 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasy, robust approximate message passing for planted spike models
May 30, 2026We present a simple and efficient algorithm for robust approximate message passing (AMP) in the spiked matrix setting. In particular, let $\varepsilon$ be a sufficiently small constant, and suppose that $X \in \mathbb R^{n \times n}$ is a Gaussian matrix with a planted rank-$1$ spike, and $E \in \mathbb R^{n \times n}$ is an adversarially chosen matrix supported on an $\varepsilon n \times \varepsilon n$ principal minor. Let $v_{\mathrm{AMP}}(X)$ be the output of an AMP iteration on the uncorrupted matrix $X$. We give a procedure that, given access only to the corrupted matrix $Y = X + E$, computes a vector $v_{\mathrm{ALG}}(Y)$ which is $\tilde{O}(\sqrt{\varepsilon})$-close to $v_{\mathrm{AMP}}(X)$, for any of a class of AMP iterations which includes sparse Principal Component Analysis (PCA), non-negative PCA, and $\mathbb Z_2$ synchronization. Our algorithm consists of a spectral pre-processing step combined with a robust spectral initialization procedure; given these inputs, we prove that (perhaps surprisingly) AMP is robust out-of-the-box.
Fast, robust approximate message passing
Nov 05, 2024
We give a fast, spectral procedure for implementing approximate-message passing (AMP) algorithms robustly. For any quadratic optimization problem over symmetric matrices $X$ with independent subgaussian entries, and any separable AMP algorithm $\mathcal A$, our algorithm performs a spectral pre-processing step and then mildly modifies the iterates of $\mathcal A$. If given the perturbed input $X + E \in \mathbb R^{n \times n}$ for any $E$ supported on a $\varepsilon n \times \varepsilon n$ principal minor, our algorithm outputs a solution $\hat v$ which is guaranteed to be close to the output of $\mathcal A$ on the uncorrupted $X$, with $\|\mathcal A(X) - \hat v\|_2 \le f(\varepsilon) \|\mathcal A(X)\|_2$ where $f(\varepsilon) \to 0$ as $\varepsilon \to 0$ depending only on $\varepsilon$.
Semidefinite programs simulate approximate message passing robustly
Nov 15, 2023Approximate message passing (AMP) is a family of iterative algorithms that generalize matrix power iteration. AMP algorithms are known to optimally solve many average-case optimization problems. In this paper, we show that a large class of AMP algorithms can be simulated in polynomial time by \emph{local statistics hierarchy} semidefinite programs (SDPs), even when an unknown principal minor of measure $1/\mathrm{polylog}(\mathrm{dimension})$ is adversarially corrupted. Ours are the first robust guarantees for many of these problems. Further, our results offer an interesting counterpoint to strong lower bounds against less constrained SDP relaxations for average-case max-cut-gain (a.k.a. "optimizing the Sherrington-Kirkpatrick Hamiltonian") and other problems.
Spectral clustering in the Gaussian mixture block model
Apr 29, 2023
Gaussian mixture block models are distributions over graphs that strive to model modern networks: to generate a graph from such a model, we associate each vertex $i$ with a latent feature vector $u_i \in \mathbb{R}^d$ sampled from a mixture of Gaussians, and we add edge $(i,j)$ if and only if the feature vectors are sufficiently similar, in that $\langle u_i,u_j \rangle \ge \tau$ for a pre-specified threshold $\tau$. The different components of the Gaussian mixture represent the fact that there may be different types of nodes with different distributions over features -- for example, in a social network each component represents the different attributes of a distinct community. Natural algorithmic tasks associated with these networks are embedding (recovering the latent feature vectors) and clustering (grouping nodes by their mixture component). In this paper we initiate the study of clustering and embedding graphs sampled from high-dimensional Gaussian mixture block models, where the dimension of the latent feature vectors $d\to \infty$ as the size of the network $n \to \infty$. This high-dimensional setting is most appropriate in the context of modern networks, in which we think of the latent feature space as being high-dimensional. We analyze the performance of canonical spectral clustering and embedding algorithms for such graphs in the case of 2-component spherical Gaussian mixtures, and begin to sketch out the information-computation landscape for clustering and embedding in these models.
The Franz-Parisi Criterion and Computational Trade-offs in High Dimensional Statistics
May 19, 2022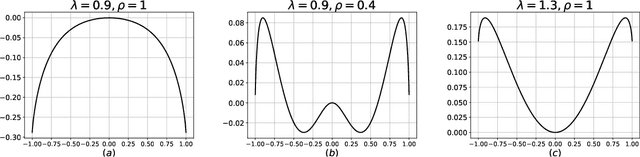
Many high-dimensional statistical inference problems are believed to possess inherent computational hardness. Various frameworks have been proposed to give rigorous evidence for such hardness, including lower bounds against restricted models of computation (such as low-degree functions), as well as methods rooted in statistical physics that are based on free energy landscapes. This paper aims to make a rigorous connection between the seemingly different low-degree and free-energy based approaches. We define a free-energy based criterion for hardness and formally connect it to the well-established notion of low-degree hardness for a broad class of statistical problems, namely all Gaussian additive models and certain models with a sparse planted signal. By leveraging these rigorous connections we are able to: establish that for Gaussian additive models the "algebraic" notion of low-degree hardness implies failure of "geometric" local MCMC algorithms, and provide new low-degree lower bounds for sparse linear regression which seem difficult to prove directly. These results provide both conceptual insights into the connections between different notions of hardness, as well as concrete technical tools such as new methods for proving low-degree lower bounds.
A Robust Spectral Algorithm for Overcomplete Tensor Decomposition
Mar 05, 2022
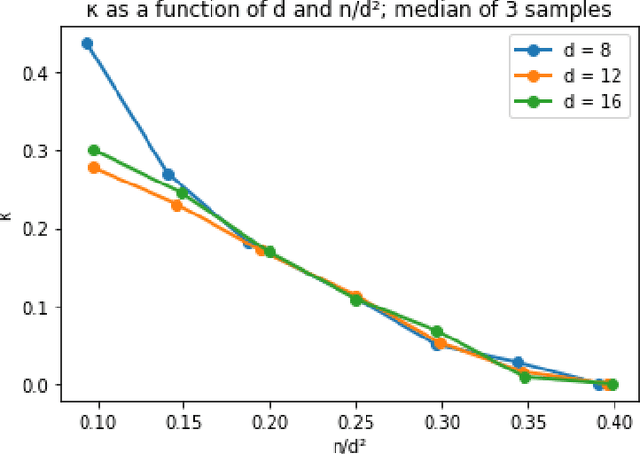
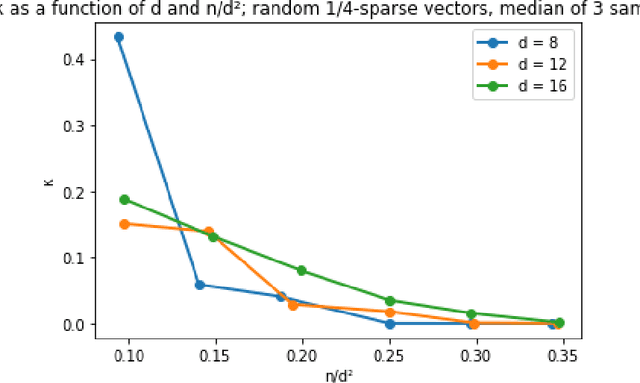
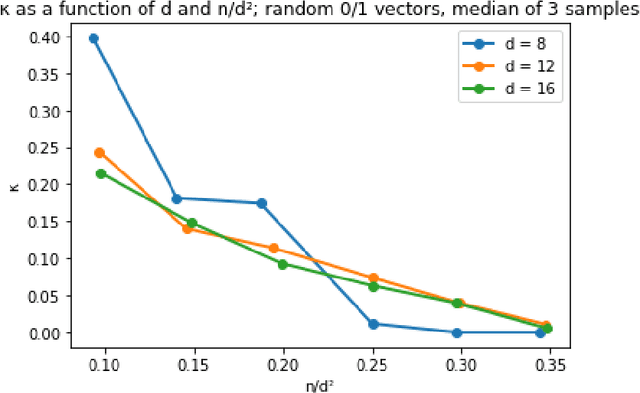
We give a spectral algorithm for decomposing overcomplete order-4 tensors, so long as their components satisfy an algebraic non-degeneracy condition that holds for nearly all (all but an algebraic set of measure $0$) tensors over $(\mathbb{R}^d)^{\otimes 4}$ with rank $n \le d^2$. Our algorithm is robust to adversarial perturbations of bounded spectral norm. Our algorithm is inspired by one which uses the sum-of-squares semidefinite programming hierarchy (Ma, Shi, and Steurer STOC'16, arXiv:1610.01980), and we achieve comparable robustness and overcompleteness guarantees under similar algebraic assumptions. However, our algorithm avoids semidefinite programming and may be implemented as a series of basic linear-algebraic operations. We consequently obtain a much faster running time than semidefinite programming methods: our algorithm runs in time $\tilde O(n^2d^3) \le \tilde O(d^7)$, which is subquadratic in the input size $d^4$ (where we have suppressed factors related to the condition number of the input tensor).
* 60 pages, 4 figures, ACM Annual Workshop on Computational Learning Theory 2019
Robust Regression Revisited: Acceleration and Improved Estimation Rates
Jun 22, 2021We study fast algorithms for statistical regression problems under the strong contamination model, where the goal is to approximately optimize a generalized linear model (GLM) given adversarially corrupted samples. Prior works in this line of research were based on the robust gradient descent framework of Prasad et. al., a first-order method using biased gradient queries, or the Sever framework of Diakonikolas et. al., an iterative outlier-removal method calling a stationary point finder. We present nearly-linear time algorithms for robust regression problems with improved runtime or estimation guarantees compared to the state-of-the-art. For the general case of smooth GLMs (e.g. logistic regression), we show that the robust gradient descent framework of Prasad et. al. can be accelerated, and show our algorithm extends to optimizing the Moreau envelopes of Lipschitz GLMs (e.g. support vector machines), answering several open questions in the literature. For the well-studied case of robust linear regression, we present an alternative approach obtaining improved estimation rates over prior nearly-linear time algorithms. Interestingly, our method starts with an identifiability proof introduced in the context of the sum-of-squares algorithm of Bakshi and Prasad, which achieved optimal error rates while requiring large polynomial runtime and sample complexity. We reinterpret their proof within the Sever framework and obtain a dramatically faster and more sample-efficient algorithm under fewer distributional assumptions.
Non-asymptotic approximations of neural networks by Gaussian processes
Feb 17, 2021We study the extent to which wide neural networks may be approximated by Gaussian processes when initialized with random weights. It is a well-established fact that as the width of a network goes to infinity, its law converges to that of a Gaussian process. We make this quantitative by establishing explicit convergence rates for the central limit theorem in an infinite-dimensional functional space, metrized with a natural transportation distance. We identify two regimes of interest; when the activation function is polynomial, its degree determines the rate of convergence, while for non-polynomial activations, the rate is governed by the smoothness of the function.
Statistical Query Algorithms and Low-Degree Tests Are Almost Equivalent
Sep 13, 2020Researchers currently use a number of approaches to predict and substantiate information-computation gaps in high-dimensional statistical estimation problems. A prominent approach is to characterize the limits of restricted models of computation, which on the one hand yields strong computational lower bounds for powerful classes of algorithms and on the other hand helps guide the development of efficient algorithms. In this paper, we study two of the most popular restricted computational models, the statistical query framework and low-degree polynomials, in the context of high-dimensional hypothesis testing. Our main result is that under mild conditions on the testing problem, the two classes of algorithms are essentially equivalent in power. As corollaries, we obtain new statistical query lower bounds for sparse PCA, tensor PCA and several variants of the planted clique problem.
Computational Barriers to Estimation from Low-Degree Polynomials
Aug 05, 2020One fundamental goal of high-dimensional statistics is to detect or recover structure from noisy data. In many cases, the data can be faithfully modeled by a planted structure (such as a low-rank matrix) perturbed by random noise. But even for these simple models, the computational complexity of estimation is sometimes poorly understood. A growing body of work studies low-degree polynomials as a proxy for computational complexity: it has been demonstrated in various settings that low-degree polynomials of the data can match the statistical performance of the best known polynomial-time algorithms for detection. While prior work has studied the power of low-degree polynomials for the task of detecting the presence of hidden structures, it has failed to address the estimation problem in settings where detection is qualitatively easier than estimation. In this work, we extend the method of low-degree polynomials to address problems of estimation and recovery. For a large class of "signal plus noise" problems, we give a user-friendly lower bound for the best possible mean squared error achievable by any degree-D polynomial. To our knowledge, this is the first instance in which the low-degree polynomial method can establish low-degree hardness of recovery problems where the associated detection problem is easy. As applications, we give a tight characterization of the low-degree minimum mean squared error for the planted submatrix and planted dense subgraph problems, resolving (in the low-degree framework) open problems about the computational complexity of recovery in both cases.