 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Approximations for Hard Graph Problems using Predictions
May 29, 2025

We design improved approximation algorithms for NP-hard graph problems by incorporating predictions (e.g., learned from past data). Our prediction model builds upon and extends the $\varepsilon$-prediction framework by Cohen-Addad, d'Orsi, Gupta, Lee, and Panigrahi (NeurIPS 2024). We consider an edge-based version of this model, where each edge provides two bits of information, corresponding to predictions about whether each of its endpoints belong to an optimal solution. Even with weak predictions where each bit is only $\varepsilon$-correlated with the true solution, this information allows us to break approximation barriers in the standard setting. We develop algorithms with improved approximation ratios for MaxCut, Vertex Cover, Set Cover, and Maximum Independent Set problems (among others). Across these problems, our algorithms share a unifying theme, where we separately satisfy constraints related to high degree vertices (using predictions) and low-degree vertices (without using predictions) and carefully combine the answers.
Learning-Augmented Frequent Directions
Mar 02, 2025
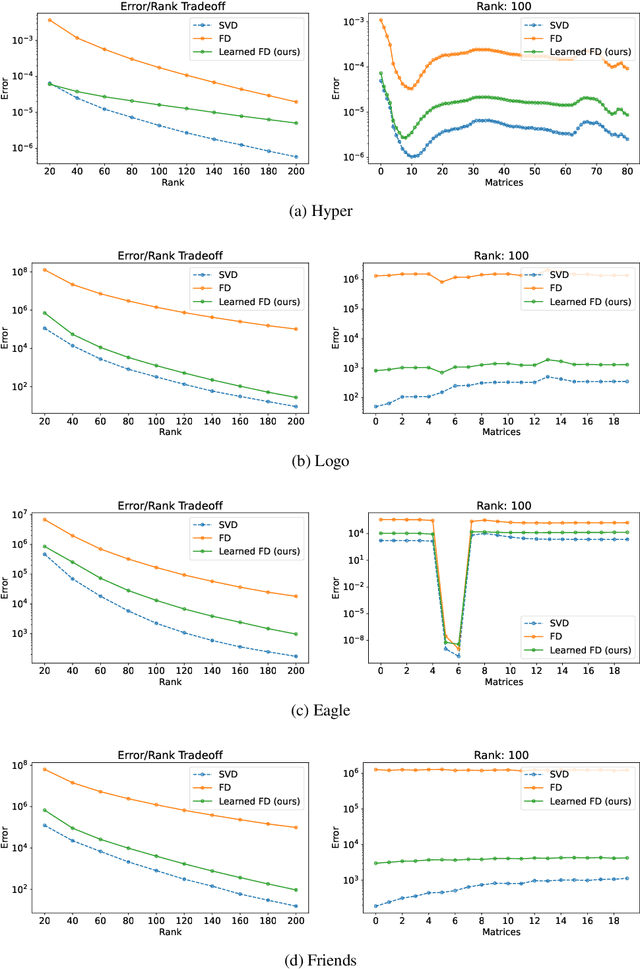
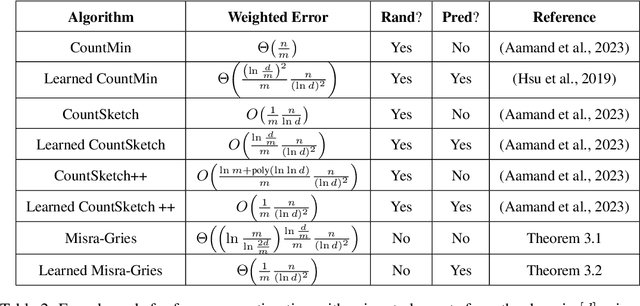
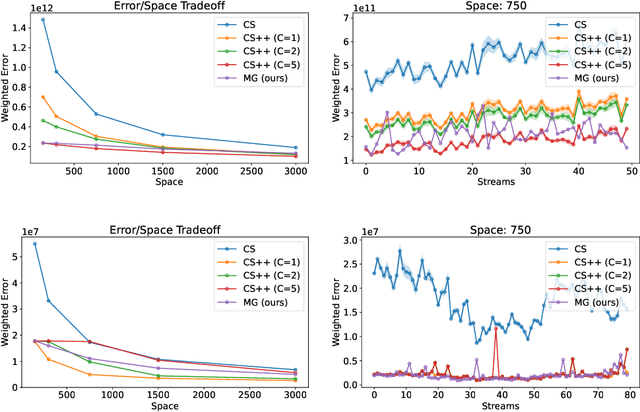
An influential paper of Hsu et al. (ICLR'19) introduced the study of learning-augmented streaming algorithms in the context of frequency estimation. A fundamental problem in the streaming literature, the goal of frequency estimation is to approximate the number of occurrences of items appearing in a long stream of data using only a small amount of memory. Hsu et al. develop a natural framework to combine the worst-case guarantees of popular solutions such as CountMin and CountSketch with learned predictions of high frequency elements. They demonstrate that learning the underlying structure of data can be used to yield better streaming algorithms, both in theory and practice. We simplify and generalize past work on learning-augmented frequency estimation. Our first contribution is a learning-augmented variant of the Misra-Gries algorithm which improves upon the error of learned CountMin and learned CountSketch and achieves the state-of-the-art performance of randomized algorithms (Aamand et al., NeurIPS'23) with a simpler, deterministic algorithm. Our second contribution is to adapt learning-augmentation to a high-dimensional generalization of frequency estimation corresponding to finding important directions (top singular vectors) of a matrix given its rows one-by-one in a stream. We analyze a learning-augmented variant of the Frequent Directions algorithm, extending the theoretical and empirical understanding of learned predictions to matrix streaming.
Composable Coresets for Determinant Maximization: Greedy is Almost Optimal
Sep 26, 2023Given a set of $n$ vectors in $\mathbb{R}^d$, the goal of the \emph{determinant maximization} problem is to pick $k$ vectors with the maximum volume. Determinant maximization is the MAP-inference task for determinantal point processes (DPP) and has recently received considerable attention for modeling diversity. As most applications for the problem use large amounts of data, this problem has been studied in the relevant \textit{composable coreset} setting. In particular, [Indyk-Mahabadi-OveisGharan-Rezaei--SODA'20, ICML'19] showed that one can get composable coresets with optimal approximation factor of $\tilde O(k)^k$ for the problem, and that a local search algorithm achieves an almost optimal approximation guarantee of $O(k)^{2k}$. In this work, we show that the widely-used Greedy algorithm also provides composable coresets with an almost optimal approximation factor of $O(k)^{3k}$, which improves over the previously known guarantee of $C^{k^2}$, and supports the prior experimental results showing the practicality of the greedy algorithm as a coreset. Our main result follows by showing a local optimality property for Greedy: swapping a single point from the greedy solution with a vector that was not picked by the greedy algorithm can increase the volume by a factor of at most $(1+\sqrt{k})$. This is tight up to the additive constant $1$. Finally, our experiments show that the local optimality of the greedy algorithm is even lower than the theoretical bound on real data sets.