{N/n}$, respectively) is a small constant and the fraction of nonzero entries in the planted vector is $\|x\|_0 / n = \rho$, it is possible to recover $x$ in polynomial time if $\rho \lesssim 1/\sqrt{n}$. While it is possible to recover $x$ in exponential time under the weaker condition $\rho \ll 1$, it is believed that polynomial-time recovery is impossible unless $\rho \lesssim 1/\sqrt{n}$. We investigate the precise amount of time required for recovery in the "possible but hard" regime $1/\sqrt{n} \ll \rho \ll 1$ by exploring the power of subexponential-time algorithms, i.e., algorithms running in time $\exp(n^\delta)$ for some constant $\delta \in (0,1)$. For any $1/\sqrt{n} \ll \rho \ll 1$, we give a recovery algorithm with runtime roughly $\exp(\rho^2 n)$, demonstrating a smooth tradeoff between sparsity and runtime. Our family of algorithms interpolates smoothly between two existing algorithms: the polynomial-time diagonal thresholding algorithm and the $\exp(\rho n)$-time exhaustive search algorithm. Furthermore, by analyzing the low-degree likelihood ratio, we give rigorous evidence suggesting that the tradeoff achieved by our algorithms is optimal.