 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomization Boosts KV Caching, Learning Balances Query Load: A Joint Perspective
Jan 26, 2026KV caching is a fundamental technique for accelerating Large Language Model (LLM) inference by reusing key-value (KV) pairs from previous queries, but its effectiveness under limited memory is highly sensitive to the eviction policy. The default Least Recently Used (LRU) eviction algorithm struggles with dynamic online query arrivals, especially in multi-LLM serving scenarios, where balancing query load across workers and maximizing cache hit rate of each worker are inherently conflicting objectives. We give the first unified mathematical model that captures the core trade-offs between KV cache eviction and query routing. Our analysis reveals the theoretical limitations of existing methods and leads to principled algorithms that integrate provably competitive randomized KV cache eviction with learning-based methods to adaptively route queries with evolving patterns, thus balancing query load and cache hit rate. Our theoretical results are validated by extensive experiments across 4 benchmarks and 3 prefix-sharing settings, demonstrating improvements of up to 6.92$\times$ in cache hit rate, 11.96$\times$ reduction in latency, 14.06$\times$ reduction in time-to-first-token (TTFT), and 77.4% increase in throughput over the state-of-the-art methods. Our code is available at https://github.com/fzwark/KVRouting.
Hypothesis Selection: A High Probability Conundrum
Sep 03, 2025



In the hypothesis selection problem, we are given a finite set of candidate distributions (hypotheses), $\mathcal{H} = \{H_1, \ldots, H_n\}$, and samples from an unknown distribution $P$. Our goal is to find a hypothesis $H_i$ whose total variation distance to $P$ is comparable to that of the nearest hypothesis in $\mathcal{H}$. If the minimum distance is $\mathsf{OPT}$, we aim to output an $H_i$ such that, with probability at least $1-\delta$, its total variation distance to $P$ is at most $C \cdot \mathsf{OPT} + \varepsilon$. Despite decades of work, key aspects of this problem remain unresolved, including the optimal running time for algorithms that achieve the optimal sample complexity and best possible approximation factor of $C=3$. The previous state-of-the-art result [Aliakbarpour, Bun, Smith, NeurIPS 2024] provided a nearly linear in $n$ time algorithm but with a sub-optimal dependence on the other parameters, running in $\tilde{O}(n/(\delta^3\varepsilon^3))$ time. We improve this time complexity to $\tilde{O}(n/(\delta \varepsilon^2))$, significantly reducing the dependence on the confidence and error parameters. Furthermore, we study hypothesis selection in three alternative settings, resolving or making progress on several open questions from prior works. (1) We settle the optimal approximation factor when bounding the \textit{expected distance} of the output hypothesis, rather than its high-probability performance. (2) Assuming the numerical value of \textit{$\mathsf{OPT}$ is known} in advance, we present an algorithm obtaining $C=3$ and runtime $\tilde{O}(n/\varepsilon^2)$ with the optimal sample complexity and succeeding with high probability in $n$. (3) Allowing polynomial \textit{preprocessing} step on the hypothesis class $\mathcal{H}$ before observing samples, we present an algorithm with $C=3$ and subquadratic runtime which succeeds with high probability in $n$.
Improved Approximations for Hard Graph Problems using Predictions
May 29, 2025

We design improved approximation algorithms for NP-hard graph problems by incorporating predictions (e.g., learned from past data). Our prediction model builds upon and extends the $\varepsilon$-prediction framework by Cohen-Addad, d'Orsi, Gupta, Lee, and Panigrahi (NeurIPS 2024). We consider an edge-based version of this model, where each edge provides two bits of information, corresponding to predictions about whether each of its endpoints belong to an optimal solution. Even with weak predictions where each bit is only $\varepsilon$-correlated with the true solution, this information allows us to break approximation barriers in the standard setting. We develop algorithms with improved approximation ratios for MaxCut, Vertex Cover, Set Cover, and Maximum Independent Set problems (among others). Across these problems, our algorithms share a unifying theme, where we separately satisfy constraints related to high degree vertices (using predictions) and low-degree vertices (without using predictions) and carefully combine the answers.
Learning-Augmented Frequent Directions
Mar 02, 2025
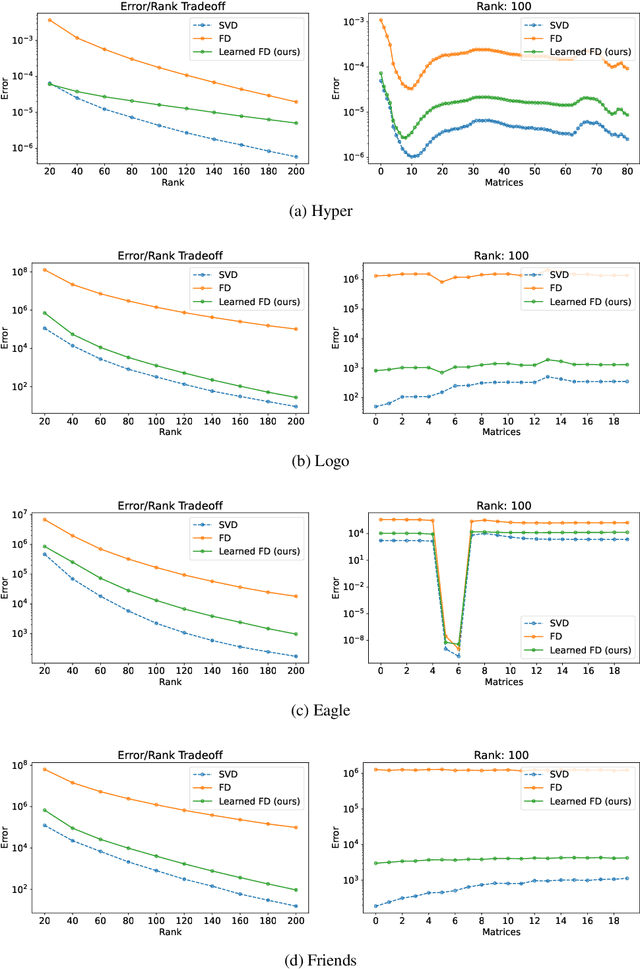
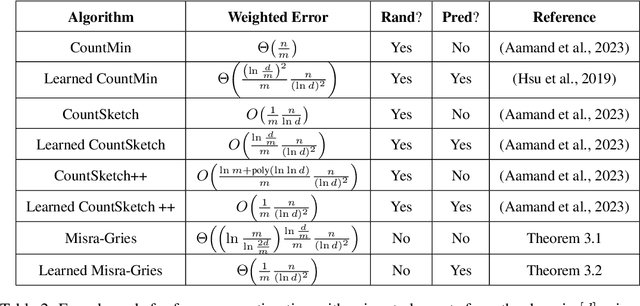
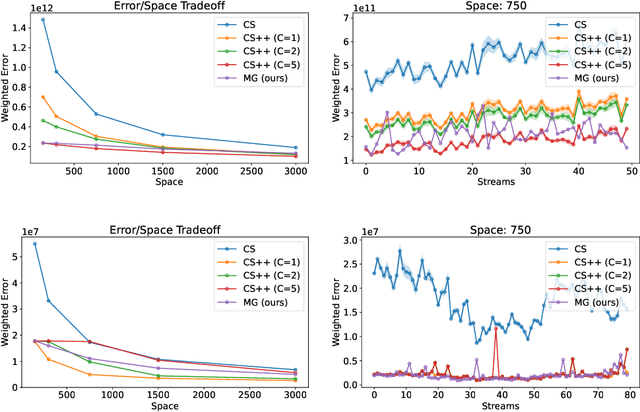
An influential paper of Hsu et al. (ICLR'19) introduced the study of learning-augmented streaming algorithms in the context of frequency estimation. A fundamental problem in the streaming literature, the goal of frequency estimation is to approximate the number of occurrences of items appearing in a long stream of data using only a small amount of memory. Hsu et al. develop a natural framework to combine the worst-case guarantees of popular solutions such as CountMin and CountSketch with learned predictions of high frequency elements. They demonstrate that learning the underlying structure of data can be used to yield better streaming algorithms, both in theory and practice. We simplify and generalize past work on learning-augmented frequency estimation. Our first contribution is a learning-augmented variant of the Misra-Gries algorithm which improves upon the error of learned CountMin and learned CountSketch and achieves the state-of-the-art performance of randomized algorithms (Aamand et al., NeurIPS'23) with a simpler, deterministic algorithm. Our second contribution is to adapt learning-augmentation to a high-dimensional generalization of frequency estimation corresponding to finding important directions (top singular vectors) of a matrix given its rows one-by-one in a stream. We analyze a learning-augmented variant of the Frequent Directions algorithm, extending the theoretical and empirical understanding of learned predictions to matrix streaming.
Beyond Worst-Case Dimensionality Reduction for Sparse Vectors
Feb 27, 2025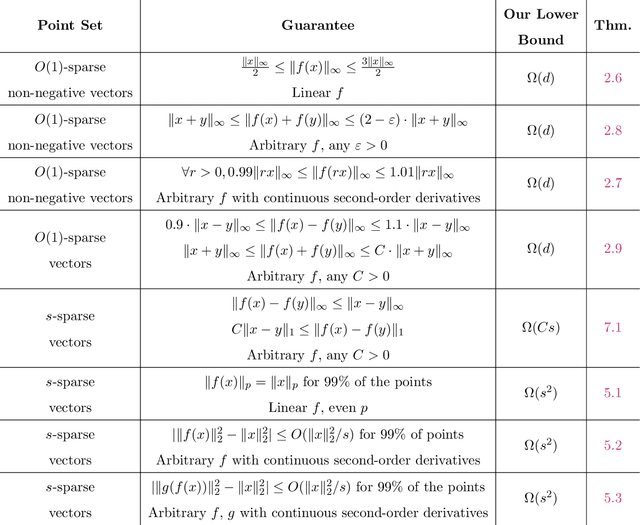
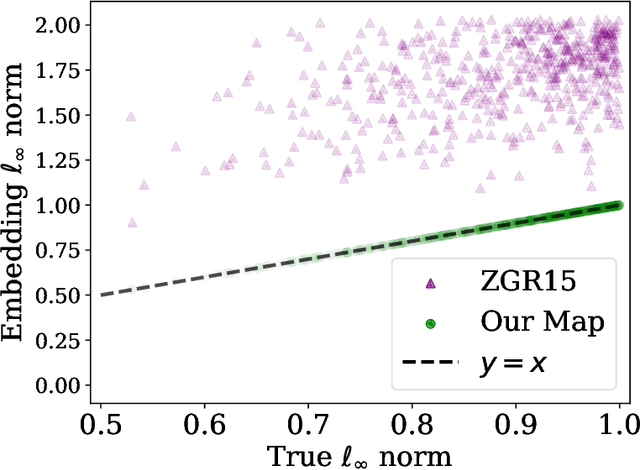
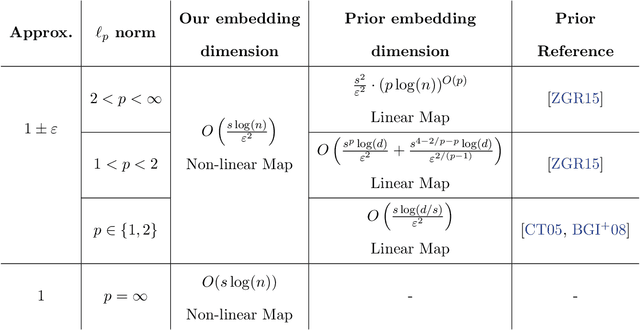
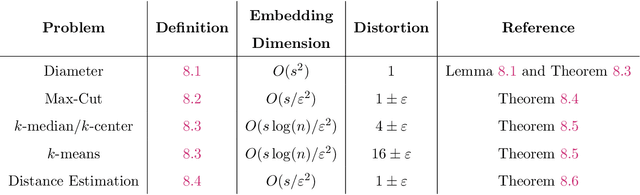
We study beyond worst-case dimensionality reduction for $s$-sparse vectors. Our work is divided into two parts, each focusing on a different facet of beyond worst-case analysis: We first consider average-case guarantees. A folklore upper bound based on the birthday-paradox states: For any collection $X$ of $s$-sparse vectors in $\mathbb{R}^d$, there exists a linear map to $\mathbb{R}^{O(s^2)}$ which \emph{exactly} preserves the norm of $99\%$ of the vectors in $X$ in any $\ell_p$ norm (as opposed to the usual setting where guarantees hold for all vectors). We give lower bounds showing that this is indeed optimal in many settings: any oblivious linear map satisfying similar average-case guarantees must map to $\Omega(s^2)$ dimensions. The same lower bound also holds for a wide class of smooth maps, including `encoder-decoder schemes', where we compare the norm of the original vector to that of a smooth function of the embedding. These lower bounds reveal a separation result, as an upper bound of $O(s \log(d))$ is possible if we instead use arbitrary (possibly non-smooth) functions, e.g., via compressed sensing algorithms. Given these lower bounds, we specialize to sparse \emph{non-negative} vectors. For a dataset $X$ of non-negative $s$-sparse vectors and any $p \ge 1$, we can non-linearly embed $X$ to $O(s\log(|X|s)/\epsilon^2)$ dimensions while preserving all pairwise distances in $\ell_p$ norm up to $1\pm \epsilon$, with no dependence on $p$. Surprisingly, the non-negativity assumption enables much smaller embeddings than arbitrary sparse vectors, where the best known bounds suffer exponential dependence. Our map also guarantees \emph{exact} dimensionality reduction for $\ell_{\infty}$ by embedding into $O(s\log |X|)$ dimensions, which is tight. We show that both the non-linearity of $f$ and the non-negativity of $X$ are necessary, and provide downstream algorithmic improvements.
Optimal Algorithms for Augmented Testing of Discrete Distributions
Dec 01, 2024



We consider the problem of hypothesis testing for discrete distributions. In the standard model, where we have sample access to an underlying distribution $p$, extensive research has established optimal bounds for uniformity testing, identity testing (goodness of fit), and closeness testing (equivalence or two-sample testing). We explore these problems in a setting where a predicted data distribution, possibly derived from historical data or predictive machine learning models, is available. We demonstrate that such a predictor can indeed reduce the number of samples required for all three property testing tasks. The reduction in sample complexity depends directly on the predictor's quality, measured by its total variation distance from $p$. A key advantage of our algorithms is their adaptability to the precision of the prediction. Specifically, our algorithms can self-adjust their sample complexity based on the accuracy of the available prediction, operating without any prior knowledge of the estimation's accuracy (i.e. they are consistent). Additionally, we never use more samples than the standard approaches require, even if the predictions provide no meaningful information (i.e. they are also robust). We provide lower bounds to indicate that the improvements in sample complexity achieved by our algorithms are information-theoretically optimal. Furthermore, experimental results show that the performance of our algorithms on real data significantly exceeds our worst-case guarantees for sample complexity, demonstrating the practicality of our approach.
Statistical-Computational Trade-offs for Density Estimation
Oct 30, 2024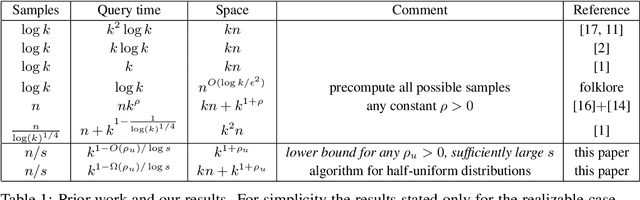
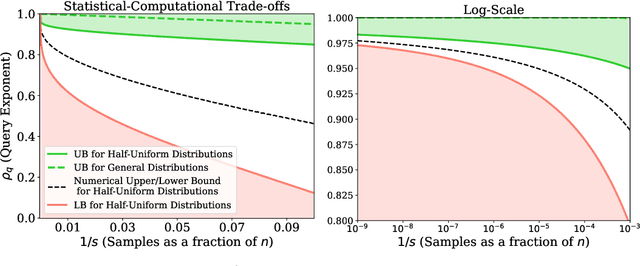
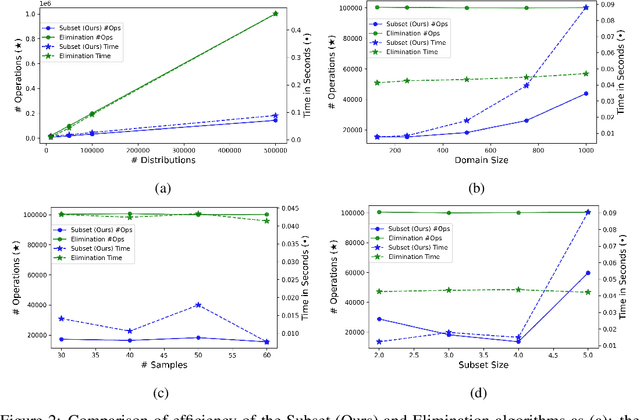
We study the density estimation problem defined as follows: given $k$ distributions $p_1, \ldots, p_k$ over a discrete domain $[n]$, as well as a collection of samples chosen from a ``query'' distribution $q$ over $[n]$, output $p_i$ that is ``close'' to $q$. Recently~\cite{aamand2023data} gave the first and only known result that achieves sublinear bounds in {\em both} the sampling complexity and the query time while preserving polynomial data structure space. However, their improvement over linear samples and time is only by subpolynomial factors. Our main result is a lower bound showing that, for a broad class of data structures, their bounds cannot be significantly improved. In particular, if an algorithm uses $O(n/\log^c k)$ samples for some constant $c>0$ and polynomial space, then the query time of the data structure must be at least $k^{1-O(1)/\log \log k}$, i.e., close to linear in the number of distributions $k$. This is a novel \emph{statistical-computational} trade-off for density estimation, demonstrating that any data structure must use close to a linear number of samples or take close to linear query time. The lower bound holds even in the realizable case where $q=p_i$ for some $i$, and when the distributions are flat (specifically, all distributions are uniform over half of the domain $[n]$). We also give a simple data structure for our lower bound instance with asymptotically matching upper bounds. Experiments show that the data structure is quite efficient in practice.
A Bi-metric Framework for Fast Similarity Search
Jun 05, 2024We propose a new "bi-metric" framework for designing nearest neighbor data structures. Our framework assumes two dissimilarity functions: a ground-truth metric that is accurate but expensive to compute, and a proxy metric that is cheaper but less accurate. In both theory and practice, we show how to construct data structures using only the proxy metric such that the query procedure achieves the accuracy of the expensive metric, while only using a limited number of calls to both metrics. Our theoretical results instantiate this framework for two popular nearest neighbor search algorithms: DiskANN and Cover Tree. In both cases we show that, as long as the proxy metric used to construct the data structure approximates the ground-truth metric up to a bounded factor, our data structure achieves arbitrarily good approximation guarantees with respect to the ground-truth metric. On the empirical side, we apply the framework to the text retrieval problem with two dissimilarity functions evaluated by ML models with vastly different computational costs. We observe that for almost all data sets in the MTEB benchmark, our approach achieves a considerably better accuracy-efficiency tradeoff than the alternatives, such as re-ranking.
Efficiently Computing Similarities to Private Datasets
Mar 13, 2024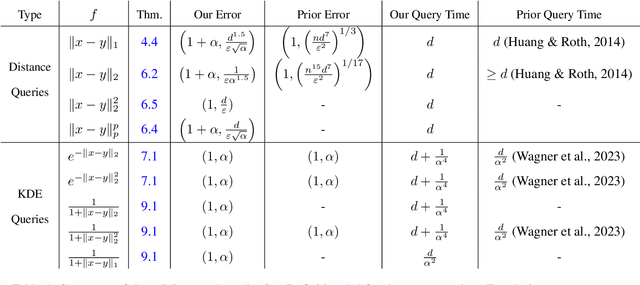
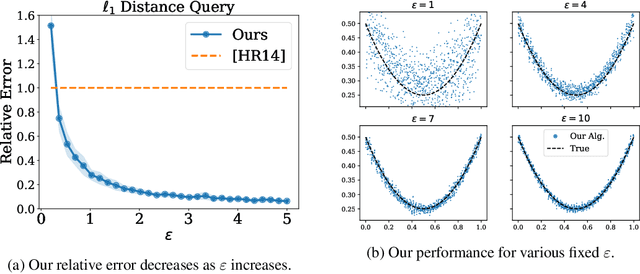

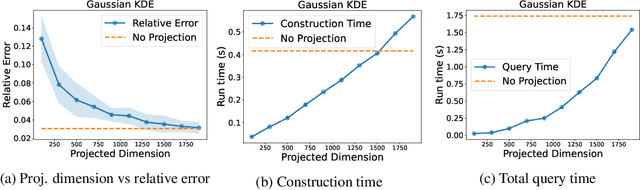
Many methods in differentially private model training rely on computing the similarity between a query point (such as public or synthetic data) and private data. We abstract out this common subroutine and study the following fundamental algorithmic problem: Given a similarity function $f$ and a large high-dimensional private dataset $X \subset \mathbb{R}^d$, output a differentially private (DP) data structure which approximates $\sum_{x \in X} f(x,y)$ for any query $y$. We consider the cases where $f$ is a kernel function, such as $f(x,y) = e^{-\|x-y\|_2^2/\sigma^2}$ (also known as DP kernel density estimation), or a distance function such as $f(x,y) = \|x-y\|_2$, among others. Our theoretical results improve upon prior work and give better privacy-utility trade-offs as well as faster query times for a wide range of kernels and distance functions. The unifying approach behind our results is leveraging `low-dimensional structures' present in the specific functions $f$ that we study, using tools such as provable dimensionality reduction, approximation theory, and one-dimensional decomposition of the functions. Our algorithms empirically exhibit improved query times and accuracy over prior state of the art. We also present an application to DP classification. Our experiments demonstrate that the simple methodology of classifying based on average similarity is orders of magnitude faster than prior DP-SGD based approaches for comparable accuracy.
Improved Frequency Estimation Algorithms with and without Predictions
Dec 12, 2023



Estimating frequencies of elements appearing in a data stream is a key task in large-scale data analysis. Popular sketching approaches to this problem (e.g., CountMin and CountSketch) come with worst-case guarantees that probabilistically bound the error of the estimated frequencies for any possible input. The work of Hsu et al. (2019) introduced the idea of using machine learning to tailor sketching algorithms to the specific data distribution they are being run on. In particular, their learning-augmented frequency estimation algorithm uses a learned heavy-hitter oracle which predicts which elements will appear many times in the stream. We give a novel algorithm, which in some parameter regimes, already theoretically outperforms the learning based algorithm of Hsu et al. without the use of any predictions. Augmenting our algorithm with heavy-hitter predictions further reduces the error and improves upon the state of the art. Empirically, our algorithms achieve superior performance in all experiments compared to prior approaches.