 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Certificates of Anti-Concentration Beyond Gaussians
May 23, 2024A set of high dimensional points $X=\{x_1, x_2,\ldots, x_n\} \subset R^d$ in isotropic position is said to be $\delta$-anti concentrated if for every direction $v$, the fraction of points in $X$ satisfying $|\langle x_i,v \rangle |\leq \delta$ is at most $O(\delta)$. Motivated by applications to list-decodable learning and clustering, recent works have considered the problem of constructing efficient certificates of anti-concentration in the average case, when the set of points $X$ corresponds to samples from a Gaussian distribution. Their certificates played a crucial role in several subsequent works in algorithmic robust statistics on list-decodable learning and settling the robust learnability of arbitrary Gaussian mixtures, yet remain limited to rotationally invariant distributions. This work presents a new (and arguably the most natural) formulation for anti-concentration. Using this formulation, we give quasi-polynomial time verifiable sum-of-squares certificates of anti-concentration that hold for a wide class of non-Gaussian distributions including anti-concentrated bounded product distributions and uniform distributions over $L_p$ balls (and their affine transformations). Consequently, our method upgrades and extends results in algorithmic robust statistics e.g., list-decodable learning and clustering, to such distributions. Our approach constructs a canonical integer program for anti-concentration and analysis a sum-of-squares relaxation of it, independent of the intended application. We rely on duality and analyze a pseudo-expectation on large subsets of the input points that take a small value in some direction. Our analysis uses the method of polynomial reweightings to reduce the problem to analyzing only analytically dense or sparse directions.
Concentration of polynomial random matrices via Efron-Stein inequalities
Sep 06, 2022
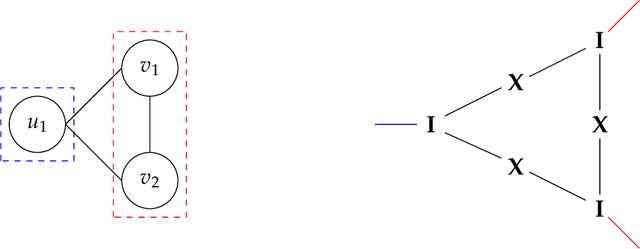
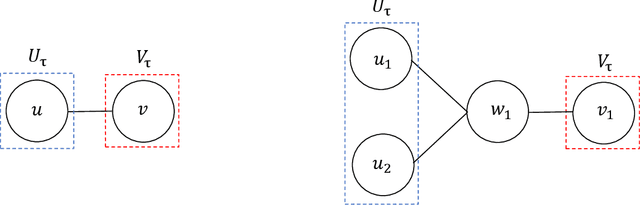

Analyzing concentration of large random matrices is a common task in a wide variety of fields. Given independent random variables, many tools are available to analyze random matrices whose entries are linear in the variables, e.g. the matrix-Bernstein inequality. However, in many applications, we need to analyze random matrices whose entries are polynomials in the variables. These arise naturally in the analysis of spectral algorithms, e.g., Hopkins et al. [STOC 2016], Moitra-Wein [STOC 2019]; and in lower bounds for semidefinite programs based on the Sum of Squares hierarchy, e.g. Barak et al. [FOCS 2016], Jones et al. [FOCS 2021]. In this work, we present a general framework to obtain such bounds, based on the matrix Efron-Stein inequalities developed by Paulin-Mackey-Tropp [Annals of Probability 2016]. The Efron-Stein inequality bounds the norm of a random matrix by the norm of another simpler (but still random) matrix, which we view as arising by "differentiating" the starting matrix. By recursively differentiating, our framework reduces the main task to analyzing far simpler matrices. For Rademacher variables, these simpler matrices are in fact deterministic and hence, analyzing them is far easier. For general non-Rademacher variables, the task reduces to scalar concentration, which is much easier. Moreover, in the setting of polynomial matrices, our results generalize the work of Paulin-Mackey-Tropp. Using our basic framework, we recover known bounds in the literature for simple "tensor networks" and "dense graph matrices". Using our general framework, we derive bounds for "sparse graph matrices", which were obtained only recently by Jones et al. [FOCS 2021] using a nontrivial application of the trace power method, and was a core component in their work. We expect our framework to be helpful for other applications involving concentration phenomena for nonlinear random matrices.