 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting LLM Fact-conflicting Hallucinations Enhanced by Temporal-logic-based Reasoning
Feb 19, 2025



Large language models (LLMs) face the challenge of hallucinations -- outputs that seem coherent but are actually incorrect. A particularly damaging type is fact-conflicting hallucination (FCH), where generated content contradicts established facts. Addressing FCH presents three main challenges: 1) Automatically constructing and maintaining large-scale benchmark datasets is difficult and resource-intensive; 2) Generating complex and efficient test cases that the LLM has not been trained on -- especially those involving intricate temporal features -- is challenging, yet crucial for eliciting hallucinations; and 3) Validating the reasoning behind LLM outputs is inherently difficult, particularly with complex logical relationships, as it requires transparency in the model's decision-making process. This paper presents Drowzee, an innovative end-to-end metamorphic testing framework that utilizes temporal logic to identify fact-conflicting hallucinations (FCH) in large language models (LLMs). Drowzee builds a comprehensive factual knowledge base by crawling sources like Wikipedia and uses automated temporal-logic reasoning to convert this knowledge into a large, extensible set of test cases with ground truth answers. LLMs are tested using these cases through template-based prompts, which require them to generate both answers and reasoning steps. To validate the reasoning, we propose two semantic-aware oracles that compare the semantic structure of LLM outputs to the ground truths. Across nine LLMs in nine different knowledge domains, experimental results show that Drowzee effectively identifies rates of non-temporal-related hallucinations ranging from 24.7% to 59.8%, and rates of temporal-related hallucinations ranging from 16.7% to 39.2%.
Large Language Models for Cyber Security: A Systematic Literature Review
May 08, 2024
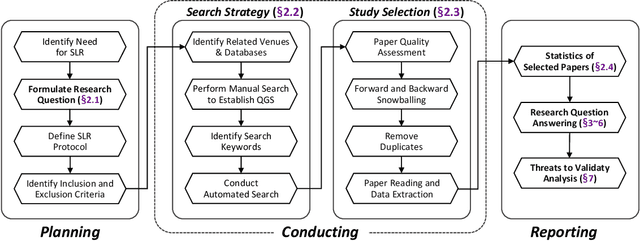


The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.