 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Optimal Private Regression in Polynomial Time
Mar 31, 2025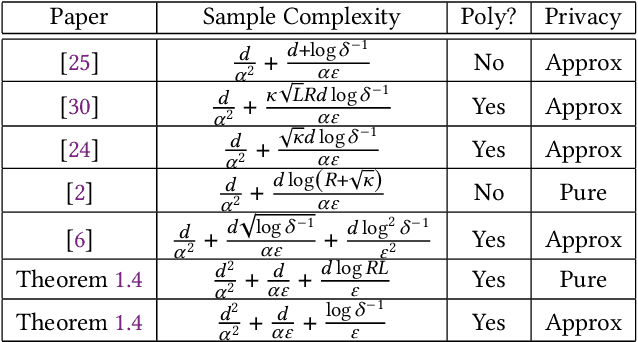
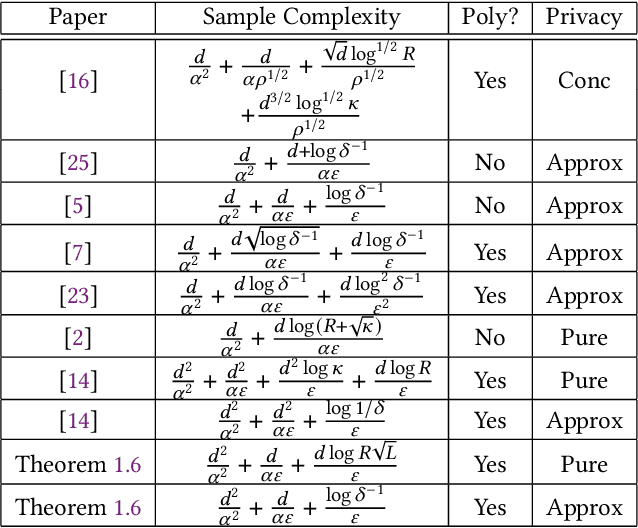
We consider the task of privately obtaining prediction error guarantees in ordinary least-squares regression problems with Gaussian covariates (with unknown covariance structure). We provide the first sample-optimal polynomial time algorithm for this task under both pure and approximate differential privacy. We show that any improvement to the sample complexity of our algorithm would violate either statistical-query or information-theoretic lower bounds. Additionally, our algorithm is robust to a small fraction of arbitrary outliers and achieves optimal error rates as a function of the fraction of outliers. In contrast, all prior efficient algorithms either incurred sample complexities with sub-optimal dimension dependence, scaling with the condition number of the covariates, or obtained a polynomially worse dependence on the privacy parameters. Our technical contributions are two-fold: first, we leverage resilience guarantees of Gaussians within the sum-of-squares framework. As a consequence, we obtain efficient sum-of-squares algorithms for regression with optimal robustness rates and sample complexity. Second, we generalize the recent robustness-to-privacy framework [HKMN23, (arXiv:2212.05015)] to account for the geometry induced by the covariance of the input samples. This framework crucially relies on the robust estimators to be sum-of-squares algorithms, and combining the two steps yields a sample-optimal private regression algorithm. We believe our techniques are of independent interest, and we demonstrate this by obtaining an efficient algorithm for covariance-aware mean estimation, with an optimal dependence on the privacy parameters.
Efficient Certificates of Anti-Concentration Beyond Gaussians
May 23, 2024A set of high dimensional points $X=\{x_1, x_2,\ldots, x_n\} \subset R^d$ in isotropic position is said to be $\delta$-anti concentrated if for every direction $v$, the fraction of points in $X$ satisfying $|\langle x_i,v \rangle |\leq \delta$ is at most $O(\delta)$. Motivated by applications to list-decodable learning and clustering, recent works have considered the problem of constructing efficient certificates of anti-concentration in the average case, when the set of points $X$ corresponds to samples from a Gaussian distribution. Their certificates played a crucial role in several subsequent works in algorithmic robust statistics on list-decodable learning and settling the robust learnability of arbitrary Gaussian mixtures, yet remain limited to rotationally invariant distributions. This work presents a new (and arguably the most natural) formulation for anti-concentration. Using this formulation, we give quasi-polynomial time verifiable sum-of-squares certificates of anti-concentration that hold for a wide class of non-Gaussian distributions including anti-concentrated bounded product distributions and uniform distributions over $L_p$ balls (and their affine transformations). Consequently, our method upgrades and extends results in algorithmic robust statistics e.g., list-decodable learning and clustering, to such distributions. Our approach constructs a canonical integer program for anti-concentration and analysis a sum-of-squares relaxation of it, independent of the intended application. We rely on duality and analyze a pseudo-expectation on large subsets of the input points that take a small value in some direction. Our analysis uses the method of polynomial reweightings to reduce the problem to analyzing only analytically dense or sparse directions.
Structure learning of Hamiltonians from real-time evolution
Apr 30, 2024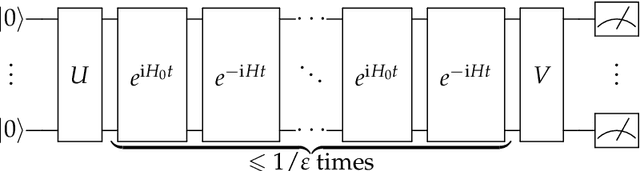
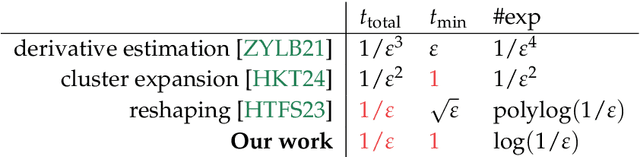
We initiate the study of Hamiltonian structure learning from real-time evolution: given the ability to apply $e^{-\mathrm{i} Ht}$ for an unknown local Hamiltonian $H = \sum_{a = 1}^m \lambda_a E_a$ on $n$ qubits, the goal is to recover $H$. This problem is already well-studied under the assumption that the interaction terms, $E_a$, are given, and only the interaction strengths, $\lambda_a$, are unknown. But is it possible to learn a local Hamiltonian without prior knowledge of its interaction structure? We present a new, general approach to Hamiltonian learning that not only solves the challenging structure learning variant, but also resolves other open questions in the area, all while achieving the gold standard of Heisenberg-limited scaling. In particular, our algorithm recovers the Hamiltonian to $\varepsilon$ error with an evolution time scaling with $1/\varepsilon$, and has the following appealing properties: (1) it does not need to know the Hamiltonian terms; (2) it works beyond the short-range setting, extending to any Hamiltonian $H$ where the sum of terms interacting with a qubit has bounded norm; (3) it evolves according to $H$ in constant time $t$ increments, thus achieving constant time resolution. To our knowledge, no prior algorithm with Heisenberg-limited scaling existed with even one of these properties. As an application, we can also learn Hamiltonians exhibiting power-law decay up to accuracy $\varepsilon$ with total evolution time beating the standard limit of $1/\varepsilon^2$.
A quasi-polynomial time algorithm for Multi-Dimensional Scaling via LP hierarchies
Nov 29, 2023
Multi-dimensional Scaling (MDS) is a family of methods for embedding pair-wise dissimilarities between $n$ objects into low-dimensional space. MDS is widely used as a data visualization tool in the social and biological sciences, statistics, and machine learning. We study the Kamada-Kawai formulation of MDS: given a set of non-negative dissimilarities $\{d_{i,j}\}_{i , j \in [n]}$ over $n$ points, the goal is to find an embedding $\{x_1,\dots,x_n\} \subset \mathbb{R}^k$ that minimizes \[ \text{OPT} = \min_{x} \mathbb{E}_{i,j \in [n]} \left[ \left(1-\frac{\|x_i - x_j\|}{d_{i,j}}\right)^2 \right] \] Despite its popularity, our theoretical understanding of MDS is extremely limited. Recently, Demaine, Hesterberg, Koehler, Lynch, and Urschel (arXiv:2109.11505) gave the first approximation algorithm with provable guarantees for Kamada-Kawai, which achieves an embedding with cost $\text{OPT} +\epsilon$ in $n^2 \cdot 2^{\tilde{\mathcal{O}}(k \Delta^4 / \epsilon^2)}$ time, where $\Delta$ is the aspect ratio of the input dissimilarities. In this work, we give the first approximation algorithm for MDS with quasi-polynomial dependency on $\Delta$: for target dimension $k$, we achieve a solution with cost $\mathcal{O}(\text{OPT}^{ \hspace{0.04in}1/k } \cdot \log(\Delta/\epsilon) )+ \epsilon$ in time $n^{ \mathcal{O}(1)} \cdot 2^{\tilde{\mathcal{O}}( k^2 (\log(\Delta)/\epsilon)^{k/2 + 1} ) }$. Our approach is based on a novel analysis of a conditioning-based rounding scheme for the Sherali-Adams LP Hierarchy. Crucially, our analysis exploits the geometry of low-dimensional Euclidean space, allowing us to avoid an exponential dependence on the aspect ratio $\Delta$. We believe our geometry-aware treatment of the Sherali-Adams Hierarchy is an important step towards developing general-purpose techniques for efficient metric optimization algorithms.
Learning quantum Hamiltonians at any temperature in polynomial time
Oct 03, 2023We study the problem of learning a local quantum Hamiltonian $H$ given copies of its Gibbs state $\rho = e^{-\beta H}/\textrm{tr}(e^{-\beta H})$ at a known inverse temperature $\beta>0$. Anshu, Arunachalam, Kuwahara, and Soleimanifar (arXiv:2004.07266) gave an algorithm to learn a Hamiltonian on $n$ qubits to precision $\epsilon$ with only polynomially many copies of the Gibbs state, but which takes exponential time. Obtaining a computationally efficient algorithm has been a major open problem [Alhambra'22 (arXiv:2204.08349)], [Anshu, Arunachalam'22 (arXiv:2204.08349)], with prior work only resolving this in the limited cases of high temperature [Haah, Kothari, Tang'21 (arXiv:2108.04842)] or commuting terms [Anshu, Arunachalam, Kuwahara, Soleimanifar'21]. We fully resolve this problem, giving a polynomial time algorithm for learning $H$ to precision $\epsilon$ from polynomially many copies of the Gibbs state at any constant $\beta > 0$. Our main technical contribution is a new flat polynomial approximation to the exponential function, and a translation between multi-variate scalar polynomials and nested commutators. This enables us to formulate Hamiltonian learning as a polynomial system. We then show that solving a low-degree sum-of-squares relaxation of this polynomial system suffices to accurately learn the Hamiltonian.
Tensor Decompositions Meet Control Theory: Learning General Mixtures of Linear Dynamical Systems
Jul 23, 2023Recently Chen and Poor initiated the study of learning mixtures of linear dynamical systems. While linear dynamical systems already have wide-ranging applications in modeling time-series data, using mixture models can lead to a better fit or even a richer understanding of underlying subpopulations represented in the data. In this work we give a new approach to learning mixtures of linear dynamical systems that is based on tensor decompositions. As a result, our algorithm succeeds without strong separation conditions on the components, and can be used to compete with the Bayes optimal clustering of the trajectories. Moreover our algorithm works in the challenging partially-observed setting. Our starting point is the simple but powerful observation that the classic Ho-Kalman algorithm is a close relative of modern tensor decomposition methods for learning latent variable models. This gives us a playbook for how to extend it to work with more complicated generative models.
A Near-Linear Time Algorithm for the Chamfer Distance
Jul 06, 2023



For any two point sets $A,B \subset \mathbb{R}^d$ of size up to $n$, the Chamfer distance from $A$ to $B$ is defined as $\text{CH}(A,B)=\sum_{a \in A} \min_{b \in B} d_X(a,b)$, where $d_X$ is the underlying distance measure (e.g., the Euclidean or Manhattan distance). The Chamfer distance is a popular measure of dissimilarity between point clouds, used in many machine learning, computer vision, and graphics applications, and admits a straightforward $O(d n^2)$-time brute force algorithm. Further, the Chamfer distance is often used as a proxy for the more computationally demanding Earth-Mover (Optimal Transport) Distance. However, the \emph{quadratic} dependence on $n$ in the running time makes the naive approach intractable for large datasets. We overcome this bottleneck and present the first $(1+\epsilon)$-approximate algorithm for estimating the Chamfer distance with a near-linear running time. Specifically, our algorithm runs in time $O(nd \log (n)/\varepsilon^2)$ and is implementable. Our experiments demonstrate that it is both accurate and fast on large high-dimensional datasets. We believe that our algorithm will open new avenues for analyzing large high-dimensional point clouds. We also give evidence that if the goal is to \emph{report} a $(1+\varepsilon)$-approximate mapping from $A$ to $B$ (as opposed to just its value), then any sub-quadratic time algorithm is unlikely to exist.
Krylov Methods are Optimal for Low-Rank Approximation
Apr 06, 2023We consider the problem of rank-$1$ low-rank approximation (LRA) in the matrix-vector product model under various Schatten norms: $$ \min_{\|u\|_2=1} \|A (I - u u^\top)\|_{\mathcal{S}_p} , $$ where $\|M\|_{\mathcal{S}_p}$ denotes the $\ell_p$ norm of the singular values of $M$. Given $\varepsilon>0$, our goal is to output a unit vector $v$ such that $$ \|A(I - vv^\top)\|_{\mathcal{S}_p} \leq (1+\varepsilon) \min_{\|u\|_2=1}\|A(I - u u^\top)\|_{\mathcal{S}_p}. $$ Our main result shows that Krylov methods (nearly) achieve the information-theoretically optimal number of matrix-vector products for Spectral ($p=\infty$), Frobenius ($p=2$) and Nuclear ($p=1$) LRA. In particular, for Spectral LRA, we show that any algorithm requires $\Omega\left(\log(n)/\varepsilon^{1/2}\right)$ matrix-vector products, exactly matching the upper bound obtained by Krylov methods [MM15, BCW22]. Our lower bound addresses Open Question 1 in [Woo14], providing evidence for the lack of progress on algorithms for Spectral LRA and resolves Open Question 1.2 in [BCW22]. Next, we show that for any fixed constant $p$, i.e. $1\leq p =O(1)$, there is an upper bound of $O\left(\log(1/\varepsilon)/\varepsilon^{1/3}\right)$ matrix-vector products, implying that the complexity does not grow as a function of input size. This improves the $O\left(\log(n/\varepsilon)/\varepsilon^{1/3}\right)$ bound recently obtained in [BCW22], and matches their $\Omega\left(1/\varepsilon^{1/3}\right)$ lower bound, to a $\log(1/\varepsilon)$ factor.
A New Approach to Learning Linear Dynamical Systems
Jan 23, 2023Linear dynamical systems are the foundational statistical model upon which control theory is built. Both the celebrated Kalman filter and the linear quadratic regulator require knowledge of the system dynamics to provide analytic guarantees. Naturally, learning the dynamics of a linear dynamical system from linear measurements has been intensively studied since Rudolph Kalman's pioneering work in the 1960's. Towards these ends, we provide the first polynomial time algorithm for learning a linear dynamical system from a polynomial length trajectory up to polynomial error in the system parameters under essentially minimal assumptions: observability, controllability, and marginal stability. Our algorithm is built on a method of moments estimator to directly estimate Markov parameters from which the dynamics can be extracted. Furthermore, we provide statistical lower bounds when our observability and controllability assumptions are violated.
Sub-quadratic Algorithms for Kernel Matrices via Kernel Density Estimation
Dec 01, 2022



Kernel matrices, as well as weighted graphs represented by them, are ubiquitous objects in machine learning, statistics and other related fields. The main drawback of using kernel methods (learning and inference using kernel matrices) is efficiency -- given $n$ input points, most kernel-based algorithms need to materialize the full $n \times n$ kernel matrix before performing any subsequent computation, thus incurring $\Omega(n^2)$ runtime. Breaking this quadratic barrier for various problems has therefore, been a subject of extensive research efforts. We break the quadratic barrier and obtain $\textit{subquadratic}$ time algorithms for several fundamental linear-algebraic and graph processing primitives, including approximating the top eigenvalue and eigenvector, spectral sparsification, solving linear systems, local clustering, low-rank approximation, arboricity estimation and counting weighted triangles. We build on the recent Kernel Density Estimation framework, which (after preprocessing in time subquadratic in $n$) can return estimates of row/column sums of the kernel matrix. In particular, we develop efficient reductions from $\textit{weighted vertex}$ and $\textit{weighted edge sampling}$ on kernel graphs, $\textit{simulating random walks}$ on kernel graphs, and $\textit{importance sampling}$ on matrices to Kernel Density Estimation and show that we can generate samples from these distributions in $\textit{sublinear}$ (in the support of the distribution) time. Our reductions are the central ingredient in each of our applications and we believe they may be of independent interest. We empirically demonstrate the efficacy of our algorithms on low-rank approximation (LRA) and spectral sparsification, where we observe a $\textbf{9x}$ decrease in the number of kernel evaluations over baselines for LRA and a $\textbf{41x}$ reduction in the graph size for spectral sparsification.