 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms with Polynomially-Improved Approximation Factors for the $2 \rightarrow q$ Norm, and Applications
May 28, 2026The $2 \rightarrow q$ norm of a matrix $X \in \mathbb{R}^{n \times d}$ is defined as $\lVert X \rVert_{2 \rightarrow q} = \sup_{\lVert v \rVert_2 = 1} \lVert Xv \rVert_q$. We give polynomial-time multiplicative approximation algorithms for this norm when $q > 2$ (i.e. in the hypercontractive setting). This problem either directly captures or is closely related to long-standing open problems in combinatorial optimization and hardness of approximation (e.g. Small Set Expansion), quantum information (e.g. Best Separable State), and algorithmic statistics. Very little is known about what approximation factors we can achieve for this problem in polynomial time, even though such approximations have significant downstream consequences. Barak, Brandão, Harrow, Kelner, Steurer, and Zhou showed that no polynomial-time algorithm can achieve an approximation factor better than $2^{\sqrt{\log n}}$, assuming the Exponential Time Hypothesis (FOCS'12). On the other hand, a simple spectral algorithm gives a $d^{1/4}$-approximation as a baseline. We give, to the best of our knowledge, the first polynomial-time approximation algorithm beating this baseline by polynomial factors. For the important special case of $q = 4$ it achieves a $d^{1/8}$-approximation. All previous algorithms required additional assumptions on $X$, or only surpassed the baseline for small values of $n$. Moreover, we construct sum-of-squares certificates for the $2 \rightarrow q$ norm. This directly implies improved algorithms for robust mean and covariance estimation, robust regression, and clustering, when the data only satisfies a bound on its $q$-th moment.
On the Accuracy of Newton Step and Influence Function Data Attributions
Dec 14, 2025

Data attribution aims to explain model predictions by estimating how they would change if certain training points were removed, and is used in a wide range of applications, from interpretability and credit assignment to unlearning and privacy. Even in the relatively simple case of linear regressions, existing mathematical analyses of leading data attribution methods such as Influence Functions (IF) and single Newton Step (NS) remain limited in two key ways. First, they rely on global strong convexity assumptions which are often not satisfied in practice. Second, the resulting bounds scale very poorly with the number of parameters ($d$) and the number of samples removed ($k$). As a result, these analyses are not tight enough to answer fundamental questions such as "what is the asymptotic scaling of the errors of each method?" or "which of these methods is more accurate for a given dataset?" In this paper, we introduce a new analysis of the NS and IF data attribution methods for convex learning problems. To the best of our knowledge, this is the first analysis of these questions that does not assume global strong convexity and also the first explanation of [KATL19] and [RH25a]'s observation that NS data attribution is often more accurate than IF. We prove that for sufficiently well-behaved logistic regression, our bounds are asymptotically tight up to poly-logarithmic factors, yielding scaling laws for the errors in the average-case sample removals. \[ \mathbb{E}_{T \subseteq [n],\, |T| = k} \bigl[ \|\hatθ_T - \hatθ_T^{\mathrm{NS}}\|_2 \bigr] = \widetildeΘ\!\left(\frac{k d}{n^2}\right), \qquad \mathbb{E}_{T \subseteq [n],\, |T| = k} \bigl[ \|\hatθ_T^{\mathrm{NS}} - \hatθ_T^{\mathrm{IF}}\|_2 \bigr] = \widetildeΘ\!\left( \frac{(k + d)\sqrt{k d}}{n^2} \right). \]
Rescaled Influence Functions: Accurate Data Attribution in High Dimension
Jun 07, 2025How does the training data affect a model's behavior? This is the question we seek to answer with data attribution. The leading practical approaches to data attribution are based on influence functions (IF). IFs utilize a first-order Taylor approximation to efficiently predict the effect of removing a set of samples from the training set without retraining the model, and are used in a wide variety of machine learning applications. However, especially in the high-dimensional regime (# params $\geq \Omega($# samples$)$), they are often imprecise and tend to underestimate the effect of sample removals, even for simple models such as logistic regression. We present rescaled influence functions (RIF), a new tool for data attribution which can be used as a drop-in replacement for influence functions, with little computational overhead but significant improvement in accuracy. We compare IF and RIF on a range of real-world datasets, showing that RIFs offer significantly better predictions in practice, and present a theoretical analysis explaining this improvement. Finally, we present a simple class of data poisoning attacks that would fool IF-based detections but would be detected by RIF.
SoS Certificates for Sparse Singular Values and Their Applications: Robust Statistics, Subspace Distortion, and More
Dec 30, 2024



We study $\textit{sparse singular value certificates}$ for random rectangular matrices. If $M$ is an $n \times d$ matrix with independent Gaussian entries, we give a new family of polynomial-time algorithms which can certify upper bounds on the maximum of $\|M u\|$, where $u$ is a unit vector with at most $\eta n$ nonzero entries for a given $\eta \in (0,1)$. This basic algorithmic primitive lies at the heart of a wide range of problems across algorithmic statistics and theoretical computer science. Our algorithms certify a bound which is asymptotically smaller than the naive one, given by the maximum singular value of $M$, for nearly the widest-possible range of $n,d,$ and $\eta$. Efficiently certifying such a bound for a range of $n,d$ and $\eta$ which is larger by any polynomial factor than what is achieved by our algorithm would violate lower bounds in the SQ and low-degree polynomials models. Our certification algorithm makes essential use of the Sum-of-Squares hierarchy. To prove the correctness of our algorithm, we develop a new combinatorial connection between the graph matrix approach to analyze random matrices with dependent entries, and the Efron-Stein decomposition of functions of independent random variables. As applications of our certification algorithm, we obtain new efficient algorithms for a wide range of well-studied algorithmic tasks. In algorithmic robust statistics, we obtain new algorithms for robust mean and covariance estimation with tradeoffs between breakdown point and sample complexity, which are nearly matched by SQ and low-degree polynomial lower bounds (that we establish). We also obtain new polynomial-time guarantees for certification of $\ell_1/\ell_2$ distortion of random subspaces of $\mathbb{R}^n$ (also with nearly matching lower bounds), sparse principal component analysis, and certification of the $2\rightarrow p$ norm of a random matrix.
SoS Certifiability of Subgaussian Distributions and its Algorithmic Applications
Oct 28, 2024
We prove that there is a universal constant $C>0$ so that for every $d \in \mathbb N$, every centered subgaussian distribution $\mathcal D$ on $\mathbb R^d$, and every even $p \in \mathbb N$, the $d$-variate polynomial $(Cp)^{p/2} \cdot \|v\|_{2}^p - \mathbb E_{X \sim \mathcal D} \langle v,X\rangle^p$ is a sum of square polynomials. This establishes that every subgaussian distribution is \emph{SoS-certifiably subgaussian} -- a condition that yields efficient learning algorithms for a wide variety of high-dimensional statistical tasks. As a direct corollary, we obtain computationally efficient algorithms with near-optimal guarantees for the following tasks, when given samples from an arbitrary subgaussian distribution: robust mean estimation, list-decodable mean estimation, clustering mean-separated mixture models, robust covariance-aware mean estimation, robust covariance estimation, and robust linear regression. Our proof makes essential use of Talagrand's generic chaining/majorizing measures theorem.
Robustness Auditing for Linear Regression: To Singularity and Beyond
Oct 10, 2024It has recently been discovered that the conclusions of many highly influential econometrics studies can be overturned by removing a very small fraction of their samples (often less than $0.5\%$). These conclusions are typically based on the results of one or more Ordinary Least Squares (OLS) regressions, raising the question: given a dataset, can we certify the robustness of an OLS fit on this dataset to the removal of a given number of samples? Brute-force techniques quickly break down even on small datasets. Existing approaches which go beyond brute force either can only find candidate small subsets to remove (but cannot certify their non-existence) [BGM20, KZC21], are computationally intractable beyond low dimensional settings [MR22], or require very strong assumptions on the data distribution and too many samples to give reasonable bounds in practice [BP21, FH23]. We present an efficient algorithm for certifying the robustness of linear regressions to removals of samples. We implement our algorithm and run it on several landmark econometrics datasets with hundreds of dimensions and tens of thousands of samples, giving the first non-trivial certificates of robustness to sample removal for datasets of dimension $4$ or greater. We prove that under distributional assumptions on a dataset, the bounds produced by our algorithm are tight up to a $1 + o(1)$ multiplicative factor.
Adversarially-Robust Inference on Trees via Belief Propagation
Mar 31, 2024
We introduce and study the problem of posterior inference on tree-structured graphical models in the presence of a malicious adversary who can corrupt some observed nodes. In the well-studied broadcasting on trees model, corresponding to the ferromagnetic Ising model on a $d$-regular tree with zero external field, when a natural signal-to-noise ratio exceeds one (the celebrated Kesten-Stigum threshold), the posterior distribution of the root given the leaves is bounded away from $\mathrm{Ber}(1/2)$, and carries nontrivial information about the sign of the root. This posterior distribution can be computed exactly via dynamic programming, also known as belief propagation. We first confirm a folklore belief that a malicious adversary who can corrupt an inverse-polynomial fraction of the leaves of their choosing makes this inference impossible. Our main result is that accurate posterior inference about the root vertex given the leaves is possible when the adversary is constrained to make corruptions at a $\rho$-fraction of randomly-chosen leaf vertices, so long as the signal-to-noise ratio exceeds $O(\log d)$ and $\rho \leq c \varepsilon$ for some universal $c > 0$. Since inference becomes information-theoretically impossible when $\rho \gg \varepsilon$, this amounts to an information-theoretically optimal fraction of corruptions, up to a constant multiplicative factor. Furthermore, we show that the canonical belief propagation algorithm performs this inference.
A quasi-polynomial time algorithm for Multi-Dimensional Scaling via LP hierarchies
Nov 29, 2023
Multi-dimensional Scaling (MDS) is a family of methods for embedding pair-wise dissimilarities between $n$ objects into low-dimensional space. MDS is widely used as a data visualization tool in the social and biological sciences, statistics, and machine learning. We study the Kamada-Kawai formulation of MDS: given a set of non-negative dissimilarities $\{d_{i,j}\}_{i , j \in [n]}$ over $n$ points, the goal is to find an embedding $\{x_1,\dots,x_n\} \subset \mathbb{R}^k$ that minimizes \[ \text{OPT} = \min_{x} \mathbb{E}_{i,j \in [n]} \left[ \left(1-\frac{\|x_i - x_j\|}{d_{i,j}}\right)^2 \right] \] Despite its popularity, our theoretical understanding of MDS is extremely limited. Recently, Demaine, Hesterberg, Koehler, Lynch, and Urschel (arXiv:2109.11505) gave the first approximation algorithm with provable guarantees for Kamada-Kawai, which achieves an embedding with cost $\text{OPT} +\epsilon$ in $n^2 \cdot 2^{\tilde{\mathcal{O}}(k \Delta^4 / \epsilon^2)}$ time, where $\Delta$ is the aspect ratio of the input dissimilarities. In this work, we give the first approximation algorithm for MDS with quasi-polynomial dependency on $\Delta$: for target dimension $k$, we achieve a solution with cost $\mathcal{O}(\text{OPT}^{ \hspace{0.04in}1/k } \cdot \log(\Delta/\epsilon) )+ \epsilon$ in time $n^{ \mathcal{O}(1)} \cdot 2^{\tilde{\mathcal{O}}( k^2 (\log(\Delta)/\epsilon)^{k/2 + 1} ) }$. Our approach is based on a novel analysis of a conditioning-based rounding scheme for the Sherali-Adams LP Hierarchy. Crucially, our analysis exploits the geometry of low-dimensional Euclidean space, allowing us to avoid an exponential dependence on the aspect ratio $\Delta$. We believe our geometry-aware treatment of the Sherali-Adams Hierarchy is an important step towards developing general-purpose techniques for efficient metric optimization algorithms.
Towards Practical Robustness Auditing for Linear Regression
Jul 30, 2023


We investigate practical algorithms to find or disprove the existence of small subsets of a dataset which, when removed, reverse the sign of a coefficient in an ordinary least squares regression involving that dataset. We empirically study the performance of well-established algorithmic techniques for this task -- mixed integer quadratically constrained optimization for general linear regression problems and exact greedy methods for special cases. We show that these methods largely outperform the state of the art and provide a useful robustness check for regression problems in a few dimensions. However, significant computational bottlenecks remain, especially for the important task of disproving the existence of such small sets of influential samples for regression problems of dimension $3$ or greater. We make some headway on this challenge via a spectral algorithm using ideas drawn from recent innovations in algorithmic robust statistics. We summarize the limitations of known techniques in several challenge datasets to encourage further algorithmic innovation.
Fast, Sample-Efficient, Affine-Invariant Private Mean and Covariance Estimation for Subgaussian Distributions
Jan 28, 2023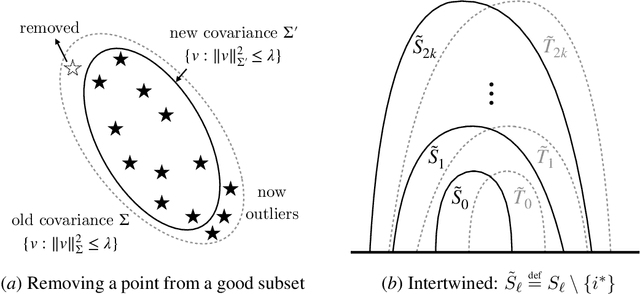
We present a fast, differentially private algorithm for high-dimensional covariance-aware mean estimation with nearly optimal sample complexity. Only exponential-time estimators were previously known to achieve this guarantee. Given $n$ samples from a (sub-)Gaussian distribution with unknown mean $\mu$ and covariance $\Sigma$, our $(\varepsilon,\delta)$-differentially private estimator produces $\tilde{\mu}$ such that $\|\mu - \tilde{\mu}\|_{\Sigma} \leq \alpha$ as long as $n \gtrsim \tfrac d {\alpha^2} + \tfrac{d \sqrt{\log 1/\delta}}{\alpha \varepsilon}+\frac{d\log 1/\delta}{\varepsilon}$. The Mahalanobis error metric $\|\mu - \hat{\mu}\|_{\Sigma}$ measures the distance between $\hat \mu$ and $\mu$ relative to $\Sigma$; it characterizes the error of the sample mean. Our algorithm runs in time $\tilde{O}(nd^{\omega - 1} + nd/\varepsilon)$, where $\omega < 2.38$ is the matrix multiplication exponent. We adapt an exponential-time approach of Brown, Gaboardi, Smith, Ullman, and Zakynthinou (2021), giving efficient variants of stable mean and covariance estimation subroutines that also improve the sample complexity to the nearly optimal bound above. Our stable covariance estimator can be turned to private covariance estimation for unrestricted subgaussian distributions. With $n\gtrsim d^{3/2}$ samples, our estimate is accurate in spectral norm. This is the first such algorithm using $n= o(d^2)$ samples, answering an open question posed by Alabi et al. (2022). With $n\gtrsim d^2$ samples, our estimate is accurate in Frobenius norm. This leads to a fast, nearly optimal algorithm for private learning of unrestricted Gaussian distributions in TV distance. Duchi, Haque, and Kuditipudi (2023) obtained similar results independently and concurrently.