 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuessing Efficiently for Constrained Subspace Approximation
Apr 29, 2025In this paper we study constrained subspace approximation problem. Given a set of $n$ points $\{a_1,\ldots,a_n\}$ in $\mathbb{R}^d$, the goal of the {\em subspace approximation} problem is to find a $k$ dimensional subspace that best approximates the input points. More precisely, for a given $p\geq 1$, we aim to minimize the $p$th power of the $\ell_p$ norm of the error vector $(\|a_1-\bm{P}a_1\|,\ldots,\|a_n-\bm{P}a_n\|)$, where $\bm{P}$ denotes the projection matrix onto the subspace and the norms are Euclidean. In \emph{constrained} subspace approximation (CSA), we additionally have constraints on the projection matrix $\bm{P}$. In its most general form, we require $\bm{P}$ to belong to a given subset $\mathcal{S}$ that is described explicitly or implicitly. We introduce a general framework for constrained subspace approximation. Our approach, that we term coreset-guess-solve, yields either $(1+\varepsilon)$-multiplicative or $\varepsilon$-additive approximations for a variety of constraints. We show that it provides new algorithms for partition-constrained subspace approximation with applications to {\it fair} subspace approximation, $k$-means clustering, and projected non-negative matrix factorization, among others. Specifically, while we reconstruct the best known bounds for $k$-means clustering in Euclidean spaces, we improve the known results for the remainder of the problems.
Efficiently Computing Similarities to Private Datasets
Mar 13, 2024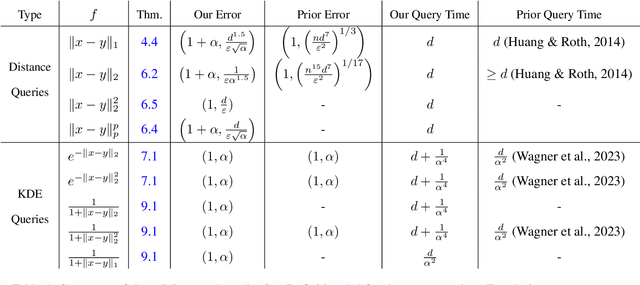
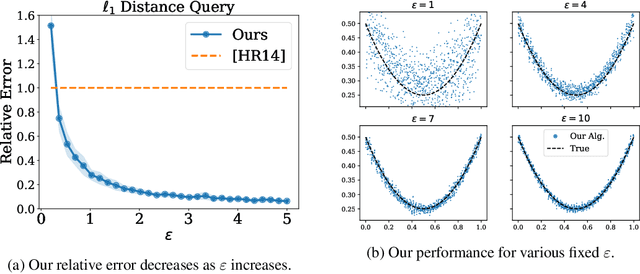

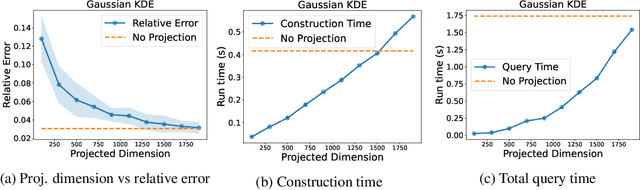
Many methods in differentially private model training rely on computing the similarity between a query point (such as public or synthetic data) and private data. We abstract out this common subroutine and study the following fundamental algorithmic problem: Given a similarity function $f$ and a large high-dimensional private dataset $X \subset \mathbb{R}^d$, output a differentially private (DP) data structure which approximates $\sum_{x \in X} f(x,y)$ for any query $y$. We consider the cases where $f$ is a kernel function, such as $f(x,y) = e^{-\|x-y\|_2^2/\sigma^2}$ (also known as DP kernel density estimation), or a distance function such as $f(x,y) = \|x-y\|_2$, among others. Our theoretical results improve upon prior work and give better privacy-utility trade-offs as well as faster query times for a wide range of kernels and distance functions. The unifying approach behind our results is leveraging `low-dimensional structures' present in the specific functions $f$ that we study, using tools such as provable dimensionality reduction, approximation theory, and one-dimensional decomposition of the functions. Our algorithms empirically exhibit improved query times and accuracy over prior state of the art. We also present an application to DP classification. Our experiments demonstrate that the simple methodology of classifying based on average similarity is orders of magnitude faster than prior DP-SGD based approaches for comparable accuracy.
Core-sets for Fair and Diverse Data Summarization
Oct 12, 2023



We study core-set construction algorithms for the task of Diversity Maximization under fairness/partition constraint. Given a set of points $P$ in a metric space partitioned into $m$ groups, and given $k_1,\ldots,k_m$, the goal of this problem is to pick $k_i$ points from each group $i$ such that the overall diversity of the $k=\sum_i k_i$ picked points is maximized. We consider two natural diversity measures: sum-of-pairwise distances and sum-of-nearest-neighbor distances, and show improved core-set construction algorithms with respect to these measures. More precisely, we show the first constant factor core-set w.r.t. sum-of-pairwise distances whose size is independent of the size of the dataset and the aspect ratio. Second, we show the first core-set w.r.t. the sum-of-nearest-neighbor distances. Finally, we run several experiments showing the effectiveness of our core-set approach. In particular, we apply constrained diversity maximization to summarize a set of timed messages that takes into account the messages' recency. Specifically, the summary should include more recent messages compared to older ones. This is a real task in one of the largest communication platforms, affecting the experience of hundreds of millions daily active users. By utilizing our core-set method for this task, we achieve a 100x speed-up while losing the diversity by only a few percent. Moreover, our approach allows us to improve the space usage of the algorithm in the streaming setting.
Tight Bounds for Volumetric Spanners and Applications
Sep 29, 2023
Given a set of points of interest, a volumetric spanner is a subset of the points using which all the points can be expressed using "small" coefficients (measured in an appropriate norm). Formally, given a set of vectors $X = \{v_1, v_2, \dots, v_n\}$, the goal is to find $T \subseteq [n]$ such that every $v \in X$ can be expressed as $\sum_{i\in T} \alpha_i v_i$, with $\|\alpha\|$ being small. This notion, which has also been referred to as a well-conditioned basis, has found several applications, including bandit linear optimization, determinant maximization, and matrix low rank approximation. In this paper, we give almost optimal bounds on the size of volumetric spanners for all $\ell_p$ norms, and show that they can be constructed using a simple local search procedure. We then show the applications of our result to other tasks and in particular the problem of finding coresets for the Minimum Volume Enclosing Ellipsoid (MVEE) problem.
Composable Coresets for Determinant Maximization: Greedy is Almost Optimal
Sep 26, 2023Given a set of $n$ vectors in $\mathbb{R}^d$, the goal of the \emph{determinant maximization} problem is to pick $k$ vectors with the maximum volume. Determinant maximization is the MAP-inference task for determinantal point processes (DPP) and has recently received considerable attention for modeling diversity. As most applications for the problem use large amounts of data, this problem has been studied in the relevant \textit{composable coreset} setting. In particular, [Indyk-Mahabadi-OveisGharan-Rezaei--SODA'20, ICML'19] showed that one can get composable coresets with optimal approximation factor of $\tilde O(k)^k$ for the problem, and that a local search algorithm achieves an almost optimal approximation guarantee of $O(k)^{2k}$. In this work, we show that the widely-used Greedy algorithm also provides composable coresets with an almost optimal approximation factor of $O(k)^{3k}$, which improves over the previously known guarantee of $C^{k^2}$, and supports the prior experimental results showing the practicality of the greedy algorithm as a coreset. Our main result follows by showing a local optimality property for Greedy: swapping a single point from the greedy solution with a vector that was not picked by the greedy algorithm can increase the volume by a factor of at most $(1+\sqrt{k})$. This is tight up to the additive constant $1$. Finally, our experiments show that the local optimality of the greedy algorithm is even lower than the theoretical bound on real data sets.
Approximation Algorithms for Fair Range Clustering
Jun 22, 2023

This paper studies the fair range clustering problem in which the data points are from different demographic groups and the goal is to pick $k$ centers with the minimum clustering cost such that each group is at least minimally represented in the centers set and no group dominates the centers set. More precisely, given a set of $n$ points in a metric space $(P,d)$ where each point belongs to one of the $\ell$ different demographics (i.e., $P = P_1 \uplus P_2 \uplus \cdots \uplus P_\ell$) and a set of $\ell$ intervals $[\alpha_1, \beta_1], \cdots, [\alpha_\ell, \beta_\ell]$ on desired number of centers from each group, the goal is to pick a set of $k$ centers $C$ with minimum $\ell_p$-clustering cost (i.e., $(\sum_{v\in P} d(v,C)^p)^{1/p}$) such that for each group $i\in \ell$, $|C\cap P_i| \in [\alpha_i, \beta_i]$. In particular, the fair range $\ell_p$-clustering captures fair range $k$-center, $k$-median and $k$-means as its special cases. In this work, we provide efficient constant factor approximation algorithms for fair range $\ell_p$-clustering for all values of $p\in [1,\infty)$.
Adaptive Sketches for Robust Regression with Importance Sampling
Jul 16, 2022
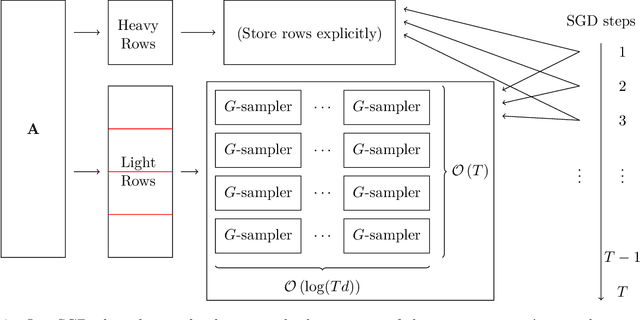
We introduce data structures for solving robust regression through stochastic gradient descent (SGD) by sampling gradients with probability proportional to their norm, i.e., importance sampling. Although SGD is widely used for large scale machine learning, it is well-known for possibly experiencing slow convergence rates due to the high variance from uniform sampling. On the other hand, importance sampling can significantly decrease the variance but is usually difficult to implement because computing the sampling probabilities requires additional passes over the data, in which case standard gradient descent (GD) could be used instead. In this paper, we introduce an algorithm that approximately samples $T$ gradients of dimension $d$ from nearly the optimal importance sampling distribution for a robust regression problem over $n$ rows. Thus our algorithm effectively runs $T$ steps of SGD with importance sampling while using sublinear space and just making a single pass over the data. Our techniques also extend to performing importance sampling for second-order optimization.
Sampling a Near Neighbor in High Dimensions -- Who is the Fairest of Them All?
Jan 26, 2021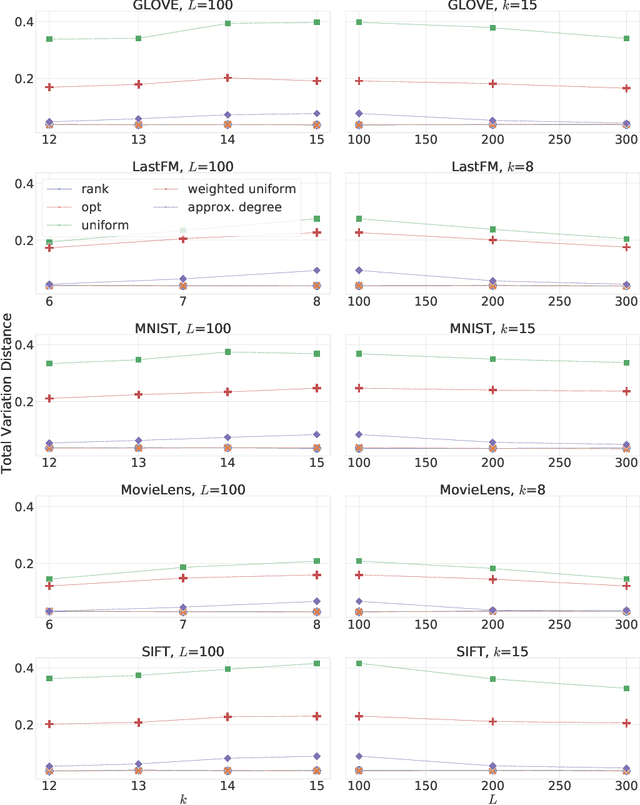
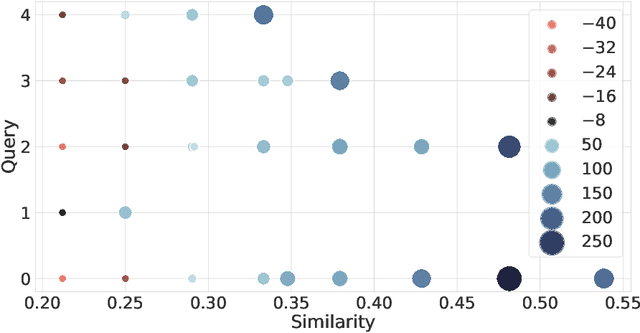
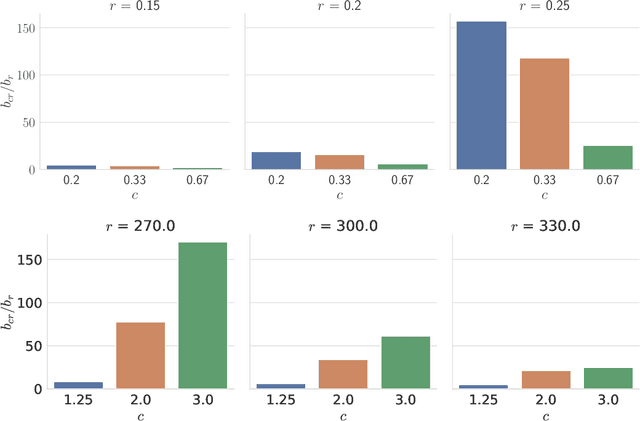
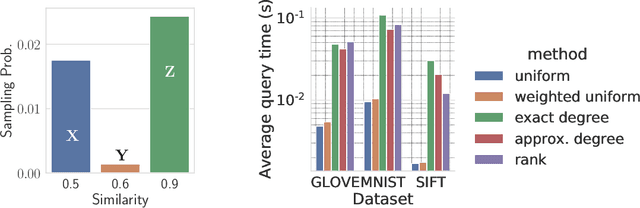
Similarity search is a fundamental algorithmic primitive, widely used in many computer science disciplines. Given a set of points $S$ and a radius parameter $r>0$, the $r$-near neighbor ($r$-NN) problem asks for a data structure that, given any query point $q$, returns a point $p$ within distance at most $r$ from $q$. In this paper, we study the $r$-NN problem in the light of individual fairness and providing equal opportunities: all points that are within distance $r$ from the query should have the same probability to be returned. In the low-dimensional case, this problem was first studied by Hu, Qiao, and Tao (PODS 2014). Locality sensitive hashing (LSH), the theoretically strongest approach to similarity search in high dimensions, does not provide such a fairness guarantee. In this work, we show that LSH based algorithms can be made fair, without a significant loss in efficiency. We propose several efficient data structures for the exact and approximate variants of the fair NN problem. Our approach works more generally for sampling uniformly from a sub-collection of sets of a given collection and can be used in a few other applications. We also develop a data structure for fair similarity search under inner product that requires nearly-linear space and exploits locality sensitive filters. The paper concludes with an experimental evaluation that highlights the inherent unfairness of NN data structures and shows the performance of our algorithms on real-world datasets.
Streaming Complexity of SVMs
Jul 07, 2020We study the space complexity of solving the bias-regularized SVM problem in the streaming model. This is a classic supervised learning problem that has drawn lots of attention, including for developing fast algorithms for solving the problem approximately. One of the most widely used algorithms for approximately optimizing the SVM objective is Stochastic Gradient Descent (SGD), which requires only $O(\frac{1}{\lambda\epsilon})$ random samples, and which immediately yields a streaming algorithm that uses $O(\frac{d}{\lambda\epsilon})$ space. For related problems, better streaming algorithms are only known for smooth functions, unlike the SVM objective that we focus on in this work. We initiate an investigation of the space complexity for both finding an approximate optimum of this objective, and for the related ``point estimation'' problem of sketching the data set to evaluate the function value $F_\lambda$ on any query $(\theta, b)$. We show that, for both problems, for dimensions $d=1,2$, one can obtain streaming algorithms with space polynomially smaller than $\frac{1}{\lambda\epsilon}$, which is the complexity of SGD for strongly convex functions like the bias-regularized SVM, and which is known to be tight in general, even for $d=1$. We also prove polynomial lower bounds for both point estimation and optimization. In particular, for point estimation we obtain a tight bound of $\Theta(1/\sqrt{\epsilon})$ for $d=1$ and a nearly tight lower bound of $\widetilde{\Omega}(d/{\epsilon}^2)$ for $d = \Omega( \log(1/\epsilon))$. Finally, for optimization, we prove a $\Omega(1/\sqrt{\epsilon})$ lower bound for $d = \Omega( \log(1/\epsilon))$, and show similar bounds when $d$ is constant.
Non-Adaptive Adaptive Sampling on Turnstile Streams
Apr 23, 2020
Adaptive sampling is a useful algorithmic tool for data summarization problems in the classical centralized setting, where the entire dataset is available to the single processor performing the computation. Adaptive sampling repeatedly selects rows of an underlying matrix $\mathbf{A}\in\mathbb{R}^{n\times d}$, where $n\gg d$, with probabilities proportional to their distances to the subspace of the previously selected rows. Intuitively, adaptive sampling seems to be limited to trivial multi-pass algorithms in the streaming model of computation due to its inherently sequential nature of assigning sampling probabilities to each row only after the previous iteration is completed. Surprisingly, we show this is not the case by giving the first one-pass algorithms for adaptive sampling on turnstile streams and using space $\text{poly}(d,k,\log n)$, where $k$ is the number of adaptive sampling rounds to be performed. Our adaptive sampling procedure has a number of applications to various data summarization problems that either improve state-of-the-art or have only been previously studied in the more relaxed row-arrival model. We give the first relative-error algorithms for column subset selection, subspace approximation, projective clustering, and volume maximization on turnstile streams that use space sublinear in $n$. We complement our volume maximization algorithmic results with lower bounds that are tight up to lower order terms, even for multi-pass algorithms. By a similar construction, we also obtain lower bounds for volume maximization in the row-arrival model, which we match with competitive upper bounds. See paper for full abstract.