 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversality of first-order methods on random and deterministic matrices
Apr 13, 2026General first-order methods (GFOM) are a flexible class of iterative algorithms which update a state vector by matrix-vector multiplications and entrywise nonlinearities. A long line of work has sought to understand the large-n dynamics of GFOM, mostly focusing on "very random" input matrices and the approximate message passing (AMP) special case of GFOM whose state is asymptotically Gaussian. Yet, it has long remained unknown how to construct iterative algorithms that retain this Gaussianity for more structured inputs, or why existing AMP algorithms can be as effective for some deterministic matrices as they are for random matrices. We analyze diagrammatic expansions of GFOM via the limiting traffic distribution of the input matrix, the collection of all limiting values of permutation-invariant polynomials in the matrix entries, to obtain the following results: 1. We calculate the traffic distribution for the first non-trivial deterministic matrices, including (minor variants of) the Walsh-Hadamard and discrete sine and cosine transform matrices. This determines the limiting dynamics of GFOM on these inputs, resolving parts of longstanding conjectures of Marinari, Parisi, and Ritort (1994). 2. We design a new AMP iteration which unifies several previous AMP variants and generalizes to new input types, whose limiting dynamics are Gaussian conditional on some latent random variables. The asymptotic dynamics hold for a large and natural class of traffic distributions (encompassing both random and deterministic input matrices) and the algorithm's analysis gives a simple combinatorial interpretation of the Onsager correction, answering questions posed recently by Wang, Zhong, and Fan (2022).
$μ$pscaling small models: Principled warm starts and hyperparameter transfer
Feb 11, 2026Modern large-scale neural networks are often trained and released in multiple sizes to accommodate diverse inference budgets. To improve efficiency, recent work has explored model upscaling: initializing larger models from trained smaller ones in order to transfer knowledge and accelerate convergence. However, this method can be sensitive to hyperparameters that need to be tuned at the target upscaled model size, which is prohibitively costly to do directly. It remains unclear whether the most common workaround -- tuning on smaller models and extrapolating via hyperparameter scaling laws -- is still sound when using upscaling. We address this with principled approaches to upscaling with respect to model widths and efficiently tuning hyperparameters in this setting. First, motivated by $μ$P and any-dimensional architectures, we introduce a general upscaling method applicable to a broad range of architectures and optimizers, backed by theory guaranteeing that models are equivalent to their widened versions and allowing for rigorous analysis of infinite-width limits. Second, we extend the theory of $μ$Transfer to a hyperparameter transfer technique for models upscaled using our method and empirically demonstrate that this method is effective on realistic datasets and architectures.
Nonlinear Laplacians: Tunable principal component analysis under directional prior information
May 18, 2025We introduce a new family of algorithms for detecting and estimating a rank-one signal from a noisy observation under prior information about that signal's direction, focusing on examples where the signal is known to have entries biased to be positive. Given a matrix observation $\mathbf{Y}$, our algorithms construct a nonlinear Laplacian, another matrix of the form $\mathbf{Y} + \mathrm{diag}(\sigma(\mathbf{Y}\mathbf{1}))$ for a nonlinear $\sigma: \mathbb{R} \to \mathbb{R}$, and examine the top eigenvalue and eigenvector of this matrix. When $\mathbf{Y}$ is the (suitably normalized) adjacency matrix of a graph, our approach gives a class of algorithms that search for unusually dense subgraphs by computing a spectrum of the graph "deformed" by the degree profile $\mathbf{Y}\mathbf{1}$. We study the performance of such algorithms compared to direct spectral algorithms (the case $\sigma = 0$) on models of sparse principal component analysis with biased signals, including the Gaussian planted submatrix problem. For such models, we rigorously characterize the critical threshold strength of rank-one signal, as a function of the nonlinearity $\sigma$, at which an outlier eigenvalue appears in the spectrum of a nonlinear Laplacian. While identifying the $\sigma$ that minimizes this critical signal strength in closed form seems intractable, we explore three approaches to design $\sigma$ numerically: exhaustively searching over simple classes of $\sigma$, learning $\sigma$ from datasets of problem instances, and tuning $\sigma$ using black-box optimization of the critical signal strength. We find both theoretically and empirically that, if $\sigma$ is chosen appropriately, then nonlinear Laplacian spectral algorithms substantially outperform direct spectral algorithms, while avoiding the complexity of broader classes of algorithms like approximate message passing or general first order methods.
Low coordinate degree algorithms II: Categorical signals and generalized stochastic block models
Dec 30, 2024We study when low coordinate degree functions (LCDF) -- linear combinations of functions depending on small subsets of entries of a vector -- can test for the presence of categorical structure, including community structure and generalizations thereof, in high-dimensional data. This complements the first paper of this series, which studied the power of LCDF in testing for continuous structure like real-valued signals perturbed by additive noise. We apply the tools developed there to a general form of stochastic block model (SBM), where a population is assigned random labels and every $p$-tuple of the population generates an observation according to an arbitrary probability measure associated to the $p$ labels of its members. We show that the performance of LCDF admits a unified analysis for this class of models. As applications, we prove tight lower bounds against LCDF (and therefore also against low degree polynomials) for nearly arbitrary graph and regular hypergraph SBMs, always matching suitable generalizations of the Kesten-Stigum threshold. We also prove tight lower bounds for group synchronization and abelian group sumset problems under the "truth-or-Haar" noise model, and use our technical results to give an improved analysis of Gaussian multi-frequency group synchronization. In most of these models, for some parameter settings our lower bounds give new evidence for conjectural statistical-to-computational gaps. Finally, interpreting some of our findings, we propose a precise analogy between categorical and continuous signals: a general SBM as above behaves, in terms of the tradeoff between subexponential runtime cost of testing algorithms and the signal strength needed for a testing algorithm to succeed, like a spiked $p_*$-tensor model of a certain order $p_*$ that may be computed from the parameters of the SBM.
Tensor cumulants for statistical inference on invariant distributions
Apr 29, 2024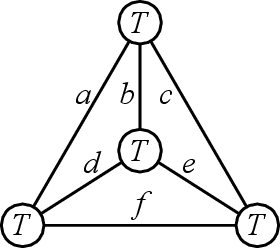
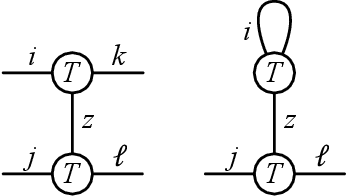

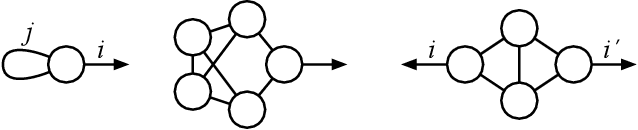
Many problems in high-dimensional statistics appear to have a statistical-computational gap: a range of values of the signal-to-noise ratio where inference is information-theoretically possible, but (conjecturally) computationally intractable. A canonical such problem is Tensor PCA, where we observe a tensor $Y$ consisting of a rank-one signal plus Gaussian noise. Multiple lines of work suggest that Tensor PCA becomes computationally hard at a critical value of the signal's magnitude. In particular, below this transition, no low-degree polynomial algorithm can detect the signal with high probability; conversely, various spectral algorithms are known to succeed above this transition. We unify and extend this work by considering tensor networks, orthogonally invariant polynomials where multiple copies of $Y$ are "contracted" to produce scalars, vectors, matrices, or other tensors. We define a new set of objects, tensor cumulants, which provide an explicit, near-orthogonal basis for invariant polynomials of a given degree. This basis lets us unify and strengthen previous results on low-degree hardness, giving a combinatorial explanation of the hardness transition and of a continuum of subexponential-time algorithms that work below it, and proving tight lower bounds against low-degree polynomials for recovering rather than just detecting the signal. It also lets us analyze a new problem of distinguishing between different tensor ensembles, such as Wigner and Wishart tensors, establishing a sharp computational threshold and giving evidence of a new statistical-computational gap in the Central Limit Theorem for random tensors. Finally, we believe these cumulants are valuable mathematical objects in their own right: they generalize the free cumulants of free probability theory from matrices to tensors, and share many of their properties, including additivity under additive free convolution.
Low coordinate degree algorithms I: Universality of computational thresholds for hypothesis testing
Mar 12, 2024We study when low coordinate degree functions (LCDF) -- linear combinations of functions depending on small subsets of entries of a vector -- can hypothesis test between high-dimensional probability measures. These functions are a generalization, proposed in Hopkins' 2018 thesis but seldom studied since, of low degree polynomials (LDP), a class widely used in recent literature as a proxy for all efficient algorithms for tasks in statistics and optimization. Instead of the orthogonal polynomial decompositions used in LDP calculations, our analysis of LCDF is based on the Efron-Stein or ANOVA decomposition, making it much more broadly applicable. By way of illustration, we prove channel universality for the success of LCDF in testing for the presence of sufficiently "dilute" random signals through noisy channels: the efficacy of LCDF depends on the channel only through the scalar Fisher information for a class of channels including nearly arbitrary additive i.i.d. noise and nearly arbitrary exponential families. As applications, we extend lower bounds against LDP for spiked matrix and tensor models under additive Gaussian noise to lower bounds against LCDF under general noisy channels. We also give a simple and unified treatment of the effect of censoring models by erasing observations at random and of quantizing models by taking the sign of the observations. These results are the first computational lower bounds against any large class of algorithms for all of these models when the channel is not one of a few special cases, and thereby give the first substantial evidence for the universality of several statistical-to-computational gaps.
The Average-Case Time Complexity of Certifying the Restricted Isometry Property
Jun 13, 2020In compressed sensing, the restricted isometry property (RIP) on $M \times N$ sensing matrices (where $M < N$) guarantees efficient reconstruction of sparse vectors. A matrix has the $(s,\delta)$-$\mathsf{RIP}$ property if behaves as a $\delta$-approximate isometry on $s$-sparse vectors. It is well known that an $M\times N$ matrix with i.i.d. $\mathcal{N}(0,1/M)$ entries is $(s,\delta)$-$\mathsf{RIP}$ with high probability as long as $s\lesssim \delta^2 M/\log N$. On the other hand, most prior works aiming to deterministically construct $(s,\delta)$-$\mathsf{RIP}$ matrices have failed when $s \gg \sqrt{M}$. An alternative way to find an RIP matrix could be to draw a random gaussian matrix and certify that it is indeed RIP. However, there is evidence that this certification task is computationally hard when $s \gg \sqrt{M}$, both in the worst case and the average case. In this paper, we investigate the exact average-case time complexity of certifying the RIP property for $M\times N$ matrices with i.i.d. $\mathcal{N}(0,1/M)$ entries, in the "possible but hard" regime $\sqrt{M} \ll s\lesssim M/\log N$, assuming that $M$ scales proportional to $N$. Based on analysis of the low-degree likelihood ratio, we give rigorous evidence that subexponential runtime $N^{\tilde\Omega(s^2/N)}$ is required, demonstrating a smooth tradeoff between the maximum tolerated sparsity and the required computational power. The lower bound is essentially tight, matching the runtime of an existing algorithm due to Koiran and Zouzias. Our hardness result allows $\delta$ to take any constant value in $(0,1)$, which captures the relevant regime for compressed sensing. This improves upon the existing average-case hardness result of Wang, Berthet, and Plan, which is limited to $\delta = o(1)$.
Notes on Computational Hardness of Hypothesis Testing: Predictions using the Low-Degree Likelihood Ratio
Jul 26, 2019These notes survey and explore an emerging method, which we call the low-degree method, for predicting and understanding statistical-versus-computational tradeoffs in high-dimensional inference problems. In short, the method posits that a certain quantity -- the second moment of the low-degree likelihood ratio -- gives insight into how much computational time is required to solve a given hypothesis testing problem, which can in turn be used to predict the computational hardness of a variety of statistical inference tasks. While this method originated in the study of the sum-of-squares (SoS) hierarchy of convex programs, we present a self-contained introduction that does not require knowledge of SoS. In addition to showing how to carry out predictions using the method, we include a discussion investigating both rigorous and conjectural consequences of these predictions. These notes include some new results, simplified proofs, and refined conjectures. For instance, we point out a formal connection between spectral methods and the low-degree likelihood ratio, and we give a sharp low-degree lower bound against subexponential-time algorithms for tensor PCA.
Subexponential-Time Algorithms for Sparse PCA
Jul 26, 2019We study the computational cost of recovering a unit-norm sparse principal component $x \in \mathbb{R}^n$ planted in a random matrix, in either the Wigner or Wishart spiked model (observing either $W + \lambda xx^\top$ with $W$ drawn from the Gaussian orthogonal ensemble, or $N$ independent samples from $\mathcal{N}(0, I_n + \beta xx^\top)$, respectively). Prior work has shown that when the signal-to-noise ratio ($\lambda$ or $\beta\sqrt{N/n}$, respectively) is a small constant and the fraction of nonzero entries in the planted vector is $\|x\|_0 / n = \rho$, it is possible to recover $x$ in polynomial time if $\rho \lesssim 1/\sqrt{n}$. While it is possible to recover $x$ in exponential time under the weaker condition $\rho \ll 1$, it is believed that polynomial-time recovery is impossible unless $\rho \lesssim 1/\sqrt{n}$. We investigate the precise amount of time required for recovery in the "possible but hard" regime $1/\sqrt{n} \ll \rho \ll 1$ by exploring the power of subexponential-time algorithms, i.e., algorithms running in time $\exp(n^\delta)$ for some constant $\delta \in (0,1)$. For any $1/\sqrt{n} \ll \rho \ll 1$, we give a recovery algorithm with runtime roughly $\exp(\rho^2 n)$, demonstrating a smooth tradeoff between sparsity and runtime. Our family of algorithms interpolates smoothly between two existing algorithms: the polynomial-time diagonal thresholding algorithm and the $\exp(\rho n)$-time exhaustive search algorithm. Furthermore, by analyzing the low-degree likelihood ratio, we give rigorous evidence suggesting that the tradeoff achieved by our algorithms is optimal.